Chapter 19 연구단계
Chapter leads: Sara Dempster & Martijn Schuemie
이 장에서는 OHDSI 도구를 사용한 관찰 연구의 설계 및 구현에 대한 일반적인 단계별 가이드를 제공할 것이다. 연구 과정의 각 단계를 세분화하고, 단계를 일반적으로 설명하고, 어떤 경우에는 이 책의 앞장에서 설명한 다음과 같은 주요 연구 유형을 설명할 것이다: 1) 임상적 특성 분석 characterization 2) 인구 수준 추정 population level estimation(PLE) 3) 환자 수준 예측 patient level prediction(PLP). 이를 위해, 앞장에서 설명한 많은 요소를 초보자가 접근할 수 있는 방식으로 합성할 것이다. 동시에, 이 장은 필요에 따라 다른 장에서보다 심층적인 자료를 추구할 수 있는 옵션을 통해 실제적인 높은 수준의 설명을 원하는 독자에게 적합할 수 있다. 마지막으로, 몇 가지 주요 예를 통해 설명할 것이다.
또한, OHDSI 커뮤니티에서 권장하는 관찰 연구 지침과 모범 사례를 요약할 것이다. 여기서 논의할 일부 원칙은 일반적이고 다른 많은 관찰 연구 지침의 모범 사례 권장 사항과 일치되지만, 다른 권장 프로세스는 OHDSI 프레임워크에 더 적합하다. 따라서 OHDSI 도구 스택에서 OHDSI 관련 접근 방식을 사용할 수 있는 부분을 강조할 것이다.
독자가 OHDSI 도구, R 및 SQL 인프라를 활용할 수 있다는 가정하에, 이 장 전체에서 이러한 인프라 설정에 대해 논의는 하지 않는다 (설정 지침은 8장과 9장 참조). 또한 독자가 OMOP CDM 데이터베이스로 구축한 자체 사이트의 데이터를 활용하여 연구를 수행하는 데 관심이 있는 것으로 가정한다 (OMOP ETL의 경우 6장 참조). 그러나 연구 패키지가 아래에 논의된 대로 준비되면, 원칙적으로 다른 사이트에서 배포 및 실행될 수 있음을 강조한다. 조직 및 기술 세부 사항을 포함하여 OHDSI 네트워크 연구 실행에 대한 추가 고려 사항은 20장에서 자세히 설명한다.
19.1 일반 모범 사례 지침
19.1.1 관찰 연구 정의
관찰 연구는 환자를 단순히 관찰하고 특정 환자 치료에 개입하려는 시도가 없는 연구로 정의된다. 때로는 관찰 데이터가 레지스트리 연구에서와같이 특정 목적으로 수집되는 경우도 있지만, 대부분의 경우 이러한 데이터는 현재 특정 연구 질문 이외의 다른 목적으로 수집된다. 후자 데이터 유형의 일반적인 예로는 전자 의무 기록 Electronic Health Records(EHR) 또는 행정 청구 데이터 administrative claims data가 있다. 관찰 연구는 종종 데이터의 2차 사용이라고 불린다. 관찰 연구 수행을 위한 기본 지침 원칙은 연구 질문을 명시적으로 설명하고 연구 수행 전에 접근 방식을 완전히 지정하는 것이다. 이와 관련하여, 관찰 연구는 임상시험에서 일반적으로 치료 중재의 효능 및/또는 안전성에 관한 특정 질문에 답하기 위한 주된 목적으로 환자를 제시간에 모집하고 추적하는 것을 제외하고는 임상 시험과 다르지 않아야 한다. 관찰 연구에 사용된 분석 방법은 임상 시험에 사용된 분석 방법과 여러 면에서 다르다. 가장 주목할만한 점은, PLE 관찰 연구에서는 무작위 배정이 없어, 연구 목적이 인과적 추론을 도출하는 경우라면 혼란 변수를 통제하는 접근법이 필요하다 (OHDSI가 지원하는 연구 설계 및 여러 특성에 근거해 연구 집단의 균형을 맞춤으로써 관찰된 혼란 변수를 제거하는 PLE 방법에 대한 자세한 설명은 12장과 18장을 참조).
