Chapter 12 인구 수준 추정
Chapter leads: Martijn Schuemie, David Madigan, Marc Suchard & Patrick Ryan
관찰형 보건의료 데이터 (예를 들어 보험청구자료, 전자 의무 기록) 는 환자의 삶을 의미 있게 향상할 수 있는 치료 효과에 대한 실세계 증거를 생성할 기회를 제공한다. 이 장에서는 인구 수준 효과 추정 population-level effect estimation, 즉 특정 건강 결과에 대한 노출 (예를 들어, 약물 노출 또는 시술과 같은 의료개입)의 평균 인과적 영향 효과에 대한 추정에 초점을 맞춘다. 두 가지의 다른 추정 업무를 고려한다.
- 직접 효과 추정 direct effect estimation: 위험인자 비노출에 비교하여 위험인자 노출의 질병 결과 발생 위험에 대한 영향 추정.
- 비교 효과 추정 comparative effect estimation: 다른 노출 comparator exposure과 비교하여 표적 노출 target exposure의 질병 발생 위험에 대한 영향 추정.
두 가지의 경우에서, 인구 수준의 효과는 사실적 효과와 대조된다. 다시 말하면, 반 사실적인 counterfactual 결과를 가진 노출된 환자에게 무슨 일이 일어났는가? 노출이 일어나지 않았다면 (직접적) 혹은 다른 노출이 일어났다면 (상대적) 무슨 일이 일어났을까? 어떤 환자라도 하나의 사실적인 결과만 노출할 수 있기 때문에 (인과 추론의 근본적인 문제), 다양한 효과 추정 설계는 여러 분석 장치를 사용하여 반 사실적인 결과를 조명한다. (역자 주: 반사실 counterfactual이란 이론상의 가정으로서 A란 사람에게 B란 시점에 C란 약물을 투여하고 D란 질병 발생 유무를 측정한 후에, 타임머신을 타고 다시 시간을 거슬러 올라 B란 시점으로 돌아간 후에, 그 동일한 A에게 C를 투여하지 않고 관찰하여 D란 질병 발생 유무를 측정하는 것을 말한다. 이렇게 한다면 각종 비뚤림과 교란인자를 완전히 통제할 수 있다. 이론상으로만 가능하다)
인구 수준 효과 추정의 사용 사례 use-cases는 치료 선택, 안전 감시 safety surveillance, 비교 효과연구 comparative effectiveness를 포함한다. 방법은 특정 가설을 한 번에 하나씩 테스트 (예를 들어 부작용 실마리정보 평가 signal evaluation) 하거나 다중 가설을 한 번에 탐색 (예를 들어 부작용 실마리정보 감지 signal detection) 할 수 있다. 모든 경우에 있어, 목적은 고품질의 인과 관계 추정을 산출하는 것이다.
이 장에서는 우선 OHDSI Methods Library에 R 패키지로 구현된 다양한 인구 수준 추정 Population-Level Estimation 연구설계를 설명한다. 예제 평가 연구의 설계를 자세히 설명한 다음, ATLAS 및 R을 사용하여 설계를 구현하는 방법에 대한 단계별 가이드를 또한 설명한다. 마지막으로 연구 진단 및 효과 크기 추정을 포함하여 연구에서 생성된 다양한 결과를 검토한다.
12.1 코호트 방법론 설계
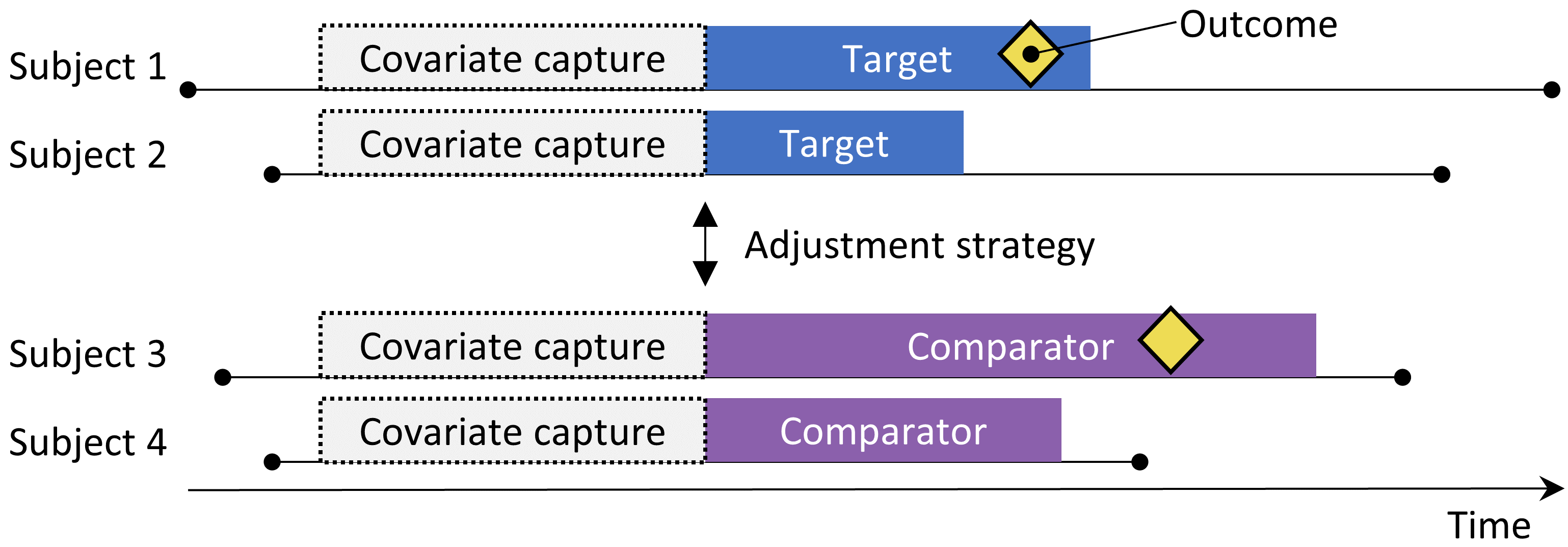
Figure 12.1: 새로운 사용자의 코호트 디자인 new-user cohort design: 표적 치료 target treatment를 시작하기 위해 관찰된 대상은 대조 대상 치료 comparator treatment를 시작한 대상과 비교된다. 두 치료군 간의 차이를 조정하기 위해 층화 stratification , 매칭 matching , 성향 점수에 의한 가중치 부여 weighting by propensity score, 결과 모델에 기저 특징 baseline characteristics 보정 추가와 같은 다양한 보정법 adjustment strategy을 사용할 수 있다. 성향 모델 propensity model 또는 결과 모델 outcome model에 포함된 특징은 치료 시작 전에 결정된다. (역자 주: new-user란 대상 위험에 생애 처음 노출된 환자를 말한다)
코호트 방법론은 무작위 임상 시험을 모방하려고 한다. (Hernan and Robins 2016) 하나의 치료를 시작한 환자(표적군 target cohort)는 다른 치료를 시작한 환자(대조군 comparator)와 비교되고, 치료를 받은 후 특정 기간 (예를 들어 치료를 받는 기간) 추적 관찰된다. 표 12.1 에서 강조하는 5가지 사항을 선택함으로써 코호트 연구에서 연구자가 얻기 원하는 답에 대한 질문을 지정할 수 있다.
| 선택 | 설명 |
|---|---|
| 표적 코호트 Target cohort | 표적 치료를 받은 환자군 cohort |
| 대조 코호트 Comparator cohort | 대조 치료를 받은 환자군 cohort |
| 결과 코호트 Outcome cohort | 관심 결과 outcome of interest가 발생한 환자군 cohort |
| 위험노출기간 Time-at-risk | (보통 표적 및 대조 코호트의 시작과 종료 시점에 기반하여) 결과 발생을 살펴볼 기간의 범위 |
| 모델 | 표적군과 대조군의 차이를 보정하여 효과 effect를 추정할 때 사용하는 통계 모델 |
모델 선택은 결과 모델의 유형을 지정한다. 예를 들어, 결과가 발생했는지를 평가하고 교차비 odds ratio를 산출하는 로지스틱 회귀분석 logistic regression을 사용할 수 있다. 로지스틱 회귀분석은 위험 노출 기간(TAR)이 표적군 target cohort과 대조군 comparator cohort 양쪽 모두에서 같거나 무관하다고 가정한다. 대안으로, 포아송 회귀분석 poisson regression을 선택할 수 있는데, 이는 일정한 발생률 incidence rate을 가정하고, 발생률 비율 incidence rate ratio을 추정한다. 콕스 회귀분석 Cox regression을 종종 사용하기도 하는데, 이는 표적군과 대조군 사이의 비례 위험 proportional hazard을 가정하며, 위험 비율 hazard ratio을 추정하려고 대상 질병이 처음 발생할 때까지의 시간 time-to-first-outcome을 고려한다.
주요 관심사는 표적 치료를 받는 군이 대조 치료를 받는 군과 전체적으로 systemically 다를 수 있다는 것이다. 예를 들어, 연구 대상 치료를 받는 표적 코호트 target cohort의 평균 연령이 60세이지만, 해당 치료를 받지 않은 대조 코호트 comparator cohort의 평균 연령이 40세라고 가정해보자. 연령과 관련된 건강 결과 (예를 들어 뇌졸중)는 양 군 간에 상당히 차이가 날 것이다. 이런 정보에 대해 정확히 숙지하지 못한 연구자는 해당 치료가 뇌졸중과 유의미한 인과관계를 보인다고 결론을 내릴 수 있다. 따라서, 해당 치료를 받지 않았다면 표적군의 환자가 뇌졸중에 걸리지 않으리라 생각할 수 있다. 이러한 결과는 전적으로 잘못되었다. 단순히 표적군의 연령이 높아서 뇌졸중을 많이 경험할 수 있기 때문이다. 표적군이 해당 치료를 받지 않았더라도, 뇌졸중의 발병률은 비슷할 수 있다. 여기서 나이는 “교란변수 confounder”이다. 관찰형 연구에서 교란변수를 통제하는 한 가지 방법은 성향 점수 propensity score를 이용하는 것이다.
12.1.1 성향 점수
무작위 배정 시험 randomized trial에서 (가상의) 동전 던지기를 통해 환자를 각각의 그룹에 무작위로 배정한다. 이렇게 하면 설계상 치료군과 대조군에 속한 환자가 대상치료를 받을 확률은 나이와 같은 환자의 기본 특성과 관련이 없게 된다. 동전에는 환자에 대한 정보가 없으며, 우리는 환자가 대상에 노출될 정확한 확률을 확실하게 알 수 있다. 결과적으로 임상시험에서 환자 수가 증가함에 따라 신뢰도가 증가해 두 환자군은 본질에서 어떠한 환자 특성이라도 다를 수 없다. 이 보장된 균형은 무작위 배정 시험이 측정한 특성 (예를 들어 나이)뿐 아니라 유전적 특성과 같이 무작위 시험이 측정하지 못한 특성에도 모두 적용된다.
주어진 환자의 성향 점수 Propensity score(PS)는 환자가 대조 치료군과 비교하여 표적 치료를 받을 확률이다. (Rosenbaum and Rubin 1983) 균형 잡힌 two-arm 무작위 임상시험에서, 모든 환자의 성향 점수는 0.5이다. 성향 점수 조정된 관찰 연구에서, 우리는 치료개시 시점과 치료개시 전 (환자가 실제로 받은 치료와 관계없이) 에 관찰할 수 있는 것에 근거해 표적 치료를 받을 환자의 확률을 추정한다. 이것은 간단한 예측 모델링 응용프로그램이다. 환자가 표적 치료를 받았는지의 여부를 예측하는 적합한 모델 (예를 들어 로지스틱 회귀분석)을 만들고, 이 모델을 사용하여 각 환자에 대한 예측 확률을 생성한다. 표준 무작위 임상시험과 달리, 다른 환자는 표적 치료를 받을 확률이 다르다. 성향 점수는 여러 가지 방법으로 사용할 수 있다. 예를 들어, 표적 피험자를 유사한 PS를 가진 comparator 피험자에게 매칭(PS matching)하거나, 성향 점수를 기반으로 연구 집단을 층화 PS stratification하거나, 성향 점수에서 파생된 Inverse Probability of Treatment Weighting(IPTW)을 사용하여 피험자에게 가중치를 적용하여 사용할 수 있다. 매칭할 때, 각 대상에 대하여 한 명의 비교 대상을 선택하거나, 일-대-다 비율 짝짓기 variable-ratio matching를 활용하여 대상당 두 명 이상의 비교 대상을 허용할 수 있다. (Rassen et al. 2012)
예를 들어 일대일 PS 매칭을 사용한다고 가정해보자. Jan이라는 환자가 표적 치료를 받을 선험 확률 prior probability이 0.4이고, 실제로 표적 치료 target treatment를 받고, Jun이라고 하는 또 다른 환자는 표적 치료를 받을 선험 확률이 0.4이지만, 사실상 대조 치료 comparator treatment를 받았다면, 적어도 측정된 교란변수에 대해 Jan과 Jun의 결과 비교는 작은 무작위 시험과 같다. 이 비교는 Jan과 Jun의 인과적인 대조를 무작위 시험으로 산출한 결과만큼 양호하게 추정할 것이다. 추정은 다음과 같이 진행된다: 표적치료를 받은 모든 환자에 대해, 대조 치료를 받았지만, 표적을 받는 선험적 확률이 동일한 하나 이상의 일치하는 환자를 찾는다. 그들의 짝지어진 환자군 matched group 안에서 표적 환자 target group의 결과와 비교 그룹 comparator group의 결과를 비교한다.
성향점수 방법은 측정된 교란변수 measured confounder를 제어한다. 사실, 측정된 특성 하에서 치료배정 treatment assignment이 “강력하게 무시할 수 있는” 경우라면, 성향 점수는 인과 관계의 비 편향적 추정을 산출할 것이다. “강력하게 무시할 수 있는” 조건이란 측정되지 않은 교란변수가 없고, 측정된 교란변수는 적절하게 조정된다는 것을 의미한다. 불행히도, 이것은 검증할만한 가정은 아니다. 18장에서 이에 대한 추가적인 논의를 볼 수 있다.
12.1.2 변수 선택
전통적으로 성향 점수는 연구자가 임의로 선택된 특성 manually selected characteristics을 기반으로 계산되었다. OHDSI 도구가 그러한 관행을 지원할 수는 있지만, 많은 일반적 특성 (즉, 연구의 특정 노출 및 결과에 따라 선택되지 않은 특성)을 포함하는 것을 선호한다. (Tian, Schuemie, and Suchard 2018) 이러한 특성에는 인구학적인 특성뿐만 아니라 치료 개시일 전과 개시일에 관찰된 모든 진단, 약물 노출, 측정 및 의료절차가 포함된다. 모델은 전형적으로 10,000 – 100,000가지의 독특한 특성을 포함하며, 이러한 모델은 Cyclops 패키지에서 구현되는 large-scale regularized regression (Suchard et al. 2013) 을 사용하여 적합한다. 본질적으로 우리는 치료 배정의 예측을 위하여 어떠한 환자 특성이 알고리즘에 사용되어야 하는지 데이터가 스스로 결정하도록 한다.