19.1.2 연구 설계의 사전 지정
관찰 연구 설계 및 매개 변수의 사전 지정 pre-specification은 때로 p-hacking이라고 불리는 원하는 결과를 달성하기 위해 연구 프로토콜을 수정하면서, 잠재 의식적으로 또는 의식적으로 조금씩 추가적인 비뚤림 bias을 도입하지 않도록 하는 데 중요하다. 사전에 연구 세부 사항을 완전히 지정하지 않으려는 유혹은 전자 의무 기록 및 청구와 같은 데이터가 연구자에게 무한한 가능성에 대한 구불구불한 조사선 meandering line of inquiry을 초래하기 때문에 데이터의 1차 사용보다 2차 사용에서 더 크다. 핵심은 기존 데이터를 쉽게 이용할 수 있음에도 불구하고 과학적 탐구의 엄격한 구조를 여전히 적용하는 것이다. 사전 지정 원칙은 인구 수준 추정 또는 환자 수준 예측에서 엄밀하거나 재현 가능한 결과를 보장하기 위해 특히 중요한데, 이러한 결과는 궁극적으로 임상 실무 또는 규제 결정에 영향을 줄 수 있기 때문이다. 특성화 연구 characterization study가 순수하게 탐색적 목적으로 수행되는 경우에도, 잘 지정된 계획 수립은 여전히 바람직하다. 그렇지 않으면 차츰 발전하는 연구 설계 및 분석 프로세스가 문서화, 설명 및 재생산에 어려움을 준다.
19.1.3 프로토콜
관찰 연구 계획은 연구 수행 전에 만들어진 프로토콜 형태로 문서화되어야 한다. 프로토콜은 최소한 주요 연구 질문, 접근 방식 및 질문에 답하는데 사용될 측정 항목을 설명한다. 연구 집단은 다른 연구자가 연구 집단을 완전히 재생산할 수 있도록 상세 수준으로 기술되어야 한다. 또한, 모든 방법 또는 통계 절차 및 측정 항목, 표 및 그래프와 같은 예상 연구 결과의 형태를 설명해야 한다. 종종, 프로토콜은 연구의 타당성 또는 통계적 검정력 statistical power을 평가하려고 설계된 일련의 사전 분석을 설명할 것이다. 더욱이, 프로토콜에는 민감도 분석이라고 하는 주요 연구 질문에 대한 변수 variation 설명이 포함될 수 있다. 민감도 분석은 연구 설계 선택이 전체 연구 결과에 미치는 잠재적 영향을 평가하도록 설계되었으며, 가능할 때마다 미리 설명해야 한다. 프로토콜이 완료된 후, 때론 프로토콜 수정이 필요할 수 있는 예기치 않은 문제가 발생한다. 프로토콜 수정이 필요한 경우, 프로토콜 자체의 변경 및 그 이유를 문서화하는 것이 중요하다. 특히 PLE 또는 PLP의 경우, 완성된 연구 프로토콜은 독립적인 플랫폼 (예를 들어 clinicaltrials.gov 또는 OHDSI의 studyProtocols sandbox)에 이상적으로 기록되며, 버전 및 수정 사항은 타임 스탬프 timestamp와 독립적으로 추적할 수 있다. 기관이나 데이터 원천 소유자가 연구 실행 전에 프로토콜을 검토하고 승인할 기회를 요구하는 경우가 종종 있다.
19.1.4 표준화된 분석
OHDSI의 독특한 장점은 관찰 연구에서 반복적으로 묻는 몇몇 주요 질문을 인식함으로써 도구가 계획, 문서화 및 보고를 지원하는 방식이다 ( 2장, 7장, 11장, 12장, 13장). 따라서, 반복되는 측면의 자동화로 프로토콜 개발 및 연구 구현 프로세스를 간소화한다. 대부분의 도구는 발생할 수 있는 대부분의 사용 사례를 다루는 몇몇 연구 설계 또는 측정 항목을 매개 변수화하도록 설계되었다. 예를 들어, 연구자는 연구 집단과 몇몇 추가 매개 변수를 지정하고 다른 약물 및/또는 결과를 반복하는 수많은 비교 연구를 수행한다. 연구자의 질문이 일반 템플릿에 적합한 경우, 프로토콜에 필요한 연구 집단 및 기타 매개 변수에 대한 많은 기본 설명을 자동으로 생성하는 방법이 있다. 역사적으로, 이러한 접근 방식은 OMOP 실험을 통해 이루어졌으며, 이는 관찰 연구 설계가 다양한 연구 설계 및 매개 변수를 반복하여 약물과 부작용 사이의 알려진 인과 관계를 얼마나 잘 재현할 수 있는지 평가하고자 하였다.
OHDSI 접근 방식은 이러한 단계를 공통 프레임워크 및 도구 내에서 비교적 간단하게 수행할 수 있도록 하여 프로토콜에 실행 가능성 및 연구 진단이 포함되는 것을 지원한다 (아래 19.2.4절 참조).