일부 연구자는 “올바른” 인과 구조를 반영하기 위해 임상적 전문지식에 의존하지 않는 데이터 기반 접근방식 data-driven approach을 통한 공변량 선택이 소위 도구적 변수 instrumental variable와 충돌자 collider를 잘못 포함해 분산을 증가시키고 잠재적으로 비뚤림을 만들어낼 위험이 있다고 주장해왔다. (Hernan et al. 2002) 하지만 이러한 우려가 실제 시나리오에서 큰 영향을 미칠 가능성은 적다. (Schneeweiss 2018) 게다가, 의학에서 진정한 인과 관계는 거의 알려지지 않다시피 하며, 서로 다른 연구자에게 특정 연구 주제에 대해 ‘올바른’ 공변량을 선택해 달라고 요청한다면, 각 연구자는 서로 다른 공변량 리스트를 주문할 것이 분명하고, 전체 과정은 재현 불가능해질 것이다. 무엇보다도, 성향 점수 모델의 검사, 모든 공변량의 균형 balance 평가, 음성 대조군을 통한 평가 등을 통해 도구적 변수 및 충돌자에 의해 발생하는 대부분의 문제를 진단할 수 있다.
12.1.3 캘리퍼
성향 점수가 0에서 1까지의 연속성을 갖기 때문에 정확한 일치는 거의 불가능하다. 그 대신, 매칭 프로세스는 대상 환자의 성향 점수와 일치하는 환자를 “캘리퍼 caliper”라고 알려진 내성 범위 내에서 찾는다. 이전 연구 (Austin 2011) 에 따라, 우리는 로직 척도에서 0.2 표준편차의 기본 default 캘리퍼를 사용한다.
12.1.4 오버랩: 선호 점수
성향 매칭 방법은 일치하는 환자가 필요하다! 따라서 주요 진단은 두 그룹의 성향 점수 분포를 보여준다. 해석을 용이하게 하기 위해 OHDSI 도구는 “선호 점수 preference score”라는 성향 점수의 변형을 그린다. (Walker et al. 2013) 선호 점수는 표적 치료와 대조 치료, 두 가지 치료법의 “market share”를 조정하다. 예를 들면, 10%의 환자가 표적 치료를 받고 (90%가 대조 치료를 받는 경우), 선호 점수가 0.5인 환자는 표적 치료를 받을 확률이 10%이다. 수학적으로 선호 점수는 다음과 같다.
\[\ln\left(\frac{F}{1-F}\right)=\ln\left(\frac{S}{1-S}\right)-\ln\left(\frac{P}{1-P}\right)\]
여기서 \(F\) 는 선호 점수, \(S\) 는 성향 점수, 그리고 \(P\) 는 표적치료를 받은 환자의 비율이다.
Walker et al. (2013) 는 “경험적 평형 empirical equipoise”의 개념을 논의한다. 적어도 노출의 절반이 0.3과 0.7 사이의 선호 점수를 갖는 환자에게 노출 쌍 exposure pair이 경험적 평형을 이루는 것으로 받아들인다.
12.2 자가 통제 코호트 연구 설계 Self-Controlled Cohort Design
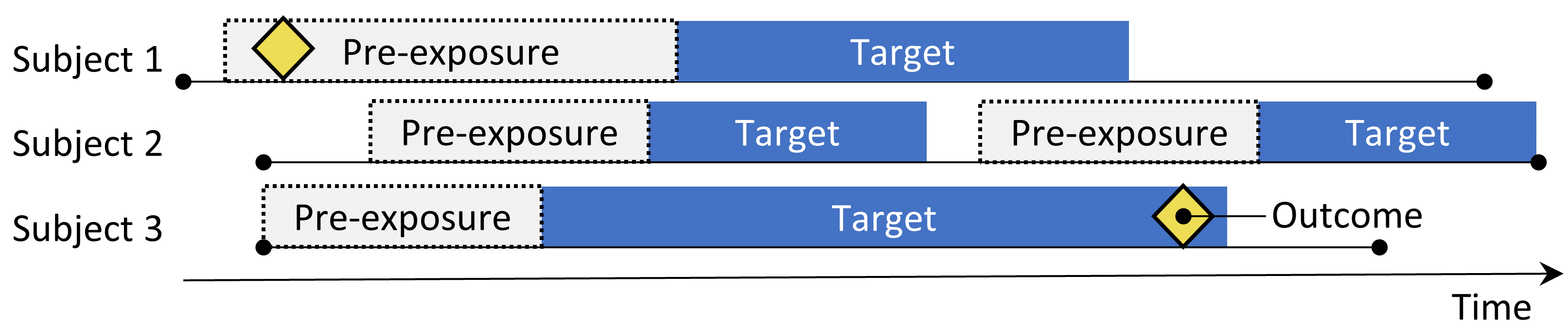
Figure 12.2: 자가 통제 코호트 연구 디자인. 목표물에 노출되는 동안의 결과 비율은 사전 노출 시간의 결과 비율과 비교된다.
자가 통제 코호트 self-controlled cohort(SCC) 설계 (Ryan, Schuemie, and Madigan 2013) 는 노출 직전의 결과 비율을 기준으로 노출되는 동안의 결과 비율을 비교한다. 표 12.2에 제시된 4가지 선택 사항은 SCC 질문을 정의한다.
| 선택 | 설명 |
|---|---|
| 표적 코호트 Target cohort | 표적 치료를 받은 환자군 cohort |
| 결과 코호트 Outcome cohort | 관심 결과 outcome of interest가 발생한 환자군 cohort |
| 위험노출기간 Time-at-risk | (보통 표적 코호트의 시작과 종료 시점에 기준으로) 결과 발생을 살펴볼 기간의 범위 |
| 통제 기간 Control time | 통제 기간 control time 으로 사용하는 기간 |
노출 그룹을 구성하는 동일한 피험자가 대조 그룹 control group으로 사용되기 때문에 사람 간 between-person의 차이를 조정할 필요가 없다. 그러나 이 방법은 다른 기간 간의 기존의 위험도 차이 등 다른 차이점에 대해 취약하다.
12.3 환자-대조군 연구 설계 Case-Control Design
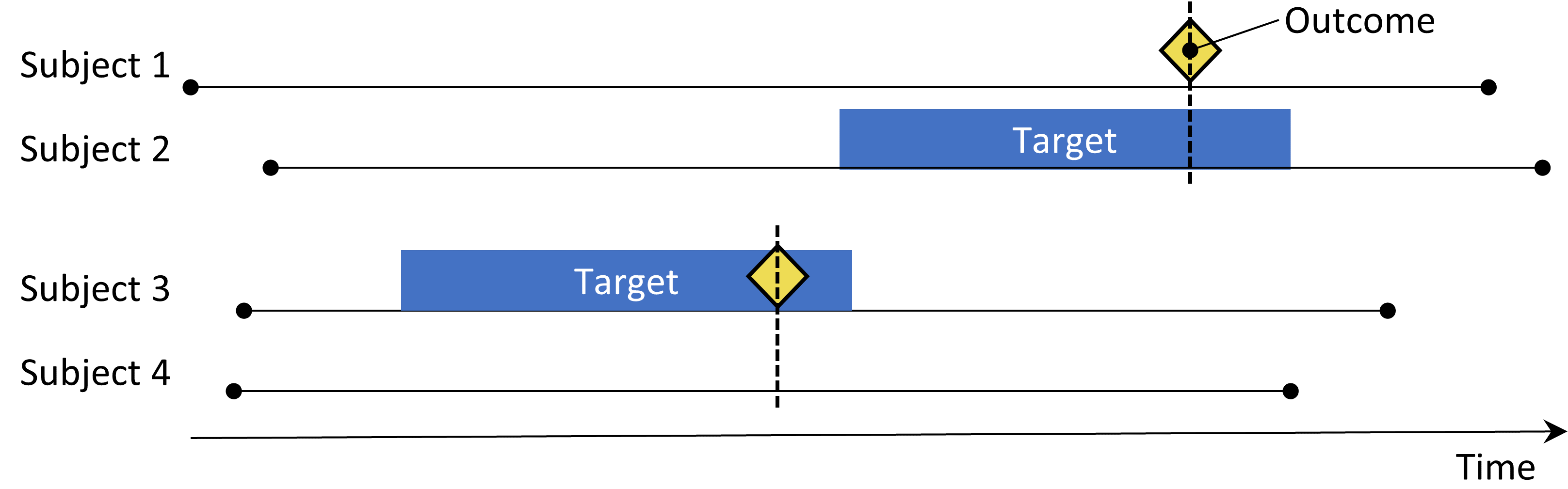
Figure 12.3: 환자-대조군 설계. 결과가 있는 대상 (“케이스”)은 노출 상태 측면에서 결과 (“컨트롤”)이 없는 대상과 비교된다. 나이와 성별 등 다양한 특성에 케이스와 컨트롤이 매칭되는 경우가 많다.
환자-대조군 연구 (Vandenbroucke and Pearce 2012) 는 “특정 질병 결과가 있는 사람이 질병이 없는 사람보다 특정 치료 agent에 더 자주 노출되는가?”라는 질문을 고려한다. 따라서, 주요 아이디어는 환자 cases (다시 말하면 outcome을 경험한 피험자)를 대조군 controls (다시 말하면 관심 결과를 경험하지 않은 피험자)에 비교하는 것이다. 표 12.3에 선택 사항은 환자-대조군 case-control 질문을 정의한다.
| 선택 | 설명 |
|---|---|
| 결과 코호트 Outcome cohort | 관심 결과 outcome of interest가 발생한 환자군 cohort |
| Control cohort | control 군. 일반적으로는 결과 코호트특정 선택 로직을 통해 결과 코호트 기반으로 자동으로 유도된다. |
| 표적 코호트 Target cohort | 표적 치료를 받은 환자군 cohort |
| 네스팅 코호트 Nesting cohort | 선택사항, case 와 control 을 유도할 부분집합 subpopulation 코호트 |
| 위험노출기간 Time-at-risk | (보통 코호트의 index date 기준) 노출 상태를 판단할 기간 |
종종 우리는 나이와 성별 등 환자군의 특성을 매칭하여 대조군을 설정한다. 또 달리 많이 사용되는 방법은, 특정 질병이 있는 환자군처럼, 특정 하위 집단 subgroup 환자군 안에서 nested analysis를 이용한다.
12.4 환자-교차 연구 설계 Case-Crossover Design
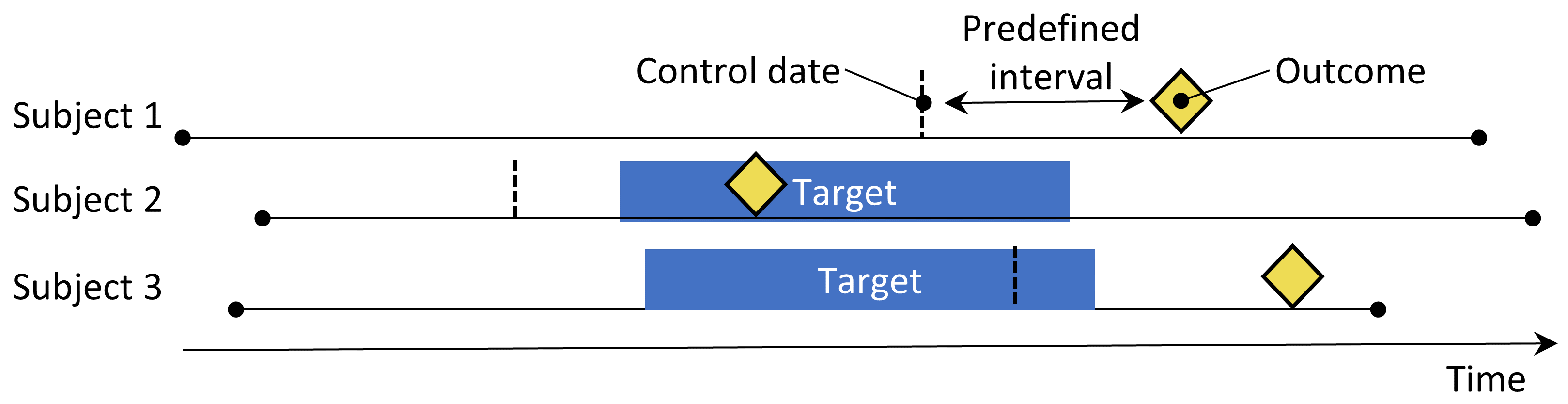
Figure 12.4: 환자-교차 연구 설계. 결과 근처의 시간을 결과 날짜 이전의 미리 정의된 간격으로 설정된 제어 날짜와 비교한다.
환자-교차 연구 case-crossover study (Maclure 1991) 설계는 결과 outcome 이전의 정해진 기간 노출률 rate of exposure의 차이가 나는지 평가하는 방법이다. 이것은 결과 발생 시점의 특이한 사항이 있는지 확인하는 방법이다. 표 12.4는 환자-연구 연구 정의를 위한 선택지를 보여준다.
| 선택 | 설명 |
|---|---|
| 결과 코호트 Outcome cohort | 관심 결과 outcome of interest가 발생한 환자군 cohort |
| 표적 코호트 Target cohort | 표적 치료를 받은 환자군 cohort |
| 위험노출기간 Time-at-risk | (보통 코호트의 index date 기준) 노출 상태를 판단할 기간 |
| Control 기간 | control 기간으로 사용할 기간 |
환자군은 그 자체로 대조군으로 사용된다. 자가 통제 코호트 연구 설계처럼, 환자 간 차이에 의한 교란변수를 통제할 수 있도록 환자군이 잘 선택되어야 한다. 한 가지 우려는, 결과 일시가 항상 대조군 일시보다 뒤에 오기 때문에, 전반적인 노출 빈도가 시간이 갈수록 높아져 양성 편향 (만약 노출빈도가 시간이 갈수록 줄어든다면 음성 편향이)이 일어날 수 있다는 점이다. 이를 통제하기 위하여 환자-교차 연구 연구 설계에 나이, 성별을 이용한 짝짓기를 통한 대조군을 추가하여 노출률을 보정하는 환자-시간-대조군 연구 설계 case-time-control design (Suissa 1995) 가 개발되었다.
12.5 자기 대조 환자군 연구 설계 Self-Controlled Case Series Design
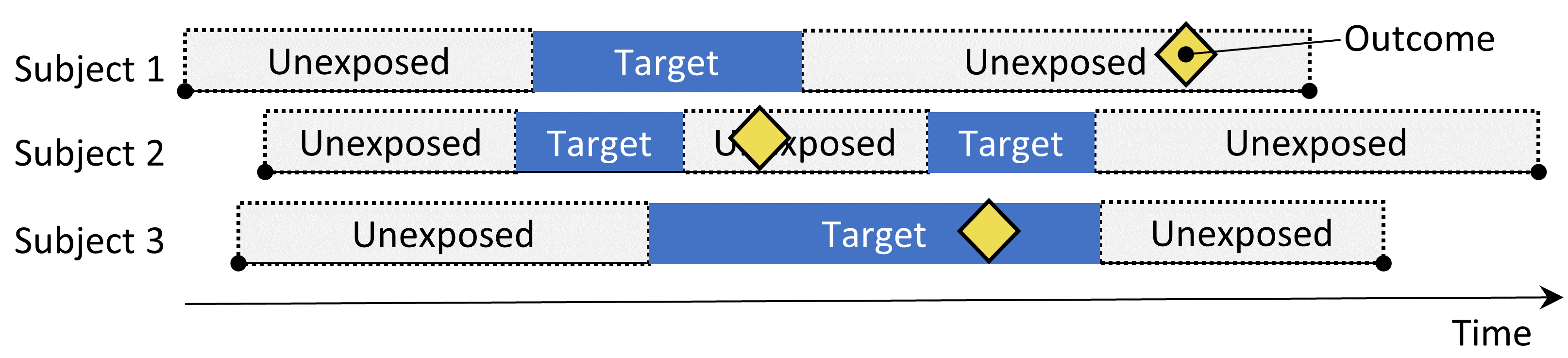
Figure 12.5: 자기 대조 환자군 연구설계. 노출 중 결과 발생의 비율은 노출되지 않는 중 발생한 결과의 비율과 비교된다.