19.1.5 연구 패키지
표준화된 템플릿 및 디자인에 대한 또 다른 동기는 연구자가 프로토콜 형태로 연구가 상세하게 설명되어 있다고 생각하더라도 연구를 실행하기 위해 전체 컴퓨터 코드를 생성하기에 실제로 충분히 지정되지 않은 요소가 있을 수 있다는 것이다. OHDSI 프레임워크에 의해 가능한 관련 기본 원칙은 종종 “연구 패키지”라고 하는 컴퓨터 코드 형태로 문서화된, 완벽하게 추적 및 재현 가능한 프로세스를 생성하는 것이다. OHDSI 모범 사례는 이러한 연구 패키지를 Git) 환경에 기록하는 것이다. 이러한 연구 패키지는 코드 기반에 대한 모든 매개 변수 및 버전 지정 스탬프를 포함한다. 앞에서 언급한 바와 같이, 관찰 연구는 종종 공중 보건 결정 및 정책에 영향을 미칠 수 있는 질문을 한다. 따라서, 결과를 찾기 전에 관찰 연구는 이상적으로 다른 연구자에 의해 여러 환경에서 반복되어야 한다. 이러한 목적을 달성하는 유일한 방법은 연구를 완전히 재현하는데 필요한 모든 세부 사항을 명시적으로 매핑하고 추측이나 오해의 여지가 없도록 하는 것이다. 이러한 모범 사례를 지원하기 위해 OHDSI 도구는 문서 형태의 프로토콜에서 컴퓨터 또는 기계 판독 가능 연구 패키지로의 변환을 지원하도록 설계되었다. 이 프레임워크의 한 가지 단점은 기존 OHDSI 도구만으로 모든 사용 사례나 사용자 지정 분석을 쉽게 처리할 수는 없다는 것이다. 그러나 커뮤니티가 성장하고 발전함에 따라, 더 많은 사용 사례를 처리할 수 있는 더 많은 기능이 추가되고 있다. 커뮤니티에 참여하는 사람은 새로운 사용 사례를 통해 새로운 기능에 대해 제안할 수 있다.
19.1.6 CDM의 기초가 되는 데이터
OHDSI 연구는 관찰 데이터베이스가 OMOP 공통 데이터 모델(CDM)로 변환되는 것을 전제로 한다. 모든 OHDSI 도구 및 다운스트림 분석 단계는 데이터 표현이 CDM 사양을 준수한다고 가정한다 (4장 참조). 따라서, 이렇게 하기 위한 ETL 프로세스(6장 참조)는 변환 과정에서 인공물 artifact 혹은 다른 사이트 데이터베이스 간에 차이를 발생시킬 수 있어, 특정 데이터 원천에 대해 잘 문서화하는 것도 중요하다. OMOP CDM의 목적은 사이트별 특정 데이터 표현을 감소하는 것이지만, 이는 완벽한 프로세스와는 거리가 있으며 여전히 커뮤니티가 개선하고자 하는 도전적인 영역으로 남아 있다. 따라서, OMOP CDM으로 변환된 모든 원천 데이터에 친숙한 네트워크 연구를 수행할 때 사이트 또는 외부 사이트에서 개인과 공동으로 연구하기 위해 연구를 실행할 때는 여전히 중요하다.
CDM 외에도 OMOP 표준 용어 시스템(standardized vocabulary system) (5장 참조) 은 다양한 데이터 원천에서 상호운용성 interoperability을 얻기 위해 OHDSI 프레임워크와 함께 작업하는 데 중요한 요소이다. 표준화된 용어는 다른 모든 원천 용어 시스템이 매핑되는 각 용어 영역 vocabulary domain 내에서 일련의 표준 개념을 정의하려고 한다. 이런 방식으로, 약물, 진단 또는 절차에 다른 원천 용어 시스템을 사용하는 두 개의 서로 다른 데이터베이스는 CDM으로 변환될 때 비교될 것이다. OMOP 용어는 특정 코호트 정의에 적절한 코드를 식별하는데 유용한 계층 구조 hierarchy도 포함한다. 다시 말하지만, 데이터베이스를 OMOP CDM에 ETL하고 OMOP 용어를 사용하는 이점을 얻으려면 다운스트림 쿼리에서 용어 매핑을 구현하고 OMOP 표준화된 용어 코드를 사용하는 것을 권장한다.
19.2 세부 연구 단계
19.2.1 질문 정의
첫 번째 단계는 연구 관심사를 관찰 연구를 통해 해결할 수 있는 정확한 질문으로 변환하는 것이다. 당신은 임상 당뇨병 연구자이며 제2형 당뇨병 type 2 diabetes mellitus(T2DM) 환자에게 제공되는 치료의 질을 조사하려 한다고 가정해 보자. 이러한 큰 목적을 처음 7장에서 설명한 세 가지 유형의 질문 중 하나에 해당하는 훨씬 더 구체적인 질문으로 나눌 수 있다.
특성화 연구에서, “약물 처방이 지정된 의료 환경에서 경증 T2DM 환자와 중증 T2DM 환자에게 권장되는 사항을 준수하는가?”라고 물을 수 있다. 이러한 질문은 또 다른 치료와 비교해 주어진 치료의 유효성에 관한 인과 관계적 질문을 하는 것이 아니라, 단순히 기존 임상 가이드라인과 관련하여 데이터베이스에 약물 처방을 특성화하는 것이다.
T2DM 치료에 대한 처방 지침이 T2DM과 심장병을 함께 진단받은 환자와 같은 특정 환자 집단에 가장 적합한지 여부에 대해서 회의적인 의견이 있을 수 있다. 이러한 질문은 PLE 연구로 번역될 수 있다. 특히, 심부전과 같은 심혈관 질환을 예방하는데 2가지 다른 T2DM 약물 계열의 효과 비교에 대해 질문할 수 있다. 다른 약물을 복용하는 T2DM과 심장 질환을 함께 진단받은 환자를 포함하는 2개의 코호트에서 심부전으로 입원할 상대적 위험도를 조사하는 연구를 설계할 수 있다.
또는, 경증 T2DM에서 중증 T2DM으로 진행할 환자를 예측하는 모델을 개발할 수 있다. 이것은 PLP 질문으로 만들어질 수 있으며, 더욱 신중한 치료를 위해 중증 T2DM으로 발전할 위험이 있는 환자를 지정하기 위해 활용될 수 있다.
순수하게 실용적인 관점에서, 연구 질문을 정의하려면 질문에 대답하는데 필요한 접근 방식이 OHDSI 도구 모음 내에서 사용 가능한 기능을 준수하는지 여부도 평가해야 한다 (현재 도구로 해결할 수 있는 질문 유형에 대한 자세한 설명은 7장 참조). 물론, 항상 자신만의 분석 도구를 설계하거나 현재 사용 가능한 도구를 수정하여 다른 질문에 대답할 수 있다.
19.2.2 데이터 가용성 및 품질 검토
특정 연구 질문에 전념하기 전에, 데이터 품질 (15장 참조)을 검토하고, 특정 필드가 채워지고 데이터가 다루는 치료 설정의 관점에서 특정 관찰 의료 데이터베이스의 특성을 실제로 이해하는 것이 권장된다. 이를 통해 특정 데이터베이스에서 연구 질문을 실현할 수 없는 문제를 신속하게 파악할 수 있다. 아래에서, 발생할 수 있는 몇 가지 일반적인 문제를 지적한다.
경증 T2DM에서 중증 T2DM으로 진행을 예측하는 모델을 개발하는 위의 예로 돌아가자. 이상적으로 T2DM의 중증도는 당화혈색소(HbA1c) 수준을 검사함으로써 평가될 수 있는데, 이는 이전 3개월 동안 환자의 평균 혈당 수치를 반영하는 실험실 측정치이다. 모든 환자가 이 수치를 가지고 있거나 그렇지 않을 수도 있다. 전체 또는 일부 환자가 이 수치를 가지고 있지 않다면, T2DM의 중증도에 대한 다른 임상 기준을 확인하여 대신 사용할 수 있는지를 고려해야 한다. 또는, 일부 환자만 HbA1c 수치를 가지고 있다면, 이 하위 모음 환자에게만 초점을 맞추는 것이 연구에서 원치 않는 비뚤림을 유발하는지 여부도 평가해야 한다. 결측 자료에 대한 추가 논의는 7장을 참조하라.
또 다른 일반적인 문제는 특정 의료 환경에 대한 정보가 부족하다는 것이다. 위에 설명한 인구 수준 추정 예시에서, 제안된 결과는 심부전으로 인한 입원이었다. 주어진 데이터베이스에 입원 환자 정보가 없는 경우, 다른 T2DM 치료 방법의 효과를 비교 평가하기 위해 다른 결과를 고려해야 할 수도 있다. 다른 데이터베이스에서, 외래 환자 진단 데이터를 사용할 수 없으므로, 코호트 설계를 고려해야 할 것이다.
19.2.3 연구 집단
연구 집단을 정의하는 것은 모든 연구의 기본 단계이다. 관찰 연구에서, 관심 있는 연구 집단을 대표하는 개인의 그룹은 종종 코호트로 지칭된다. 코호트로 선택하기 위해 필요한 환자 특성은 현재 임상 질문과 관련된 연구 집단에 의해 결정될 것이다. 간단한 코호트 예는 18세 이상이며 의료 기록에 T2DM 진단 코드가 있는 환자이다. 이 코호트 정의에는 AND 논리로 연결된 두 가지 기준이 있다. 종종 코호트 정의에는 더 복잡한 중첩된 부울 boolean 논리와 특정 연구 기간 또는 환자의 기저 기간 baseline period에 필요한 시간과 같은 추가 시간 기준으로 연결된 더 많은 기준이 포함된다.