자기 대조 환자군 연구 Self-Controlled Case Series(SCCS) 설계 (Farrington 1995; Whitaker et al. 2006) 는 전체 비노출 기간 (노출 이전, 노출 사이, 노출 후)과 노출 기간의 결과 발생의 비율을 비교한다. 즉 Poisson regression conditioned on the person이라고 할 수 있다. 따라서, 그것은 “환자에게 결과가 발생하였을 때, 비노출 기간보다 노출 기간에 발생할 가능성이 더 높은가?”이다. 표 12.5의 선택사항은 SCCS 질문을 정의한다.
| 선택 | 설명 |
|---|---|
| 표적 코호트 Target cohort | 표적 치료를 받은 환자군 cohort |
| 결과 코호트 Outcome cohort | 관심 결과 outcome of interest가 발생한 환자군 cohort |
| 위험노출기간 Time-at-risk | (보통 표적 코호트의 시작과 종료 시점에 기준으로) 결과 발생을 살펴볼 기간의 범위 |
| 모델 | 시간에 따라 변하는 교란변수 time-varying confounder의 보정을 포함하여 효과 effect를 추정할 때 사용할 통계 모델 |
다른 자가 통제 설계 self-controlled design와 마찬가지로, SCCS는 사람 간의 교란 변수 confounding due to between-person difference는 잘 바로잡지만, 시간의 변화에 따른 교란변수 confounding due to time-varying effect의 영향에는 취약하다. 이를 위해 몇 가지 보정을 시도할 수 있는데, 예를 들면 나이와 계절을 바로잡는 것이다. SCCS의 특별한 변형은 관심 대상의 노출뿐만 아니라 데이터베이스에 기록된 약물에 대한 다른 모든 노출 (Simpson et al. 2013) 에 잠재적으로 수천 개의 추가변수를 모델에 추가하는 것을 포함한다. 정규화 하이퍼-파라미터를 선택하기 위해 교차검증 cross-validation을 사용하는 L1-regularization이 관심 대상 노출을 제외한 모든 노출 계수에 적용된다.
SCCS의 기본 가정 중 하나는 관찰 기간 종료가 결과 날짜 outcome date와 독립적이라는 것이다. 몇 가지 결과의 경우, 예를 들어 뇌졸중과 같은 치명적인 fatal 질병의 경우, 이러한 가정이 위반될 수 있다. 이러한 종속성을 수정하는 SCCS의 확장이 개발되었다. (Farrington et al. 2011)
12.6 고혈압 연구 설계하기
12.6.1 문제 정의
ACE 억제제(ACEi)는 고혈압이나 허혈성 심장 질환 환자, 특히 울혈성 심부전, 당뇨병 또는 만성 신장 질환과 같은 다른 합병증이 있는 환자에게 널리 사용된다. (Zaman, Oparil, and Calhoun 2002) 일반적으로 입술, 혀, 입, 후두, 인두 또는 눈 주위 부위가 부어오르는 심각한 중증도의 때로는 생명을 위협하는 혈관부종 부작용은 이러한 약물의 사용과 관련이 있다. (Sabroe and Black 1997) 그러나 이러한 약물의 사용과 관련된 혈관부종에 대한 절대 및 상대 위험에 대한 정보는 제한적이다. 기존의 증거는 주로 다른 집단에 대한 일반화가 불가능한 특정 코호트 (예를 들어 주로 남성 퇴역 군인이나 메디케이드 Medicaid (역자 주: 메디케이드는 미국의 65세 미만 저소득층과 장애인을 위한 의료 보조 제도) 수혜자)에 대한 조사 또는 불안정한 위험 추정치를 제공하는 경위가 거의 없는 조사를 기반으로 한다. (Powers et al. 2012) 많은 관찰 연구에서 혈관부종의 위험에 대해서 ACEi와 베타 차단제를 비교하였지만 (Magid et al. 2010; Toh et al. 2012), 베타 차단제는 더 이상 고혈압의 1차 치료제로 권장되지 않는다. (Whelton et al. 2018) 사용 가능한 대체 치료제는 thiazide 또는 thiazide-like 이뇨제일 수 있으며, 이는 혈관부종의 위험 증가 없이 급성 심근경색과 같은 고혈압 관련 위험을 관리하는데 ACEi만큼 효과적이다.
다음은 비교 추정 질문을 다루기 위한 인구 수준 평가 프레임워크를 관찰 보건 데이터 observational healthcare data에 적용하는 방법을 보여준다:
Thiazide 및 thiazide-like 이뇨제를 새로 사용하는 환자에 비교해 ACEi를 새로 사용하는 환자의 혈관부종의 위험도는 어떻게 되는가?
Thiazide 및 thiazide-like 이뇨제를 새로 사용하는 환자에 비교해 ACEi를 새로 사용하는 환자의 급성 심근경색의 위험도는 어떻게 되는가?
이는 비교 효과 추정 comparative effect estimation 질문이기 때문에 12.1장에서 설명한 대로 Cohort Method를 적용할 것이다.
12.6.2 표적군 및 대조군
첫 번째 관찰된 고혈압 치료가 ACEi 또는 THZ 계열의 활성 성분을 단독요법으로 사용하는 경우를 새 사용자로 간주한다. 이 중 치료 시작 후 7일 동안 다른 항고혈압제를 시작하지 않은 경우를 단독요법으로 정의한다. 환자가 첫 번째 노출 전 데이터베이스에서 적어도 1년 동안 지속해서 관찰되고, 치료 시작 전 또는 그 이전에 기록된 고혈압 진단이 있는 경우로 정의했다.
12.6.3 결과
입원 또는 응급실 방문 중에 혈관부종 기록이 있고, 그 이전 일주일간 혈관부종 발생이 없었던 경우를 혈관부종으로 정의하였다. 입원 또는 응급실 방문 중에 심근경색 기록이 있고, 그 이전 180일간 심근경색 발생 기록이 없었던 경우를 심근경색으로 정의하였다.
12.6.4 위험 노출 기간 Time-At-Risk(TAR)
30일까지의 차이 gap를 인정하여, 치료 시작 다음 날부터 시작하여 연속적인 약물 노출이 (30일 이상) 중단될 때까지를 위험 노출 기간 Time-At-Risk(TAR)로 정의하였다.
12.6.5 모델
인구학적 특징, 상태, 약물, 절차, 측정, 관찰 결과, 다양한 병존 질환을 포함하는 공변량 기본 모음을 사용하여 적합한 성향 점수 모델을 구하는데, 공변량에서 ACEi와 THZ를 제외한다. 여기에서 다 비율 짝짓기를 수행하고, 성향 점수 짝짓기 된 모음에 대해 조건화된 콕스 회귀분석을 실시한다.
12.6.6 연구 요약
| 선택 | 설명 |
|---|---|
| 표적 코호트 Target cohort | 고혈압 치료로 ACE 억제제 초치료를 시작한 환자 cohort |
| 대조 코호트 Comparator cohort | 고혈압 치료로 thiazide 계 이뇨제 초치료를 시작한 환자 cohort |
| 결과 코호트 Outcome cohort | 혈관부종 또는 심근경색이 발생한 코호트 |
| 위험노출기간 Time-at-risk | 치료 시작 다음날부터 치료 중단까지 |
| 모델 | 일-대-다 매칭 후 콕스 비례위험모형 사용 |
12.6.7 대조군 질문
우리 연구 디자인이 실제와 일치하는 추정치를 산출하는지 평가하기 위해 진짜 효과 크기가 알려진 곳에 일련의 통제 질문을 추가로 포함한다. 통제 질문은 위험비 hazard ratio는 1인 음성 대조군 negative control과 1보다 큰 위험 비율을 갖는 양성 대조군 positive control으로 나눌 수 있다. 우리는 몇 가지 이유에서 실제 음성 대조군을 사용하고, 음성 대조군에 근거해 양성 대조군을 만든다. 대조군을 설정하고 사용하는 방법은 18장에서 자세히 다룬다.
12.7 ATLAS를 사용한 연구 구현하기
여기서는 위에서 수행한 고혈압 연구를 ATLAS의 추정 기능 Estimation function을 사용하여 어떻게 구현하는지 보여준다. ATLAS의 왼쪽 바에서  를 클릭하고 새로운 평가 연구를 작성하고, 이 연구에 쉽게 인식할 수 있는 이름을 붙이자. 연구 설계는
를 클릭하고 새로운 평가 연구를 작성하고, 이 연구에 쉽게 인식할 수 있는 이름을 붙이자. 연구 설계는  를 클릭하여 언제든지 저장할 수 있다.
를 클릭하여 언제든지 저장할 수 있다.
추정 설계 기능 estimation design function에는 세 가지 섹션이 있다: 비교 comparisons, 분석 설정 analysis settings, 평가 설정 evaluation settings. 다중 비교 및 다중 분석 설정을 할 수 있으며, ATLAS는 이러한 모든 조합을 각각의 분석으로 수행한다. 여기서는 각 섹션에 대해 설명한다:
12.7.1 대조 코호트 설정
한 연구에는 하나 이상의 대조 대상이 있을 수 있다. “Add Comparison”을 클릭하면 새 대화 상자가 열린다. 표적 target 및 대조 comparator 코호트를 선택하려면  을 클릭하면 된다. “Add Outcome”을 클릭하면, 위에서 정의한 두 개의 결과 코호트를 추가할 수 있다. 10장에서 설명한 대로 이미 코호트가 생성된 것으로 가정한다. 부록에서 표적군 (부록 B.2), 대조군 (부록 B.5), 결과 (부록 B.4과 부록 B.3) 코호트에 대해 자세히 볼 수 있다. 완료되면 그림 12.6에서와 같은 창이 생성될 것이다.
을 클릭하면 된다. “Add Outcome”을 클릭하면, 위에서 정의한 두 개의 결과 코호트를 추가할 수 있다. 10장에서 설명한 대로 이미 코호트가 생성된 것으로 가정한다. 부록에서 표적군 (부록 B.2), 대조군 (부록 B.5), 결과 (부록 B.4과 부록 B.3) 코호트에 대해 자세히 볼 수 있다. 완료되면 그림 12.6에서와 같은 창이 생성될 것이다.
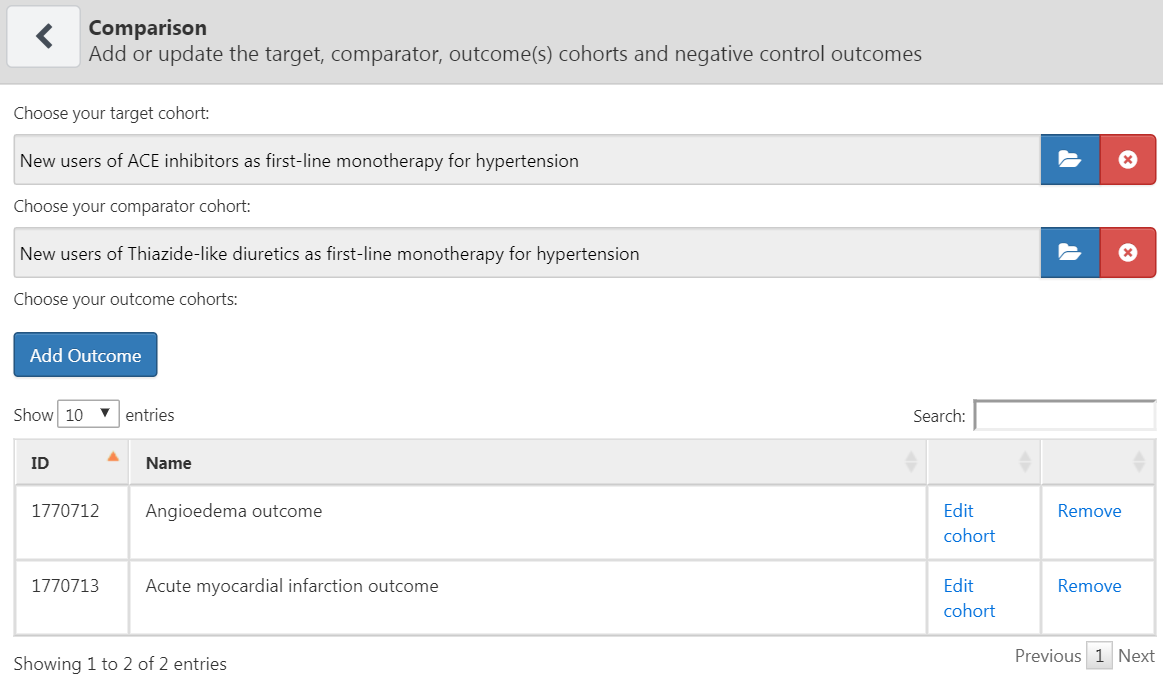
Figure 12.6: 대조 dialog
하나의 표적-대조 쌍 target-comparator pair에 대해 여러 개의 결과를 선택할 수 있다는 점에 주목하자. 각 결과는 독립적으로 처리되며 별도의 분석이 이루어진다.
음성 대조군 결과
음성 대조군 결과 Negative Control Outcome는 표적군 또는 대조군에 의해 야기된 것으로 생각되지 않는 결과이며 (역자 주: 즉, 위험 노출에 독립적으로 발생한 결과, 예를 들면 고혈압 약물 노출에 따른 항문 용종 발생 유무는 좋은 음성 대조군이 될 수 있다), 따라서 실제 위험 비는 1과 동일해야 한다. 이상적으로는 각 결과 코호트에 대해 적절한 코호트 정의를 가진다고 가정한다. 그러나, 우리는 일반적으로 음성 대조 결과 당 하나의 concept set과 이를 결과 코호트로 변환하는 표준 논리만 가진다. 여기서는 18장에서 설명한 대로 concept set이 이미 생성되었다고 가정하고 간단하게 선택할 수 있다. 음성 통제 concept set에는 음성 통제 당 하나의 concept만을 포함해야 하며, 하위 개념은 포함하지 않아야 한다. 그림 12.7은 본 연구에 사용된 음성 대조군 concept set을 보여준다.