정제된 일련의 코호트 정의는 적절한 환자 그룹을 식별하기 위해 적절한 과학 문헌 및 특정 데이터베이스를 해석하는데 어려움을 이해하는 임상 및 기술 전문가의 조언과 검토가 요구된다. 관찰 데이터로 작업할 때 이러한 데이터는 환자의 병력에 대한 완전한 그림을 제공하지 않고 정보의 기록에 도입되었을 수 있는 사람의 실수와 편견이 있는 시간에 대한 스냅샷임을 명심해야 한다. 주어진 환자는 관찰 기간이라고 하는 제한된 시간 동안만 추적 할 수 있다. 연구 중인 특정 데이터베이스 또는 의료 환경 및 질병 또는 치료에 대해, 임상 연구자는 가장 일반적인 오류의 원천을 피하고자 제안을 할 수 있다. 간단한 예를 들어, T2DM 환자를 식별할 때 흔히 발생하는 문제는 T1DM 환자가 때때로 T2DM 진단으로 잘못 코딩된다는 것이다. T1DM을 가진 환자는 근본적으로 다른 그룹이기 때문에, T2DM 환자를 검사하려는 연구에 T1DM 환자 그룹을 의도치 않게 포함하면 결과가 왜곡될 수 있다. T2DM 코호트의 확고한 정의를 갖기 위해, T1DM 환자가 잘못 대표되는 것을 피하고자 당뇨병 치료제로서 인슐린만을 처방받은 환자를 제거하고자 할 수 있다. 그러나 동시에 의료 기록에 T2DM 진단 코드가 있는 모든 환자의 특성에 관심이 있는 상황일 수도 있다. 이 경우, 잘못 코딩된 T1DM 환자를 제거하기 위해 추가 자격 기준을 적용하는 것이 적절하지 않을 수 있다.
연구 집단의 정의가 기술되면, OHDSI 도구인 ATLAS는 관련 코호트를 생성하기 위한 좋은 출발점이다. ATLAS 및 코호트 생성 프로세스는 8장 및 10장에 자세히 설명되어 있다. 간단히 말해, ATLAS는 상세한 포함 기준으로 코호트를 정의하고 생성하기 위한 사용자 인터페이스 user interface(UI)를 제공한다. 코호트가 ATLAS에서 정의되면, 사용자는 프로토콜에 통합하기 위해 세부 정의를 사람이 읽을 수 있는 형식으로 직접 내보낼 수 있다. 어떤 이유로 ATLAS 인스턴스가 관찰 의료 데이터베이스에 연결되지 않은 경우에도, ATLAS를 사용하여 코호트 정의를 작성하고 연구 패키지에 통합하기 위해 기본 SQL 코드를 직접 내보내서 SQL 데이터베이스 서버에서 별도로 실행할 수 있다. ATLAS는 코호트 정의를 위한 SQL 코드 작성 이상의 이점을 제공하므로 가능하면 ATLAS를 직접 사용하는 것이 권장된다 (아래 참조). 마지막으로, ATLAS UI로 코호트 정의를 구현할 수 없고, 수동 사용자 지정 SQL 코드가 필요한 드문 상황이 있을 수 있다.
ATLAS UI는 다양한 선택 기준으로 코호트를 정의할 수 있다. 기초 기준 baseline criteria뿐만 아니라 코호트 진입 entry 및 종료 exit 기준은 각 도메인에 대해 표준 코드 standard code를 지정해야 하는 질병 condition, 약물 drug, 시술 procedure 등과 같은 OMOP CDM의 모든 도메인을 기준으로 정의할 수 있다. 또한, 이러한 도메인을 기반으로 하는 논리 필터와 연구 기간을 정의하는 시간 기반 time-based 필터 및 기저 시간 프레임 baseline timeframe을 ATLAS 내에서 정의할 수 있다. ATLAS는 각 기준에 대한 코드를 선택할 때 특히 유용하다. ATLAS에는 코호트 정의에 필요한 일련의 코드를 작성하는데 사용할 수 있는 용어 탐색 기능 vocabulary-browsing feature이 통합되어 있다. 이 기능은 OMOP 표준 용어에만 의존하며 용어 계층에 모든 하위 요소 descendant를 포함하는 옵션이 있다 (5장 참조). 따라서, 이 기능을 사용하려면 ETL 프로세스 중에 모든 코드가 표준 코드에 적절하게 매핑되어 있어야 한다 (6장 참조). 포함 기준에 사용할 최상의 코드 모음 codeset이 명확하지 않은 경우, 코호트 정의에서 일부 탐색적 분석이 필요한 곳일 수 있다. 대안적으로, 상이한 코드 모음을 사용하여 코호트의 다른 가능한 정의를 설명하기 위해 더욱 공식적인 민감도 분석이 고려될 수 있다.
ATLAS가 데이터베이스에 연결되도록 적절하게 구성되어 있다고 가정하면, 정의된 코호트를 생성하기 위한 SQL 쿼리를 ATLAS 내에서 직접 실행할 수 있다. ATLAS는 각 코호트에 고유한 ID를 자동으로 할당하여 나중에 사용할 수 있도록 백엔드 backend 데이터베이스에서 코호트를 직접 참조하는데 사용될 수도 있다. 코호트는 발생률 연구를 수행하기 위해 ATLAS 내에서 직접 사용되거나 PLE 또는 PLP 연구 패키지의 코드로 백엔드 데이터베이스에서 직접 지시될 수 있다. 주어진 코호트에 대해 ATLAS는 코호트에 있는 개인 환자 ID, 색인 날짜 및 코호트 종료 날짜만 저장한다. 이 정보는 특성화, PLE 또는 PLP 연구를 위한 환자의 기본 공변량과 같이 환자에게 필요할 수 있는 다른 모든 속성 또는 공변량을 도출하기에 충분하다.
코호트가 생성되면, 환자 인구통계의 특성 요약과 가장 빈번한 관찰된 약물 및 상태 빈도가 기본적으로 ATLAS 내에서 직접 생성되고 볼 수 있다.
실제로 대부분의 연구에서는 여러 코호트 또는 여러 모음의 코호트를 지정해야 하며, 그런 다음 새로운 임상적 통찰을 얻기 위해 다양한 방식으로 비교된다. PLE 및 PLP의 경우, OHDSI 도구는 이러한 여러 코호트를 정의하기 위한 구조화된 프레임워크를 제공한다. 예를 들어, PLE 효과 비교 연구에서는 일반적으로 최소 3개의 코호트 (대상 코호트 target cohort, 대조 코호트 comparator cohort, 결과 코호트 outcome cohort)를 정의한다 (12장 참조). 또한, 전체 PLE 효과 비교 연구를 수행하려면, 음성 대조군 결과 negative control outcome 및 양성 대조군 결과 positive control outcome를 가진 여러 코호트가 필요하다. OHDSI 도구 모음 toolset은 18장에서 자세히 설명한 대로 이러한 음성 및 양성 대조군 코호트의 생성을 가속화하고 자동화하는 방법을 제공한다.
마지막으로, 연구에 대한 코호트를 정의하면 표현형 phenotype이 본질적으로 추출 가능한 코호트 정의인 확고하고 검증된 표현형의 라이브러리를 정의하기 위해 OHDSI 커뮤니티에서 진행 중인 작업의 이점이 있을 수 있다. 기존 코호트 정의 중 어느 것이 연구에 적합한 경우, JSON 파일을 ATLAS 인스턴스로 가져와 정확한 정의를 얻을 수 있다.
19.2.4 실행 가능성 및 진단
코호트가 정의되고 생성되면, 사용 가능한 데이터 원천에서 연구의 실행 가능성을 조사하기 위한 보다 공식적인 프로세스를 수행하고 결과를 최종 프로토콜에 요약할 수 있다. 연구의 실행 가능성에 대한 평가는 다수의 탐색적이며 때로는 반복적인 활동을 포함할 수 있다. 여기에 몇 가지 일반적인 측면을 설명한다.
이 단계의 주요 활동은 생성된 코호트가 원하는 임상적 특성과 일치하고 예기치 않은 특성을 표시하는지 확인하기 위해 코호트 내의 특성 분포를 철저히 검토하는 것이다. 위의 T2DM 예로 돌아가서, 다른 모든 진단의 빈도를 검토하여 이 간단한 T2DM 코호트를 특성화함으로써, T1DM 환자를 포착하는 문제 또는 다른 예상치 못한 문제를 표시할 수 있다. 코호트 정의의 임상적 타당성의 품질 검사로써 연구 프로토콜에 초기에 새로운 코호트를 특성화하는 단계를 작성하는 것은 바람직하다. 구현 측면에서 첫 번째 패스를 수행하는 가장 쉬운 방법은 코호트가 ATLAS에서 생성될 때 기본적으로 생성될 수 있는 코호트 인구통계와 주요 약물 및 상태를 검사하는 것이다. ATLAS 내에서 직접 코호트를 작성하는 옵션을 사용할 수 없는 경우, 수동 SQL 또는 R 기능 추출 패키지 feature extraction package를 사용하여 코호트를 특성화할 수 있다. 실제로, 대규모 PLE 연구 또는 PLP 연구에서, 이러한 단계는 기능 추출 단계를 가진 연구 패키지에 내장될 수 있다.
PLE 또는 PLP의 실행 가능성을 평가하기 위한 또 하나의 일반적이고 중요한 단계는 코호트 크기와 대상 코호트와 대조 코호트의 결과 수를 평가하는 것이다. ATLAS의 발생률 기능은 다른 위치에서 설명한 대로 검정력 계산을 수행하는데 사용될 수 있는 이러한 수를 찾는 데 활용될 수 있다.
PLE 연구에 권장되는 또 다른 옵션은 대상군과 대조군 집단 사이에 충분한 중복이 있는지 확인하기 위해 성향 점수 propensity score(PS) 매칭 단계 및 관련 진단을 완료하는 것이다. 이 단계는 12장에서 자세히 설명된다. 또한, 이러한 최종 일치된 코호트를 사용하여 통계적 검정력을 계산할 수 있다.