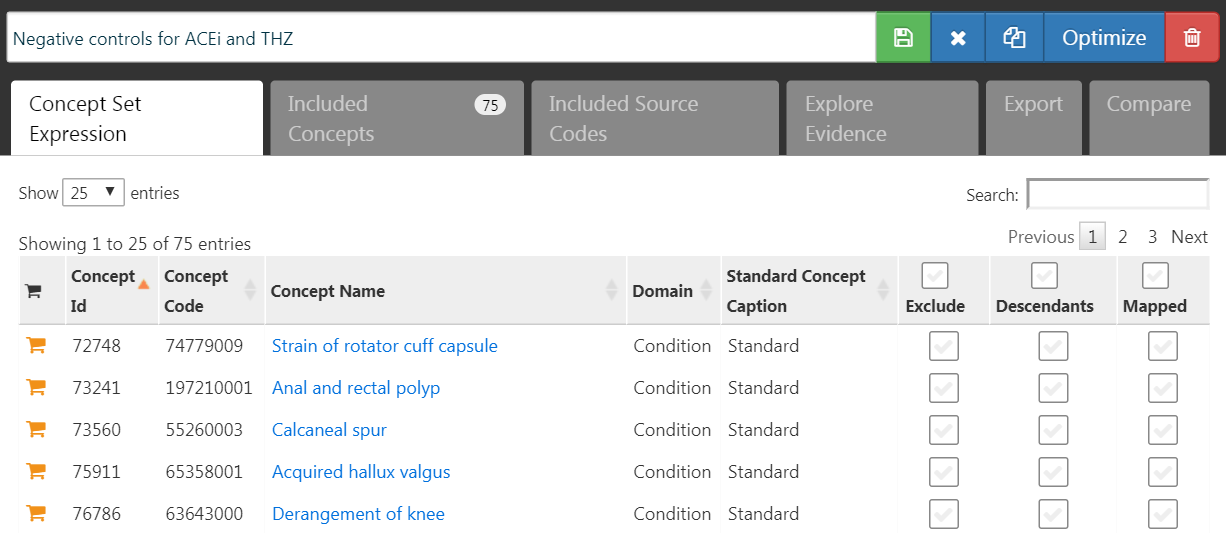
Figure 12.7: 음성 대조군 concept set
포함할 개념
포함할 개념 concepts to include 선택 시, 우리는 성향점수 모델 등에 어떠한 공변량이 생성되기를 원하는지 선택할 수 있다. 공변량을 지정하면, 모든 다른 공변량 (선택하지 않은)은 제외된다. 보통 regularized regression을 이용해 환자의 모든 기저 공변량에 대해 균형을 맞출 수 있는 모델이 만들어지기를 바란다. 만약 특정 공변량만을 선택하기 원한다면, 그것은 다른 연구자가 직접 공변량을 골라 수행한 다른 연구를 따라 해 보기를 원해서일 것이다. 가끔 공변량이 특정한 비교 (비교 시 이미 알고 있는 교란변수) 또는 분석 (특정 공변량 선택시 그 결과 차이에 대한 평가)에 관련되어 있기 때문에, 그러한 공변량을 비교 comparison 섹션 또는 분석 analysis 섹션에서 정의할 수 있다.
배제할 개념
추가하는 개념보다는 배제할 개념 concepts to exclude을 지정하는 경우가 많다. 배제할 concept을 지정하면, 배제할 concept을 제외한 모든 공변량을 사용함을 뜻한다. 기본 공변량 집합 default set of covariate 설정을 이용하면, 치료 시작 시의 모든 약물, 시술을 이용하기 때문에, 표적 치료 및 대조 치료에 해당하거나 이것과 직접적으로 관련된 concept을 배제해야 한다. 예를 들어, 만약 표적 치료가 약물 정맥 주입 치료라면, 우리는 약물뿐 아니라 정맥 주입 시술 역시도 성향 점수 모델에서 제외해야 한다. 이 예제에서 우리는 ACEi와 THZ를 배제했다. 그림 12.8에서 ACEi와 THZ, 그리고 하위 concept을 포함하여 배제할 concept set을 구성하는 것을 볼 수 있다.
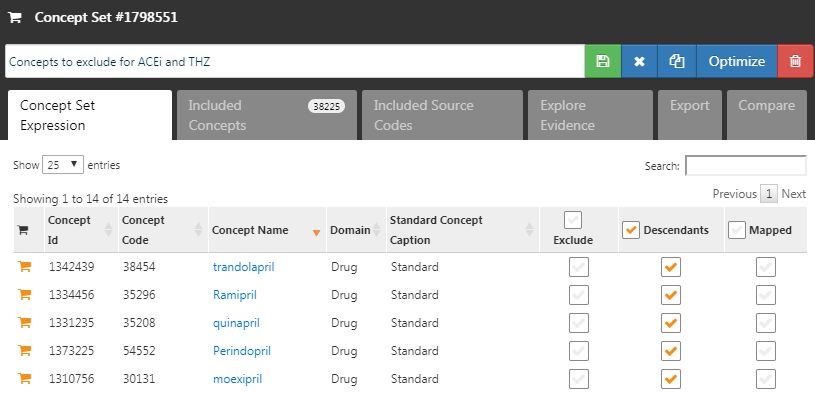
Figure 12.8: 배제할 concept을 정의하는 concept set
음성 대조군과 배제할 concept을 지정한 후, 비교 섹션의 아래쪽 절반 창은 그림 12.9과 같이 보일 것이다.
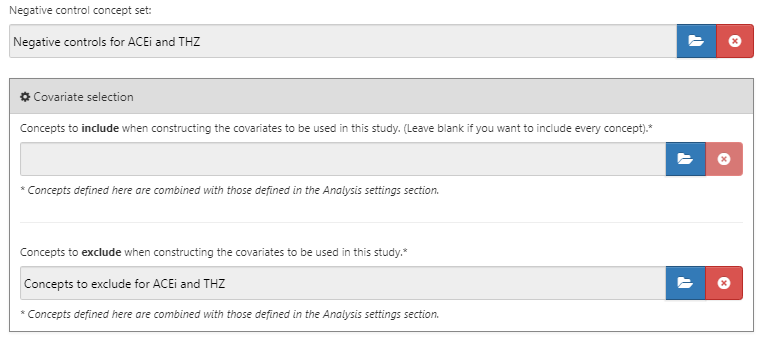
Figure 12.9: 음성 대조군에 대한 concept set과 배제할 concept을 보여주는 비교 창
12.7.2 효과 추정 분석 설정
비교 창을 닫은 후 “Add Analysis Settings” 을 클릭할 수 있다. “Analysis Name”이라는 상자에 다음에 기억하고 분류하기 쉽도록 분석별 고유한 이름을 지정할 수 있다. 예를 들어 “Propensity score matching”이라고 이름을 지을 수 있다.
연구 집단
분석에 포함할 피험자 집단과 같은 연구 집단 study population을 지정하는데 다양한 옵션이 있다. 코호트 정의 cohort definition 도구에서 표적 및 대조 코호트를 설계할 때 사용할 수 있는 옵션과 대부분 겹친다. 코호트 정의 도구 대신에 Estimation 옵션을 사용하는 한 가지 이유는 재사용성 re-usability이다. 표적, 대조 및 결과 코호트를 완전히 독립적으로 정의한 후에 이들 사이의 종속관계를 추가할 수 있다. 예를 들어, 치료 개시 전에 결과가 있었던 사람을 제외하기를 원한다면, 표적 및 대조 코호트 정의 내에서 그렇게 설정할 수도 있지만, 그렇게 한다면 모든 결과 outcome에 대해 별도의 코호트를 작성해야 한다! 대신에, Estimation 설정에서 이런 결과를 가진 사람을 제거하도록 선택할 수 있다. 이렇게 함으로써 이제 우리는 (음성 대조군 결과뿐만 아니라) 두 가지 관심 결과에 대해 표적 및 대조 코호트를 재사용할 수 있다.
연구 시작 및 종료일 study start and end dates은 분석을 특정 기간으로 제한하는데 사용할 수 있다. 연구 종료일 또한 위험 노출 기간 risk window를 잘라낼 수 있게 되어 연구 종료일 이후의 결과는 고려하지 않게 할 수 있다. 연구 시작일을 선택하는 한 가지 이유는 연구 중인 약물 중 하나가 새로운 것이며, 전에는 존재하지 않을 수 있기 때문이다. “두 노출이 모두 관찰되는 기간으로 분석을 제한하라 Restrict the analysis to the period when both exposures are present in the data?”는 옵션을 “예 yes”라고 설정하면, 새 약물이 데이터베이스에 존재하는 시점을 자동으로 연구 시작일로 조정할 수 있다. 연구 시작일과 종료일을 조정하는 또 다른 이유는 시기에 따라 (예를 들어 새로운 약물 부작용이 알려지면서) 임상 업무의 변화가 있고, 우리는 보통 특정 방식으로 임상이 이루어질 때만 관심이 있기 때문이다. (역자 주: 날짜는 상대 날짜가 아닌 절대 날짜임을 기억하라. 2019-12-31이라고 지정하면 실제 2019년 12월 31일을 의미한다)
“환자별로 첫 번째 위험 노출만 포함하겠는가? Should only the first exposure per subject be included?” 옵션을 사용하여 환자별로 첫 번째 위험 노출만으로 코호트를 제한할 수 있다. 이 옵션은 이번 예제에서처럼 코호트 정의에서 이미 수행한 경우가 많다. 유사하게, 코호트 정의에 “코호트에 포함될 사람이 기준 날짜 전에 최소 연속적 관측 시기 The minimum required continuous observation time prior to index date for a person to be included in the cohort” 옵션이 설정된 경우가 많아, 여기에 0으로 남겨둘 수 있다. 이러한 옵션은 기준 날짜 이전에 관찰된 시간 (OBSERVATION_PERIOD 테이블에서 정의된)을 가짐으로써 성향 점수를 계산할 수 있는 환자에 대한 충분한 정보가 있음을 보장하고, 환자가 이전에 노출된 적 없는, 치료에 대한 진정한 새로운 사용자 new user임을 보장하기 위해 자주 사용한다.
“만일 피험자가 여러 코호트에 중복되어 포함된다면, 중복포함을 막기 위해 새로운 위험 노출 기간 시작 시 중도 절단할 것인가? If a subject is in multiple cohorts, should time-at-risk be censored when the new time-at-risk starts to prevent overlap?” 하는 옵션과 함께 “표적 및 대조 코호트에 모두 포함된 피험자를 제거하겠는가? Remove subjects that are in both the target and comparator cohort?” 옵션은 피험자가 표적과 대조 코호트 양쪽 모두에 포함되어 있을 때 어떻게 할지 정의한다. “표적 및 대조 코호트에 모두 포함된 피험자를 제거하겠는가?” 옵션에 대해서는 세 가지 선택 사항이 있다:
- “Keep All”은 양 코호트의 모든 환자를 보존한다는 뜻이다. 이 옵션은 환자와 결과 쌍 개수를 중복으로 셀 수 있다.
- “Keep First”은 한 환자가 양 코호트에 모두 들어있을 경우, 두 코호트 중 먼저 들어간 코호트의 환자만 인정한다는 뜻이다.
- “Remove All”은 양 코호트에 모두 들어간 환자를 모두 제외하는 것이다.
“Keep all” 또는 “keep first” 옵션이 선택되면, 우리는 연구 대상자가 양쪽 코호트 모두에 속하는 시기를 절단하기를 바랄 수 있다. (그림 12.10) 기본적으로 위험 노출 기간은 코호트 시작일과 종료일을 기준으로 정의된다. 이번 예에서, 위험 노출 기간은 코호트 시작일 다음 날부터 시작되어 코호트 종료일에 끝난다. 절단하지 않는다면, 두 코호트의 위험 노출 기간이 겹칠 수 있다. 이 겹치는 동안 발생하는 모든 결과가 (그림과 같이) 두 번 계산되기 때문에 “keep all”을 선택하면 특히 문제가 된다. 만약 절단하기를 선택하면 첫 번째 코호트의 위험 노출 기간은 두 번째 코호트의 위험 노출 기간이 시작될 때 종료된다 (역자 주: 즉, Keep First를 선택하면 그림 12.10 에서 Target TAR censored가 위험 노출 기간으로 설정됨).
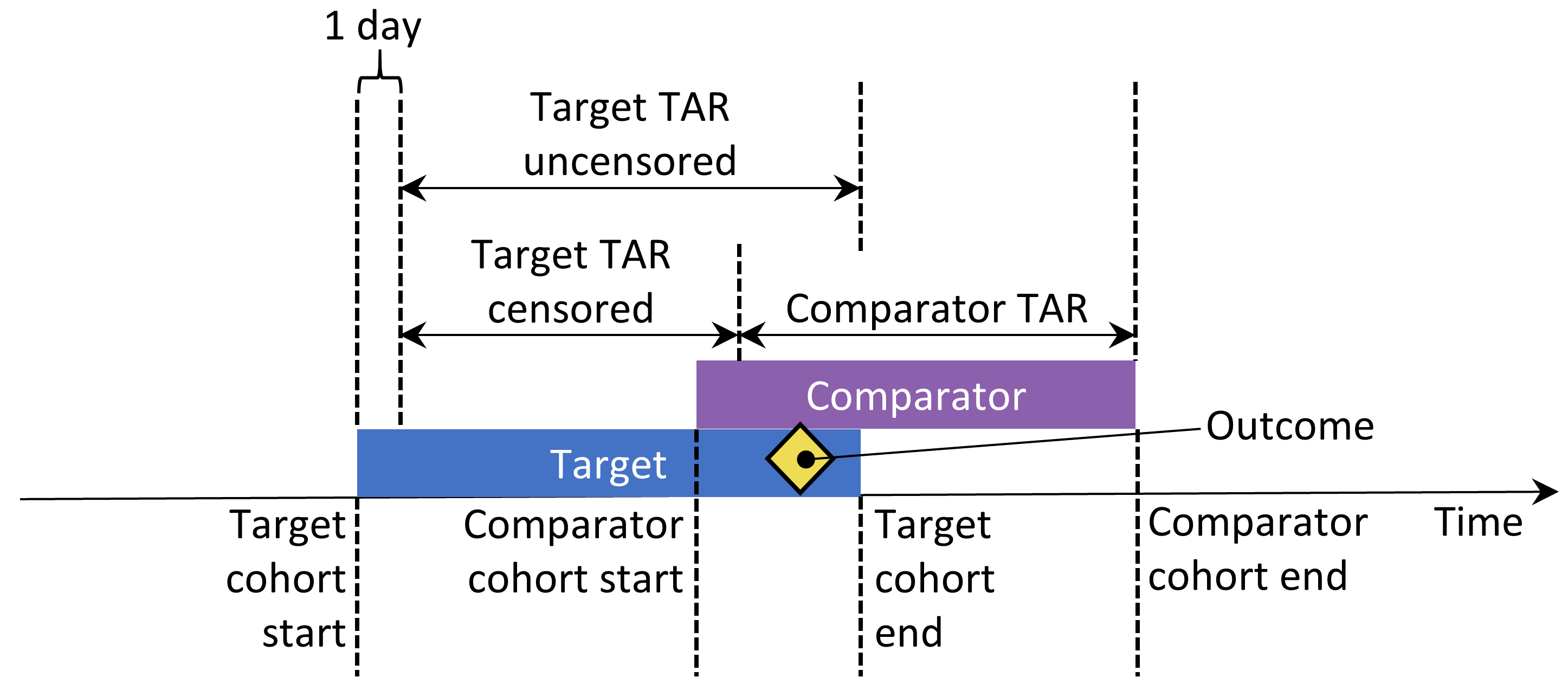
Figure 12.10: 두 코호트에 모두 포함된 피험자의 위험 노출 기간 TAR은 치료 시작 다음 날부터 시작하여 노출 끝에서 멈춘다고 가정한다.
최초의 결과 outcome 발생 이후 연속적으로 결과가 추가 발생하는 경우가 종종 있어서, 위험 노출 기간이 시작하기 전 결과가 발생한 피험자를 제거 remove subjects that have the outcome prior to the risk window start 할 수도 있다. 예를 들어, 누군가에게 심부전과 같은 만성 질병이 최초로 발생한 후, 두 번째 발생이 있을 수 있는데, 이는 심부전이 새로 다시 발생했다기보다는, 이전의 심부전이 완전히 치료되지 않은 상태를 의미할 가능성이 높다. 한편으로는 어떤 결과 outcome은 일시적일 수도 있다. 예를 들어 상부 호흡기 감염 upper respiratory infection과 같은 급성 질병이 한 환자에 여러 번 발생한다면, 이는 실제로 독립적인 질병이 시간 간격으로 두고 발생함을 의미할 수도 있다. 이전 결과를 확인할 때 며칠 전까지 검토해야 할지 how many days we should look back when identifying prior outcomes를 선택함으로써, 이전에 결과가 있는 사람을 제거하는 방법을 선택할 수 있다.