때에 따라, OHDSI 커뮤니티의 작업은 사용 가능한 샘플 크기가 주어지면 최소 검출 가능한 상대 위험 minimal detectable relative risk(MDRR)을 보고하여 연구가 실행된 후에만 통계적 검정력을 검사한다. 이 방법은 많은 데이터베이스와 사이트에서 높은 처리량, 자동화된 연구를 실행할 때 더 유용할 수 있다. 이 시나리오에서는, 사전 필터링보다는 모든 분석을 수행한 후 주어진 데이터베이스에서 연구 검정력을 더 잘 탐색할 수 있다.
19.2.5 프로토콜 및 연구 패키지 마무리
이전의 모든 단계에 대한 작업이 완료되면, 세부 코호트 정의와 이상적으로 ATLAS에서 추출한 연구 설계 정보가 포함된 최종 프로토콜이 완성되어야 한다. 부록 D에 PLE 연구를 위한 전체 프로토콜에 대한 샘플 목차를 제공한다. 이것은 OHDSI GitHub에서도 찾을 수 있다. 이 샘플은 포괄적인 가이드 및 체크리스트로 제공되지만, 일부 섹션은 여러분의 연구와 관련이 있을 수도 있고 그렇지 않을 수도 있다.
그림 19.1 에 도시된 바와 같이, 최종 연구 프로토콜을 사람이 읽을 수 있는 형태로 완성하는 것은 최종 연구 패키지에 통합된 모든 기계 판독 가능한 연구 코드를 준비하는 것과 병행하여 수행되어야 한다. 이러한 후자 단계는 아래 그림에서 연구 구현 study implementation이라고 한다. 이것에는 ATLAS에서 최종 연구 패키지를 내보내거나 필요한 사용자 정의 코드를 개발하는 것이 포함된다.
완성된 연구 패키지는 차례로 프로토콜에 설명될 수 있는 예비 진단 단계만 실행하기 위해 사용될 수 있다. 예를 들어, 두 치료의 효과 비교를 조사하기 위한 새로운 사용자 코호트 PLE 연구의 경우, 대상 및 대조 집단이 연구가 실행할 수 있도록 충분한 중첩을 가지고 있다는 것을 확인하기 위해 코호트 생성, 성향 점수 생성 및 매칭이 요구될 것이다. 이것이 결정되면, 결과 수를 얻기 위해 결과 코호트와 교차된 일치된 대상 및 대조 코호트로 검정력 계산을 수행할 수 있고, 이러한 계산 결과는 프로토콜에 기술할 수 있다. 이러한 진단 결과를 바탕으로, 최종 결과 모델을 실행하여 계속 연구를 진행할지 여부를 결정할 수 있다. 특성화 또는 PLP 연구와 관련하여, 여기서는 모든 시나리오를 간략하게 설명하지는 않지만, 이 단계에서 완료해야 하는 유사한 단계가 있을 수 있다.
중요한 것은, 이 단계에서 공동 연구자와 이해 관계자 stakeholder가 최종 프로토콜을 검토하도록 하는 것이다.
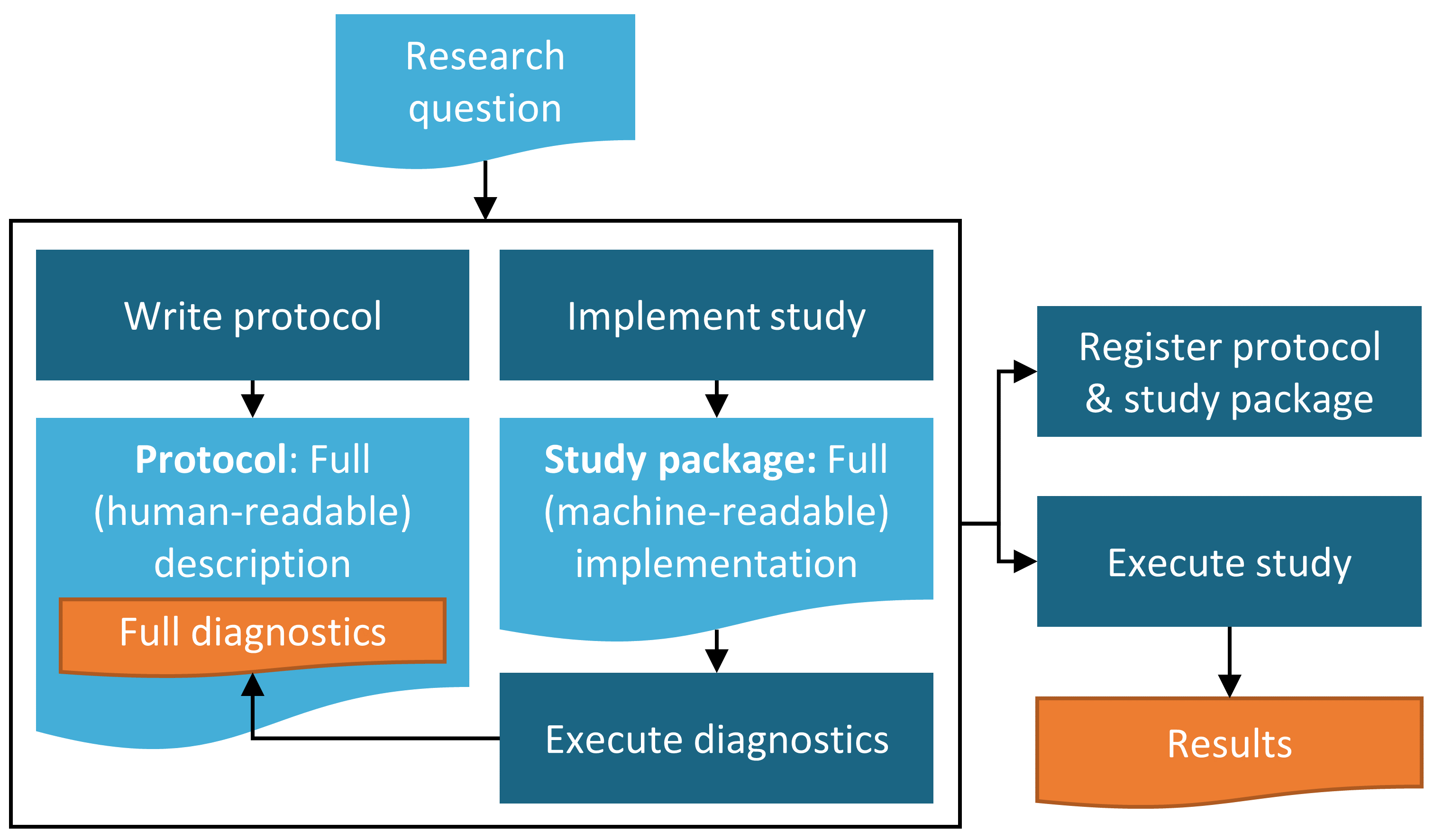
Figure 19.1: Diagram of the study process.
19.2.6 연구 수행
모든 이전 단계가 완료되면, 연구 실행은 이상적으로 간단해야 한다. 물론, 코드 또는 프로세스는 프로토콜에 요약된 방법 및 매개 변수에 대한 충실도 fidelity를 검토해야 한다. 연구 패키지가 사용자 환경에서 올바르게 실행되는 것을 확인하기 위해 연구 패키지를 테스트하고 디버깅해야 할 수도 있다.
19.2.7 해석 및 작성
표본 크기가 충분하고 데이터 품질이 합리적인 잘 정의된 연구에서, 결과 해석은 종종 간단하다. 마찬가지로, 최종 결과를 작성하는 것 이외의 최종 보고서를 작성하는 대부분의 작업은 프로토콜 계획 및 작성에서 수행되기 때문에, 보고서 또는 출판하려는 논문의 최종 작성 역시 종종 간단하다.
그러나 해석이 더 어려워지고 조심스럽게 해석에 접근해야 하는 몇 가지 일반적인 상황이 있다:
표본 크기가 유의미한 경계선에 있으며 신뢰 구간이 커진다.
PLE에 특수한 경우: 음성 대조군을 사용한 p-value 교정은 상당한 비뚤림을 나타낼 수 있다.
연구를 진행하는 과정에서 예상치 못한 데이터 품질 문제가 밝혀진다.
어떤 주어진 연구에 대해서도, 위의 우려 사항을 보고하고 그에 따른 연구 결과의 해석을 조율하는 것은 연구 저자의 재량에 달려 있다. 프로토콜 개발 프로세스와 마찬가지로, 최종 보고서를 발표하거나 출판하려고 원고를 제출하기 전에 임상 전문가와 이해 관계자가 연구 결과와 해석을 검토할 것을 권장한다.
19.3 요약
- 연구는 잘 정의된 질문을 조사해야 한다.
- 사전에 데이터 품질, 완전성 및 타당성에 대한 적절한 점검을 수행한다.
- 가능하면 프로토콜 개발 프로세스에 원천 데이터베이스 전문가를 포함하는 것을 권장한다.
- 프로토콜로 제안된 연구를 미리 문서화한다.
- 작성된 프로토콜과 함께 연구 패키지 코드를 생성하고 최종 연구를 실행하기 전에 실행 가능성 및 진단을 수행하고 설명한다.
- 연구는 실행 전에 (필요한 경우) 등록하고 승인을 받아야 한다.
- 완성된 보고서 또는 원고는 임상 전문가 및 기타 이해 관계자가 검토해야 한다.