예제 연구에 대한 우리의 선택은 그림 12.11과 같다. 표적 및 대조 ‘코호트 정의’ 시 이미 첫 번째 노출로 한정하고 치료 개시 전에 관찰 시기가 필요하기 때문에 Estimation에서 이러한 기준을 다시 적용하지 않았다.
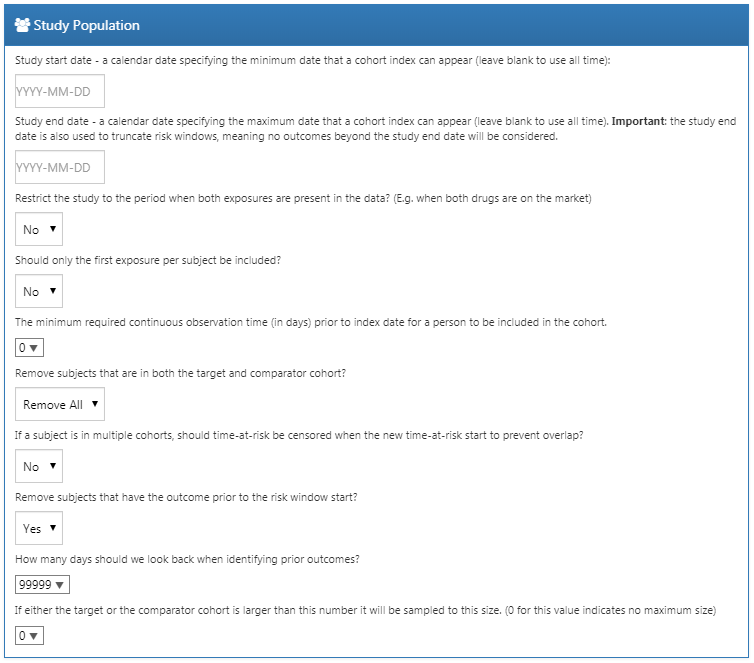
Figure 12.11: Study population 설정.
공변량 설정
여기서 사용할 공변량을 지정한다. 이러한 공변량은 일반적으로 성향 점수 모델에서 사용되지만, 결과 모델 (이 경우 콕스 비례위험모형 Cox proportional hazards model)에도 포함될 수 있다. 공변량 설정의 세부 사항 click to view details 을 클릭하면, 사용할 공변량 셋을 선택할 수 있다. 하지만, 인구학적 정보, 모든 진단명, 약물, 시술, 검사 등에 대한 공변량으로 구성된 기본 집합을 그대로 사용하길 권장한다.
포함하거나 제외할 개념을 지정하여 공변량 셋을 수정할 수 있다. 이러한 설정은 비교 설정의 12.7.1절에 있는 설정과 동일하다. 두 곳에서 이 설정이 가능한 이유는, 때때로 이번 예제처럼 비교하고자 하는 약물을 공변량에서 제외해야 하는 등 특별한 비교가 가능하게 하기 위함이다. 특별한 분석 설정을 이용해서 특별한 비교 분석을 수행하면 OHDSI 도구는 이러한 모음을 병합해서 적용한다.
그림 12.12는 이 연구에 대한 선택을 보여준다. 그림 12.9의 비교 설정에서 제외 개념에 하위 개념을 포함하도록 설정했다는 점에 주의하자.
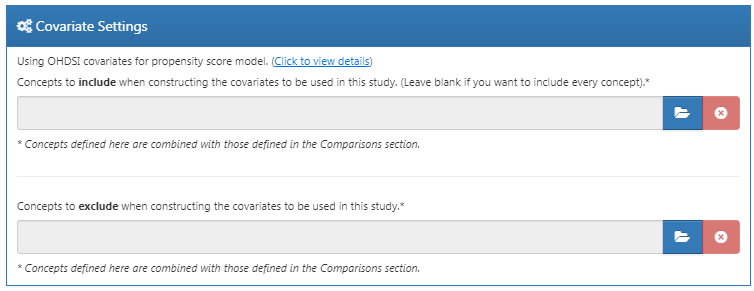
Figure 12.12: 공변량 설정.
위험 노출 기간
위험 노출 기간은 표적 및 대조 코호트의 시작일과 종료일을 기준으로 정의된다. 이 예제에서는, 치료 시작일을 코호트 시작일로, 약물 노출이 30일 이상 중지되면 코호트 종료일이 되도록 설정하였다. 코호트 시작 후 1일 (즉, 치료 시작 후 1일)을 위험 노출 기간의 시작으로 설정하였다. 치료 시작과 함께 발생한 결과가 이론상 치료에 의해 발생한 것이라고 믿기 어려울 때, 코호트 시작 이후에 위험 노출 기간이 시작하도록 설정한다.
코호트 종료일을 위험 노출 기간 종료일로 설정하여, 약물 노출이 중지된 시점으로 설정하였다. 예를 들어, 치료 종료 후에 발생한 event가 노출로 인한 것으로 판단될 경우, 위험 노출 기간의 종료일을 나중으로 설정할 수 있다. 극단적인 경우, 위험 노출 기간 종료를 코호트 종료일 후에 아주 나중 (예를 들어 99999일)로 설정할 수 있다. 이는 관찰 종료까지 피험자를 추적 관찰하는 것을 의미한다. 이러한 연구 설계를 때로는 배정된대로 intent-to-treat 설계라고도 한다.
기준 날짜 이후 절단 또는 결과 발생 전까지의 위험 노출 일 days at risk가 0일인 환자는 분석할 정보가 없기 때문에, 최소 관찰 기간 minimum days at risk은 보통 1일로 설정한다. 노출과 결과 발생에 대한 지연시간 latency이 알려져 있다면, 이러한 일수를 늘려 더 유익한 비율을 얻을 수도 있을 것이다. 이러한 설정은 무작위 임상 시험과 유사한 연구 설계를 위해서도 사용할 수 있다 (예를 들어, 임상시험에 참여한 피험자가 최소한 N일 동안은 관찰되었다고 할 때).
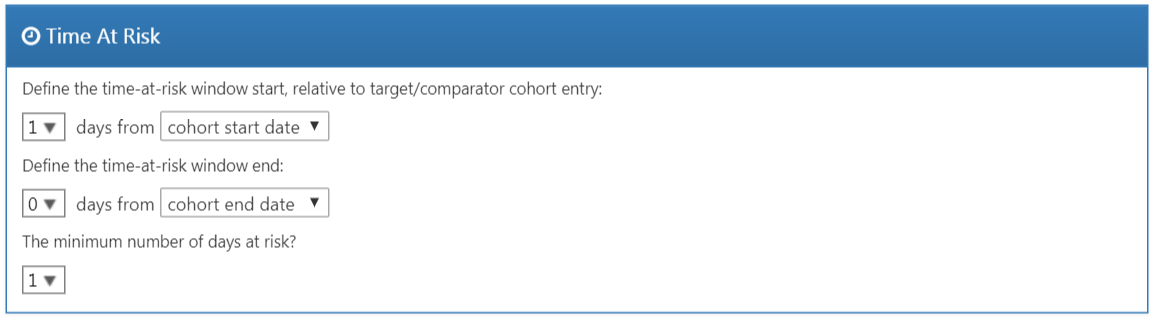
Figure 12.13: 위험 노출 기간 TAR 설정.
성향 점수 보정
극단적인 성향 점수를 갖는 피험자를 제거하여, 연구 대상을 잘라낼 trimming 수 있다. 상위 또는 하위 비율을 제거하도록 선택하거나, 선호도 점수 preference score가 지정된 범위를 벗어나는 피험자를 제거할 수 있다. 코호트 트리밍은 관측치를 제거하여 통계적 검정력을 감소시키기 때문에 일반적으로 권장되지는 않는다. IPTW를 사용할 때처럼 경우에 따라서는 트리밍을 하는 것이 바람직할 수 있다.
트리밍에 추가하여, 또는 트리밍 대신에 성향 점수를 이용해 계층화 stratification하거나 짝짓기 matching하도록 선택할 수 있다. 계층화할 때, 계층의 수 number of strata를 지정하고, 표적군, 대조군, 또는 전체 연구 집단을 기준으로 계층을 선택할지 여부를 지정해야 한다. 성향 점수 짝짓기 시, 표적군의 각 피험자와 일치시키기 위한 대조군에서의 최대 피험자 수 짝짓기 비율을 지정하여야 한다. 일반적인 값은 일대일 매칭 one-on-one matching의 경우 1이고, 일대다 매칭 variable-ratio matching의 경우 다수 (예를 들어 100) 이다. 또한, 매칭을 허용하는 성향 점수 사이의 최대 허용 차이를 뜻하는 캘리퍼 caliper를 지정해야 한다: 캘리퍼는 다음과 같이 서로 다른 캘리퍼 척도 caliper scales로 정의할 수 있다:
- 성향 점수 척도 propensity score scale: 성향 점수 자체
- 표준화 척도 standardized scale: 성향 점수 분포의 표준편차
- 표준화 로짓 척도 standardized logit scale: 성향 점수를 보다 정규분포로 만들기 위해 로그 변환한 성향 점수 분포의 표준편차
잘 모르겠다면, 기본값을 사용하거나, 이 주제에 대한 Austin (2011) 의 연구를 참고하기를 권장한다.
대규모 성향 점수 모델 large-scale propensity model을 최적화하는 것은 많은 컴퓨팅 자원을 요구할 수 있어서, 계산 시 샘플링한 자료를 이용하고자 할 수 있다. 기본 설정상, 표적 및 대조 코호트의 최대 크기는 250,000으로 설정되어 있다. 대부분의 연구에서 코호트의 전체 피험자 수가 이 한도에 도달하지 못할 것이다. 이보다 많은 데이터를 이용한다고 해서 더 나은 모델로 이어질 가능성은 희박하다. 비록 샘플링한 데이터를 이용해 성향 점수 모델을 적합하더라도 전체 집단에 대한 성향 점수는 여전히 계산된다는 점에 유의하자.
각 공변량이 치료배정과 상관성이 있는지 검사하겠습니까? Test each covariate for correlation with the target assignment?을 ’예 yes’로 설정하면, 만약 어떤 공변량이 치료 배정과 비정상적으로 높은 (양 또는 음의) 상관관계가 있으면 오류를 발생시키고 프로세스가 중단된다. 이것은 대규모 성향 점수 모델 계산이 완전히 끝날 때까지 기다리는 것을 방지할 수 있다. 매우 높은 단변량 상관관계를 발견하면 공변량을 검토하여 치료 배정과 상관관계가 높은 이유와 이를 제거해야 하는지를 결정할 수 있다.
모델 적합시에 정규화를 사용하시겠습니까? Use regularization when fitting the model? 매우 많은 공변량 (일반적으로 만 개 이상)이 성향 점수 모델 계산 시 사용된다. 이러한 대규모 모델을 적합하기 위해서는 정규화 regularization가 필요하다. 만약 수동으로 몇 개의 공변량만 사용된다면, 정규화를 사용하지 않아도 모델을 적합할 수 있다.
그림 12.14는 이 연구에 대한 우리의 선택을 보여준다. 최대 짝짓기 비율을 100으로 설정하여서 일-대-다 비율 짝짓기를 선택하였다.
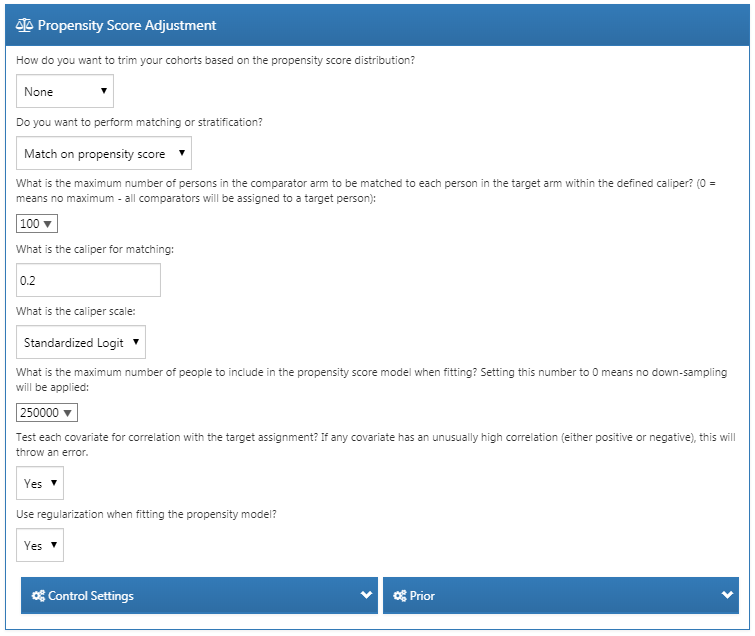
Figure 12.14: 성향 점수 보정 설정.
결과 모델 설정
먼저, 표적 코호트와 대조 코호트 간 결과의 상대 위험도 relative risk를 추정하기 위해 사용할 통계 모델을 명시할 필요가 있다. 12.1절에서 간략히 논의했던 것처럼, 콕스 Cox, 포아송 Poisson 및 로지스틱 회귀분석 중에서 선택할 수 있다. 예제에서는 콕스 비례 위험 모형Cox proportional hazards model을 사용하는데, 이 모델은 중도절단을 고려하여 첫 번째 사건까지의 시간 time to first event을 고려한다. 다음으로, 층화에 조건부 회귀분석을 사용할지 whether the regression should be conditioned on the strata를 명시할 필요가 있다. 쉽게 말하자면, 조건부 conditioning는 각 층 strata 내에서 추정치를 계산한 다음, 여러 층의 추정치를 결합한 것으로 생각하면 된다. One-to-one PS matching에서는 이러한 과정이 불필요할 것이며, 통계적 검정력 감소를 유발할 것이다. conditioning는 층화 stratification 또는 일-대-다 비율 짝짓기 시행시 필요하다.(역자 주: 다시 한 번 말하자면, 일대일 PS 매칭 시에는 conditioned on the strata 조건을 사용하지 말고, 일대다 매칭 또는 PS stratification 에는 conditioned on the strata을 사용하기 바란다.)
분석을 보정하기 위해 결과 모델 outcome model에 공변량을 추가할 수도 있다. 이것을 성향 점수 모델 사용에 추가하거나 성향 점수 짝짓기 대신에 수행할 수 있다. 하지만 보통 성향 점수 모델을 적합하기에는 충분한 수의 데이터가 있지만, 결과 모델을 적합하기에는 결과가 발생한 피험자가 적어 데이터가 모자라는 경우가 많다. 그래서 공변량을 결과 모델에 추가하지 말고, 결과 모델을 가급적 간단하게 유지하기를 권장한다.
성향 점수를 이용해 층화하거나 매칭하는 대신에 역 확률 치료 가중치 inverse probability of treatment weighting, IPTW를 사용할 수도 있다.
만약 모든 공변량을 결과 모델에 추가한다면, 공변량이 매우 많기 때문에 결과 모델 적합 시 정규화를 이용하는 것이 합리적일 것이다. 편향이 없는 추정을 위해서 치료 변수 자체에는 정규화가 적용되지 않음에 유의하자.
그림 12.15는 이 연구에 대한 선택을 보여준다. 일-대-다 비율 짝짓기를 사용하기 때문에, 층화에 조건부 회귀분석 condition the regression on the strata (다른 말로 matched sets)를 해야 함에 주목하자.
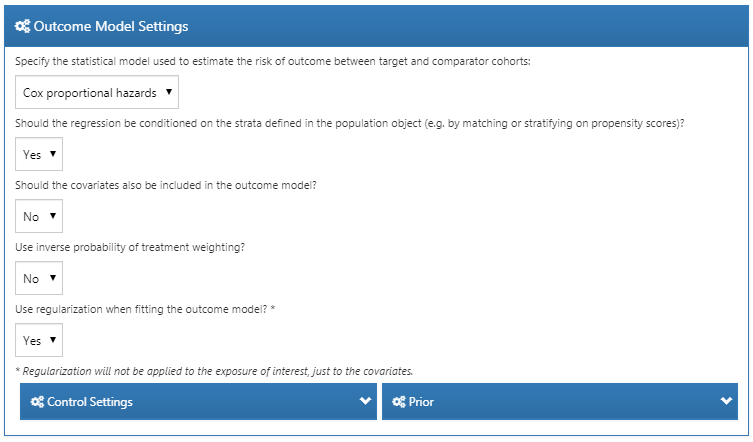
Figure 12.15: 결과 모델 설정
12.7.3 평가 설정
18장에서 기술한 바와 같이, 음성 대조군 및 양성 대조군은 연구자가 세팅한 분석방법론에 대한 운영 특성을 평가하고 경험적 보정을 수행하기 위하여 추가하여야 한다.
음성 대조군 결과 코호트 정의
12.7.1절에서 우리는 음성 대조군을 지정하는 concept set을 선택했다. concept을 지정하는 것뿐 아니라, 분석을 위해서는 concept을 기반으로 코호트를 생성하는 프로세스가 필요하다. ATLAS는 세 가지 선택 사항을 가진 표준 프로세스를 제공한다. 첫 번째 선택은 모든 발생을 사용할지 또는 concept의 첫 번째 발생 만을 사용할지 여부이다. 두 번째 선택은 하위 개념의 발생을 포함할지 여부를 결정한다. 하위 개념의 발생을 포함하면, 예를 들어 하위 개념 “내성 발톱 ingrown nail of foot”의 발생은 상위 개념 “내성 손톱 ingrown nail”의 발생으로 간주한다. 세 번째 선택사항은 개념을 찾을 때 고려할 도메인을 지정한다.

Figure 12.16: 음성 대조 결과 코호트 정의 설정.
양성 대조군 합성
음성 대조군 외에도 양성 대조군도 포함할 수 있는데, 양성 대조군은 알려진 효과 크기 effect size와 함께 인과적 영향 causal effect이 존재하는 것으로 보이는 노출-결과 쌍 exposure-outcome pair을 뜻한다. 여러 가지 이유로 실제 양성 대조군 설정은 문제가 있기 때문에, 대신 18장에서 설명한 대로 음성 대조군을 기반으로 합성된 양성 대조군을 사용한다. 양성 대조군 합성 여부를 선택할 수 있다. 만약 “예”를 선택하면, 반드시 모형 유형 model type을 선택해야 하는데, 현재는 “Poisson”과 “survival”을 지원하고 있다. 이 예제에서는 생존 (콕스) 분석을 시행하기 때문에, 양성 대조군 합성 시에도 “survival”을 선택하도록 하자. 양성 대조군 합성 시 가급적 분석 추정 설정에서 사용된 값을 비슷하게 사용하였다 (minimum required continuous observation prior to exposure, should only the first exposure be included, should only the first outcome be included, remove people with prior outcomes). 그림 12.15를 통해 양성 대조군 합성을 위한 설정을 참조할 수 있다.
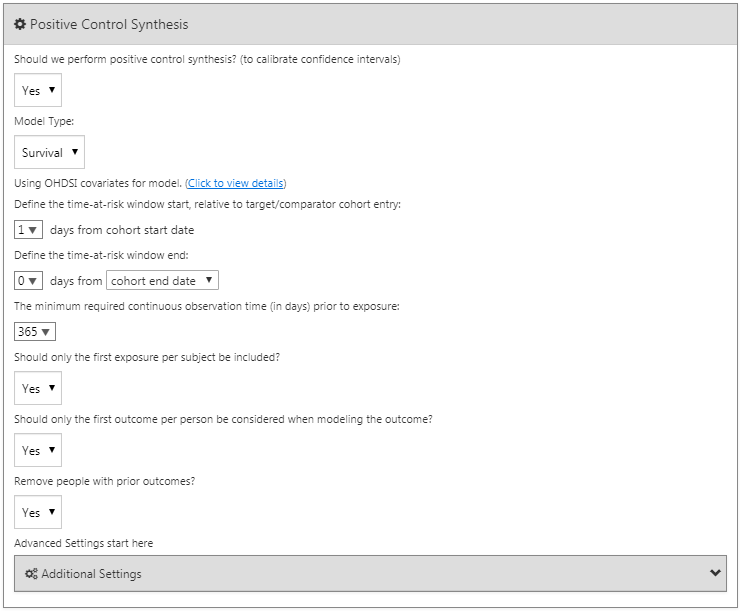
Figure 12.17: 음성 대조 결과 코호트 정의 설정.
12.7.4 연구 패키지 실행
이제 연구를 완전히 정의했으므로, 실행 가능한 R 패키지로 추출할 수 있다. 이 패키지에는 CDM 데이터가 있는 사이트에서 연구를 실행하는데 필요한 모든 것이 들어있다. 여기에는 분석을 실행하기 위한 R 코드뿐만 아니라 표적, 대조 및 결과 코호트, 음성 대조군을 정의하기 위한 개념 군과 코호트 생성 프로세스가 포함된다. 패키지를 생성하기 전에 연구를 저장한 다음, Utilities 탭을 클릭하면, 수행될 일련의 분석을 검토할 수 있다. 앞서 언급했듯이, 개개의 비교와 분석 설정의 조합은 각각의 분석 결과를 생성할 것이다. 이번 예시에서는 성향 점수 매칭을 사용하여 두 가지 분석을 지정하였다: 급성 심근경색 위험에 대한 ACEi 대 THZ 비교, 혈관 부종에 대한 ACEi 대 THZ 비교.
“Download”를 클릭하여 zip 파일을 다운로드하기 위해, 패키지의 이름을 입력해야 한다. zip 파일에는 R 패키지의 일반적인 필수 폴더 구조와 함께, R 패키지가 포함되어 있다. (Wickham 2015) 이 패키지를 사용하려면 R Studio를 사용하는 것이 좋다. R Studio를 로컬로 실행하는 경우 파일의 압축을 푼 다음, .Rproj 파일을 더블 클릭하여 R Studio에서 연다. R Studio 서버에서 R Studio를 실행하는 경우,  버튼을 클릭하여 파일을 업로드하고 압축을 해제한 다음, .Rproj 파일을 클릭하여 프로젝트를 연다.
버튼을 클릭하여 파일을 업로드하고 압축을 해제한 다음, .Rproj 파일을 클릭하여 프로젝트를 연다.
R Studio에서 프로젝트를 열면 README 파일을 열고 파일의 지침을 따라 할 수 있다. 모든 파일 경로를 시스템의 기존 경로로 변경하는 것을 잊지 말자.
연구를 진행할 때 나타날 수 있는 흔한 오류 메시지는 “공변량과 치료가 높은 상관관계를 보임 High correlation between covariate(s) and treatment detected”이다. 이는 성향 모델을 적용했을 때 일부 공변량이 노출과 높은 상관관계가 있음을 나타낸다. 오류 메시지에 언급된 공변량을 검토하고 적절한 경우 해당 공변량을 공변량 집합에서 제외하면 된다. (12.1.2절 참조)
12.8 R을 사용한 연구 구현하기
ATLAS를 사용하여 연구를 실행하는 R 코드를 작성하는 대신 R 코드를 직접 작성할 수도 있다. 이는 ATLAS를 이용하는 것보다, 훨씬 큰 유연성을 제공할 수 있다. 예를 들어 사용자 정의 공변량 또는 선형 결과 모델을 사용하려면 사용자 정의 R 코드를 작성하고 이를 OHDSI R 패키지가 제공하는 기능과 결합해야 한다.
예제 연구에서, 우리는 연구를 수행하기 위해 CohortMethod 패키지를 사용할 것이다. CohortMethod는 CDM 데이터베이스에서 필요한 데이터를 추출하고 성향 점수 모델에 대규모의 공변량 집합을 사용할 수 있다. 다음 예시에서는 혈관 부종만을 결과로 사용할 것이다. 12.8.6절에서는 이것이 어떻게 급성 심근경색과 음성 대조군 결과를 포함하도록 확장될 수 있는지 기술한다.
12.8.1 코호트 생성
먼저 표적, 대조 및 결과 코호트를 생성 Instantiation해야 한다. 코호트 실체화 방법은 10장에서 자세히 기술되어 있다. 부록에서 표적 (부록 B.2), 대조 (부록 B.5) 및 결과 (부록 B.4) 코호트의 정의 전체를 제공한다. ACEi, THZ 및 혈관 부종 코호트가 scratch.my_cohorts라고 명명된 테이블에서 코호트 정의 ID 1, 2, 3을 가지고 함께 실체화되었다고 가정한다.
12.8.2 데이터 추출
먼저 R에게 서버에 연결하는 방법을 알려줘야 한다. CohortMethod createConnectionDetails 라는 함수를 제공하는 DatabaseConnector 패키지를 이용한다. 다양한 데이터베이스 관리 시스템에 필요한 설정에 대해 알아보기 위하여 ?createConnectionDetails를 입력해보자. 예를 들어, 아래 코드를 사용하여 PostgreSQL 데이터베이스에 연결할 수 있다.
library(CohortMethod)
connDetails <- createConnectionDetails(dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
cdmDbSchema <- "my_cdm_data"
cohortDbSchema <- "scratch"
cohortTable <- "my_cohorts"
cdmVersion <- "5"마지막 네 줄은 cdmDbSchema, cohortDbSchema 및 cohortTable 변수와 CDM 버전을 정의한다. 이를 이용하여 이후에 CDM 데이터가 존재하는 위치, 연구용 코호트가 생성된 위치, 그리고 사용된 CDM 버전 정보를 R에 전달한다. Microsoft SQL Server의 경우 데이터베이스 스키마는 데이터베이스와 스키마 schema를 모두 지정해야 한다 (예를 들어 cdmDbSchema <- "my_cdm_data.dbo").
이제 CorhotMethod를 이용해 코호트를 추출하고, 공변량을 구성하며, 분석에 필요한 모든 데이터를 추출할 수 있다.
# target and comparator ingredient concepts:
aceI <- c(1335471,1340128,1341927,1363749,1308216,1310756,1373225,
1331235,1334456,1342439)
thz <- c(1395058,974166,978555,907013)
# Define which types of covariates must be constructed:
cs <- createDefaultCovariateSettings(excludedCovariateConceptIds = c(aceI,
thz),
addDescendantsToExclude = TRUE)
#Load data:
cmData <- getDbCohortMethodData(connectionDetails = connectionDetails,
cdmDatabaseSchema = cdmDatabaseSchema,
oracleTempSchema = NULL,
targetId = 1,
comparatorId = 2,
outcomeIds = 3,
studyStartDate = "",
studyEndDate = "",
exposureDatabaseSchema = cohortDbSchema,
exposureTable = cohortTable,
outcomeDatabaseSchema = cohortDbSchema,
outcomeTable = cohortTable,
cdmVersion = cdmVersion,
firstExposureOnly = FALSE,
removeDuplicateSubjects = FALSE,
restrictToCommonPeriod = FALSE,
washoutPeriod = 0,
covariateSettings = cs)
cmData## CohortMethodData object
##
## Treatment concept ID: 1
## Comparator concept ID: 2
## Outcome concept ID(s): 3많은 파라미터가 있지만, CohortMethod 매뉴얼에 모두 설명되어 있다. createDefaultCovariateSettings 함수는 FeatureExtraction 패키지에 설명되어 있다. 간단히 말해, 코호트를 포함하는 테이블에 함수를 지정하고 해당 테이블의 cohort definition ID가 표적, 대조 및 결과 코호트를 식별하도록 지정한다. index data 당일 혹은 이전에 발견된 모든 진단명, 약물 노출, 시술 기록에 대한 공변량을 포함하여 공변량의 기본 모음을 구성하도록 지시한다. 12.1절에서 언급했듯이, 공변량 집합에서 표적 및 대조 치료를 배제하여야 하며, 이 예제에서는 두 가지의 약물군에 해당하는 성분명 ingredient을 나열하여 이를 달성한다. 또한, FeatureExtraction에 모든 하위 개념을 배제하도록 지시하여 나열된 성분을 포함하는 모든 약물 노출을 공변량에서 제외한다.
코호트, 결과 및 공변량에 대한 모든 데이터는 서버에서 추출되어 cohortMethodData object에 저장된다. 이러한 object는 ff 패키지를 사용하여 8.4.2절에서 언급한 것처럼 데이터가 크더라도, R이 메모리를 모두 소모하지 않도록 보장한다.
일반 함수 summary() 를 사용하여 추출한 데이터에 대한 추가 정보를 볼 수 있다:
summary(cmData)## CohortMethodData object summary
##
## Treatment concept ID: 1
## Comparator concept ID: 2
## Outcome concept ID(s): 3
##
## Treated persons: 67166
## Comparator persons: 35333
##
## Outcome counts:
## Event count Person count
## 3 980 891
##
## Covariates:
## Number of covariates: 58349
## Number of non-zero covariate values: 24484665cohortMethodData 파일을 만들면 상당한 시간이 걸릴 수 있으며 향후 세션을 위해 저장하는 것이 좋다. cohortMethodData가 ff를 사용하므로 R의 일반 저장 기능을 사용할 수 없다. 대신에, saveCohortMethodData() 함수를 사용하도록 한다.
saveCohortMethodData(cmData, "AceiVsThzForAngioedema")loadCohortMethodData() 함수를 사용하여 향후 세션에서 데이터를 로드할 수 있다.
새로운 사용자 정의하기
일반적으로 새로운 사용자 new user는 해당 약물 (표적군 또는 대조군 내에서)의 최초 사용으로 정의되며, 최초 사용을 보장하는 확률을 높이기 위해 최초 사용 이전의 최소 기간을 뜻하는 휴약기간 washout period를 사용할 수 있다. CohortMethod 패키지를 사용할 때 다음 세 가지 방법으로 새로운 사용자를 정의할 수 있다.
- 코호트 정의 시 지정
getDbCohortMethodData함수를 사용하여 코호트를 로딩할 때,firstExposureOnly,removeDuplicateSubjects,restrictToCommonPeriod,washoutPeriod전달 인자 argument를 사용하여 지정- 연구 집단 정의 시
createStudyPopulation함수를 이용하여 지정
첫 번째 방법의 장점은 입력 코호트 input cohort가 이미 CohortMethod 패키지 밖에서 완전히 정의되어 있고, 외부 코호트 특성화 도구가 이 분석에 사용된 것과 동일한 코호트에서 사용될 수 있다는 것이다. 두 번째, 세 번째 방법의 장점은 CDM에서 DRUG_ERA 테이블을 직접 사용할 수 있는 등, 새로운 사용자를 정의하는 데 생기는 문제를 줄여준다는 것이다. 최초 사용에 대한 데이터만 가져올 것이기 때문에 두 번째 방법이 세 번째 방법보다 더 효율적이다. 세 번째 방법이 컴퓨터 메모리 측면에서 덜 효율적이긴 하지만, 원래 코호트를 연구 대상군과 비교할 수 있다.
12.8.3 연구군 정의
일반적으로, 표적, 대조 코호트와 결과 코호트는 서로 독립적으로 정의된다. 효과 크기 추정치를 생성하려면 노출 전에 결과가 있는 피험자는 제거하고 정의한 위험 노출 기간 risk window에 발생하는 결과 만을 고려하는 등의 방법을 추가해야 한다. 이를 위하여 createStudyPopulation 함수를 사용할 수 있다.
studyPop <- createStudyPopulation(cohortMethodData = cmData,
outcomeId = 3,
firstExposureOnly = FALSE,
restrictToCommonPeriod = FALSE,
washoutPeriod = 0,
removeDuplicateSubjects = "remove all",
removeSubjectsWithPriorOutcome = TRUE,
minDaysAtRisk = 1,
riskWindowStart = 1,
startAnchor = "cohort start",
riskWindowEnd = 0,
endAnchor = "cohort end")코호트 정의에서 이미 이러한 기준을 적용했기 때문에 firstExposureOnly와 removeDuplicateSubjects를 FALSE로, washoutPeriod를 0으로 설정하였다. 사용할 결과 ID를 지정하고, 위험노출 기간 risk window 시작일 전에 결과가 발생한 사람은 제거할 것이다. 위험노출 기간은 코호트 시작일 다음 날부터 시작하는 것으로 정의하고 (riskWindowStart = 1 및 startAnchor = "cohort start"), 코호트 노출이 끝날 때 종료되도록 설정했다 (riskWindowEnd = 0 and endAnchor = "cohort end"). 이것은 코호트 정의에서 치료 노출 종료로써 정의되었었다. 위험노출 기간은 관찰 종료 또는 연구 종료일에 자동으로 절단됨에 유의하자. 또한 위험노출 기간이 0일인 피험자도 제거했다. 연구 대상자에 남아 있는 사람의 수를 보려면, getAttritionTable 함수를 사용하면 된다.
getAttritionTable(studyPop)## description targetPersons comparatorPersons ...
## 1 Original cohorts 67212 35379 ...
## 2 Removed subs in both cohorts 67166 35333 ...
## 3 No prior outcome 67061 35238 ...
## 4 Have at least 1 days at risk 66780 35086 ...12.8.4 성향 점수
getDbcohortMethodData() 함수로 생성된 공변량을 사용하여 성향 점수 모델을 적합할 수 있으며, 피험자별 성향 점수를 계산할 수 있다.
ps <- createPs(cohortMethodData = cmData, population = studyPop)createPs 함수는 대규모 정규화 로지스틱 회귀분석 large-scale regularized logistic regression을 적합화하기 위해 Cyclops 패키지를 사용한다. 성향 점수 모델을 적합화하기 위해, Cyclops는 prior의 분산을 지정하는 하이퍼-파라미터 값을 알아야 한다. 기본값으로 Cyclops는 최적의 하이퍼-파라미터를 추정하기 위해 교차 검증 cross-validation을 사용할 것이다. 다만, 이 작업은 오랜 시간이 걸릴 수 있음을 알아 두어야 한다. createPs 함수의 prior 및 control의 매개변수를 사용하여 병렬 처리를 사용하여 교차 유효성 검사 속도를 높이는 등 Cyclops의 동작을 지정할 수 있다.
예제에서는 성향점수 기반의 일-대-다 비율 짝짓기를 수행하였다:
matchedPop <- matchOnPs(population = ps, caliper = 0.2,
caliperScale = "standardized logit", maxRatio = 100)위와 같은 설정 대신에, trimByPs, trimByPsToEquipoise 또는 stratifyByPs 함수에서 성향 점수를 사용할 수도 있다.
12.8.5 결과 모델
결과 모델은 결과와 어떠한 변수가 관련이 있는지 설명하는 모델이다. 엄격한 가정하에서 치료 변수에 대한 계수 coefficient는 인과적 영향 causal effect으로 해석될 수 있다. 이 경우, 짝짓기 된 군에 대해 층화 조건부 콕스 비례 위험 모델 Cox proportional hazards model conditioned (stratified) on the matched set을 이용하였다.
outcomeModel <- fitOutcomeModel(population = matchedPop,
modelType = "cox",
stratified = TRUE)
outcomeModel## Model type: cox
## Stratified: TRUE
## Use covariates: FALSE
## Use inverse probability of treatment weighting: FALSE
## Status: OK
##
## Estimate lower .95 upper .95 logRr seLogRr
## treatment 4.3203 2.4531 8.0771 1.4633 0.30412.8.6 다중 분석 실행하기
음성 대조군을 포함하여 다수의 결과에 대해 하나 이상의 분석을 수행하기 원할 수 있다. CohortMethod는 이러한 연구를 효율적으로 수행하는 기능을 제공한다. 이것은 다중 분석 실행에 대한 패키지 설명(package vignette on running multiple analyses)에 자세히 설명되어 있다. 간단히 말해서 먼저 필요한 코호트가 모두 생성되어 있다면, 분석하고자 하는 모든 표적-대조-결과 조합을 미리 지정하여 한꺼번에 실행 할 수 있다.
# Outcomes of interest:
ois <- c(3, 4) # Angioedema, AMI
# Negative controls:
ncs <- c(434165,436409,199192,4088290,4092879,44783954,75911,137951,77965,
376707,4103640,73241,133655,73560,434327,4213540,140842,81378,
432303,4201390,46269889,134438,78619,201606,76786,4115402,
45757370,433111,433527,4170770,4092896,259995,40481632,4166231,
433577,4231770,440329,4012570,4012934,441788,4201717,374375,
4344500,139099,444132,196168,432593,434203,438329,195873,4083487,
4103703,4209423,377572,40480893,136368,140648,438130,4091513,
4202045,373478,46286594,439790,81634,380706,141932,36713918,
443172,81151,72748,378427,437264,194083,140641,440193,4115367)
tcos <- createTargetComparatorOutcomes(targetId = 1,
comparatorId = 2,
outcomeIds = c(ois, ncs))
tcosList <- list(tcos)다음으로, 하나의 결과를 분석하는 이번 예제에서 전에 설명한 다양한 함수를 호출하기 위해 어떤 조절인자 argument를 사용해야 하는가를 지정한다.
aceI <- c(1335471,1340128,1341927,1363749,1308216,1310756,1373225,
1331235,1334456,1342439)
thz <- c(1395058,974166,978555,907013)
cs <- createDefaultCovariateSettings(excludedCovariateConceptIds = c(aceI,
thz),
addDescendantsToExclude = TRUE)
cmdArgs <- createGetDbCohortMethodDataArgs(
studyStartDate = "",
studyEndDate = "",
firstExposureOnly = FALSE,
removeDuplicateSubjects = FALSE,
restrictToCommonPeriod = FALSE,
washoutPeriod = 0,
covariateSettings = cs)
spArgs <- createCreateStudyPopulationArgs(
firstExposureOnly = FALSE,
restrictToCommonPeriod = FALSE,
washoutPeriod = 0,
removeDuplicateSubjects = "remove all",
removeSubjectsWithPriorOutcome = TRUE,
minDaysAtRisk = 1,
startAnchor = "cohort start",
addExposureDaysToStart = FALSE,
endAnchor = "cohort end",
addExposureDaysToEnd = TRUE)
psArgs <- createCreatePsArgs()
matchArgs <- createMatchOnPsArgs(
caliper = 0.2,
caliperScale = "standardized logit",
maxRatio = 100)
fomArgs <- createFitOutcomeModelArgs(
modelType = "cox",
stratified = TRUE)그럼 다음 이를 하나의 분석 설정 object로 결합하는데, 이것은 고유 분석 ID(unique analysis ID)와 몇 가지 설명을 제공한다. 하나 이상의 분석 설정 object를 하나의 list로 결합할 수 있다.
cmAnalysis <- createCmAnalysis(
analysisId = 1,
description = "Propensity score matching",
getDbCohortMethodDataArgs = cmdArgs,
createStudyPopArgs = spArgs,
createPs = TRUE,
createPsArgs = psArgs,
matchOnPs = TRUE,
matchOnPsArgs = matchArgs
fitOutcomeModel = TRUE,
fitOutcomeModelArgs = fomArgs)
cmAnalysisList <- list(cmAnalysis)이제 모든 비교 및 분석 설정을 포함하여 연구를 실행할 수 있다.
result <- runCmAnalyses(connectionDetails = connectionDetails,
cdmDatabaseSchema = cdmDatabaseSchema,
exposureDatabaseSchema = cohortDbSchema,
exposureTable = cohortTable,
outcomeDatabaseSchema = cohortDbSchema,
outcomeTable = cohortTable,
cdmVersion = cdmVersion,
outputFolder = outputFolder,
cmAnalysisList = cmAnalysisList,
targetComparatorOutcomesList = tcosList)result object에는 작성된 모든 인공물 artifact에 대한 참조가 들어 있다. 예를 들어, 급성 심근경색의 결과 모델을 추출할 수 있다.
omFile <- result$outcomeModelFile[result$targetId == 1 &
result$comparatorId == 2 &
result$outcomeId == 4 &
result$analysisId == 1]
outcomeModel <- readRDS(file.path(outputFolder, omFile))
outcomeModel## Model type: cox
## Stratified: TRUE
## Use covariates: FALSE
## Use inverse probability of treatment weighting: FALSE
## Status: OK
##
## Estimate lower .95 upper .95 logRr seLogRr
## treatment 1.1338 0.5921 2.1765 0.1256 0.332또한 하나의 명령으로 모든 결과에 대한 효과 크기 추정치를 검색할 수 있다:
summ <- summarizeAnalyses(result, outputFolder = outputFolder)
head(summ)## analysisId targetId comparatorId outcomeId rr ...
## 1 1 1 2 72748 0.9734698 ...
## 2 1 1 2 73241 0.7067981 ...
## 3 1 1 2 73560 1.0623951 ...
## 4 1 1 2 75911 0.9952184 ...
## 5 1 1 2 76786 1.0861746 ...
## 6 1 1 2 77965 1.1439772 ...12.9 연구 결과물
결과물로 나오는 추정치는 몇 가지 가정이 충족된 경우에만 유효하다. 유효성을 검증하기 위하여 다양한 진단 기준을 사용할 것이다. 이것은 ATLAS로 생성된 R 패키지를 이용한 결과에 자동으로 포함되어 있으며, 특정 R 함수를 활용하여 즉석에서 생성할 수도 있다.
12.9.1 성향 점수 및 모델
성향 점수 기반의 짝짓기 이후 먼저 표적 코호트와 대조 코호트가 어느 정도 비슷한지를 평가할 필요가 있다. 이를 위해 성향 점수 모델에 대한 Area Under the Receiver Operator Curve(AUC) 통계값을 계산할 수 있다. AUC 1은 기저 공변량에 근거해 치료배정이 완전히 예측 가능하다는 것을 나타내므로, 두 군은 비교할 수 없다. computePsAuc 함수를 사용하여 AUC를 계산할 수 있는데, 우리의 예제에서는 0.79이다. plotPs 함수를 사용하여 그림 12.18과 같이 선호 점수 분포 preference score distribution를 생성할 수도 있다. 많은 피험자에 대해 그들이 받을 치료가 예측 가능했다는 것을 알 수지만 또한 많은 수의 중첩이 있다. 이는 조정을 통해 비교 가능한 군을 선택할 수 있음을 나타낸다.
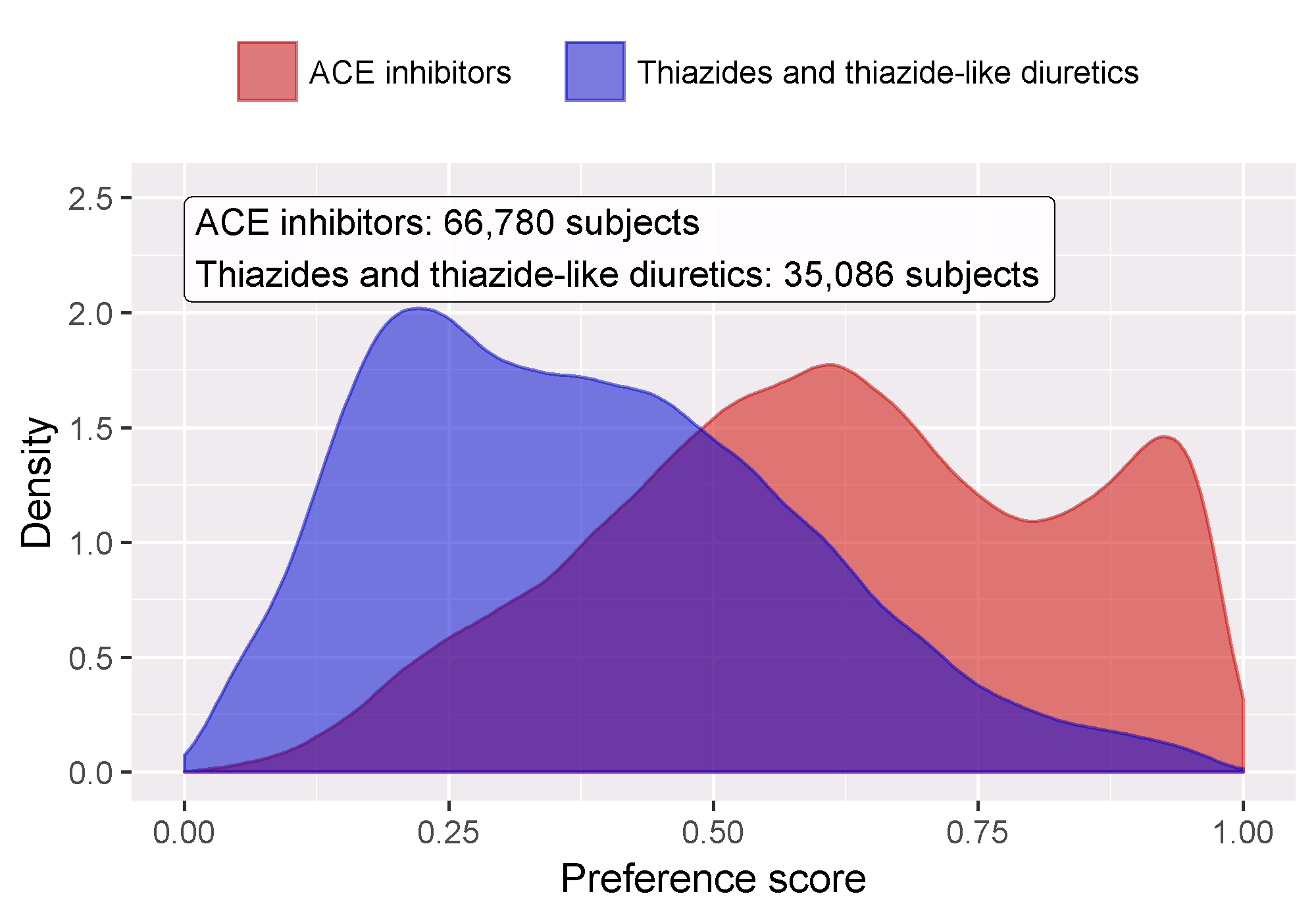
Figure 12.18: 성향 점수 분포.
일반적으로 성향 점수 모델 자체를 검사하는 것이 좋으며, 특히 모델이 매우 예측적일 경우에는 더욱 그렇다. 그렇게 하면 어떤 변수가 가장 예측적인지를 알 수 있다. 표 12.7은 성향 모델에서 상위 예측 변수를 보여준다. 변수가 너무 예측적일 경우, CohortMethod 패키지는 이미 완벽하게 예측된 모델을 적합하려고 시도하기보단 유용한 정보를 주는 에러를 발생시킬 것이다.
| Beta | 공변량 |
|---|---|
| -1.42 | condition_era group during day -30 through 0 days relative to index: Edema |
| -1.11 | drug_era group during day 0 through 0 days relative to index: Potassium Chloride |
| 0.68 | age group: 05-09 |
| 0.64 | measurement during day -365 through 0 days relative to index: Renin |
| 0.63 | condition_era group during day -30 through 0 days relative to index: Urticaria |
| 0.57 | condition_era group during day -30 through 0 days relative to index: Proteinuria |
| 0.55 | drug_era group during day -365 through 0 days relative to index: INSULINS AND ANALOGUES |
| -0.54 | race = Black or African American |
| 0.52 | (Intercept) |
| 0.50 | gender = MALE |
12.9.2 공변량 균형
성향점수를 사용하는 목적은 두 군을 비교할 수 있게 만드는 (또는 적어도 비교할 수 있는 군을 선택하는) 것이다. 기저 공변량이 조정 후 실제로 균형을 이루고 있는지 등을 확인하여 이 목적이 달성되었는지 입증해야 한다. computeCovariateBalance 및 plotCovariateBalanceScatterPlot 함수를 사용하여 그림 12.19를 생성할 수 있다. 한 가지 주요한 원칙은 성향 점수 조정 후 공변량이 0.1보다 큰 표준 차이 값 absolute standardized difference of means을 가져서는 안 된다는 것이다. 여기서는 성향점수 짝짓기 이전에 상당한 불균형이 있었음에도 불구하고, 짝짓기 이후에는 이 기준을 충족한다는 것을 알 수 있다.
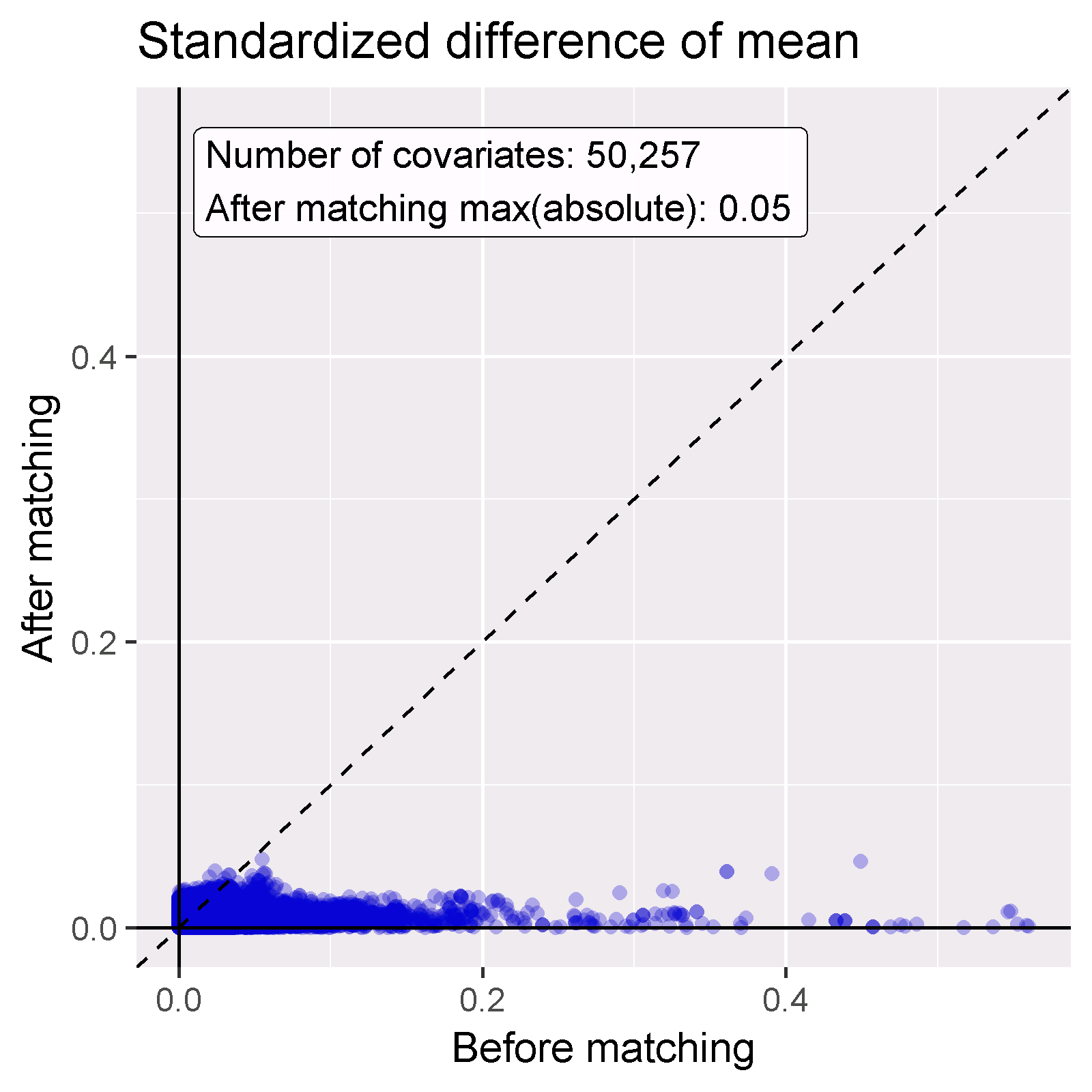
Figure 12.19: 공변량 균형, 성향 점수 매칭 전과 후의 절대 표준화 평균 차이를 보여준다. 각 점은 공변량을 나타낸다.
12.9.3 추적 기간과 검정력
결과 모델을 적합하기 전에, 특정 효과 크기를 감지할 수 있는 충분한 검정력이 있는지 파악해보고 싶을 수 있다. 연구 대상 집단이 완전히 정의되면, 다양한 포함/제외 기준 (예를 들어 이전 결과 없음)과 매칭 및/또는 트리밍으로 인한 손실을 고려하여 이러한 검정력 계산을 수행하는 것이 좋다. 그림 12.20과 같이 drawAttritionDiagram 함수를 사용하여 연구에서 피험자의 소모를 볼 수 있다.
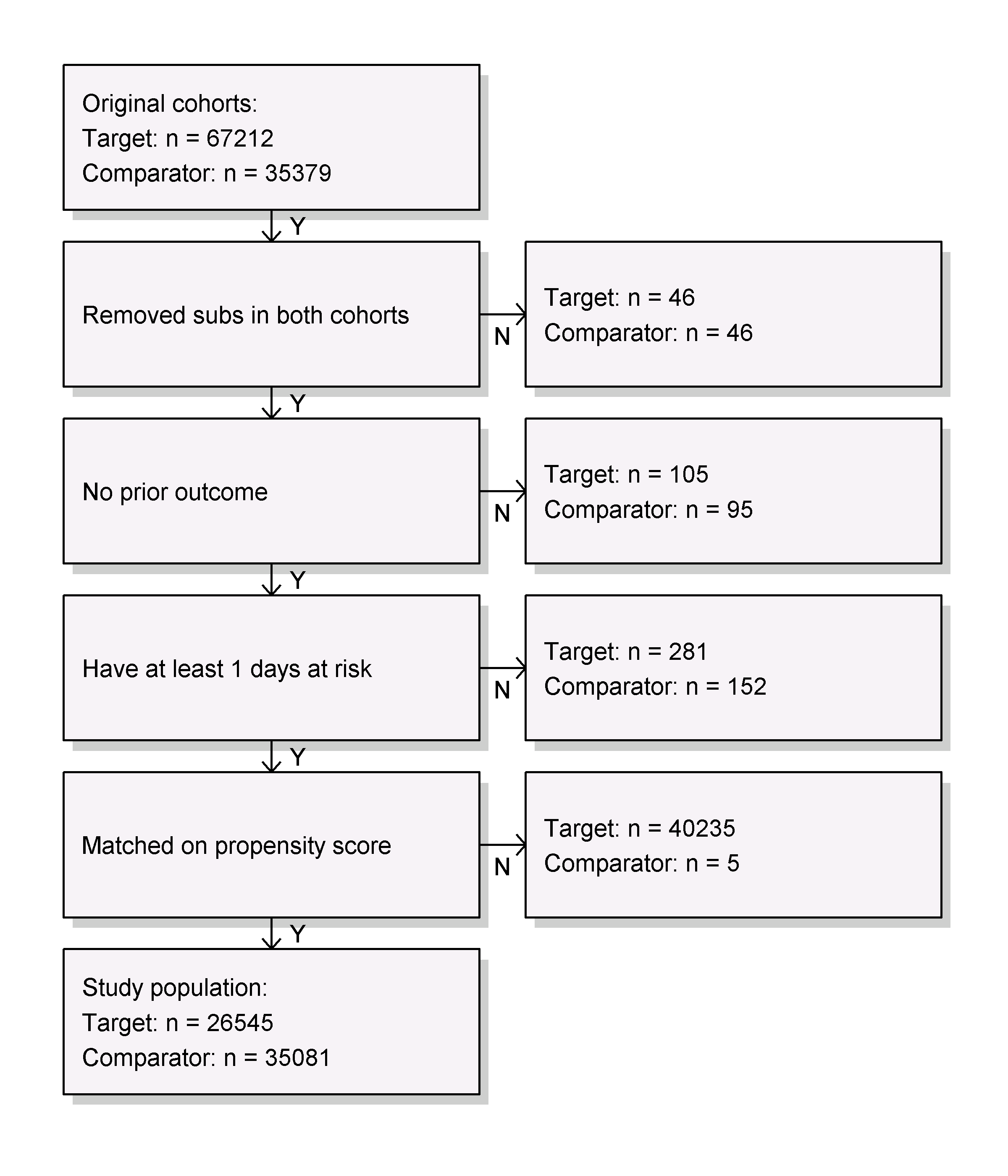
Figure 12.20: Attrition diagram. 맨 위에 표시된 개수는 우리의 목표와 대조군 코호트 정의를 충족하는 개수이다. 하단의 개수는 결과 모델에 입력되는 개수로서, 이 경우는 콕스 회귀 분석이다.
후향적 연구에서 표본 크기가 고정되어 있고 (데이터가 이미 수집된 상태이므로), 실제 효과 크기를 알 수 없으므로, 예상 효과 크기에 대한 검정력을 계산하는 것은 의미가 없다. 대신 CohortMethod 패키지는 computeMdrr 함수를 제공하여 minimum detectable relative risk(MDRR)를 계산한다. 이 사례에서 MDRR은 1.69이다.
추적 기간 follow-up 데이터를 더 잘 이해하기 위해서는 추적 기간의 분포도 검사할 수 있다. 추적 기간을 위험 노출 기간으로 정의했으므로 결과 발생으로 인해서는 중도 절단되지 않는다. getFollowUpDistribution 그림 12.21과 같은 간단한 개괄을 제공한다. 이는 두 코호트의 follow-up time이 비슷하다는 것을 의미한다.
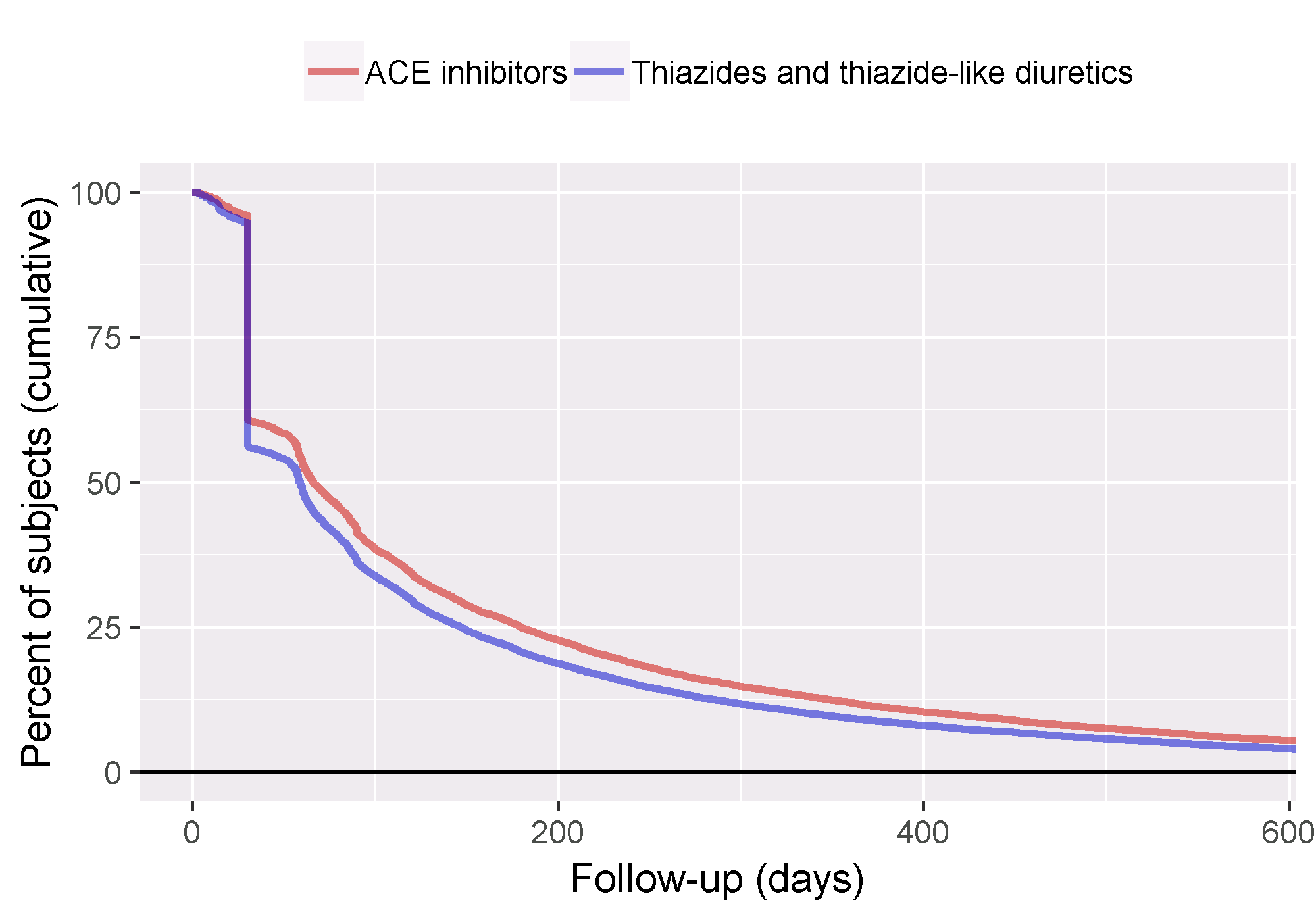
Figure 12.21: 표적 및 대조군 코호트의 추적 시간 분포.
12.9.4 Kaplan-Meier
마지막으로 한 가지 검사는 두 코호트에서 시간 경과에 따른 생존율을 보여주는 Kaplan-Meier plot을 검토하는 것이다. plotKaplanMeier 함수를 사용하여 그림 12.22를 만들 수 있는데, 여기서 예를 들면 위험 비례 가정이 성립하는지 확인할 수 있다. Kaplan-Meier plot은 성향점수별로 층화 또는 가중치를 자동으로 조정한다. 이 경우, 일-대-다 비율 짝짓기를 사용했으므로, 대조군의 생존 곡선이 조정되어 표적 군이 대조 약물에 노출되었을 경우 생존 곡선이 어떤 모습인지 모방하여 그려진다.
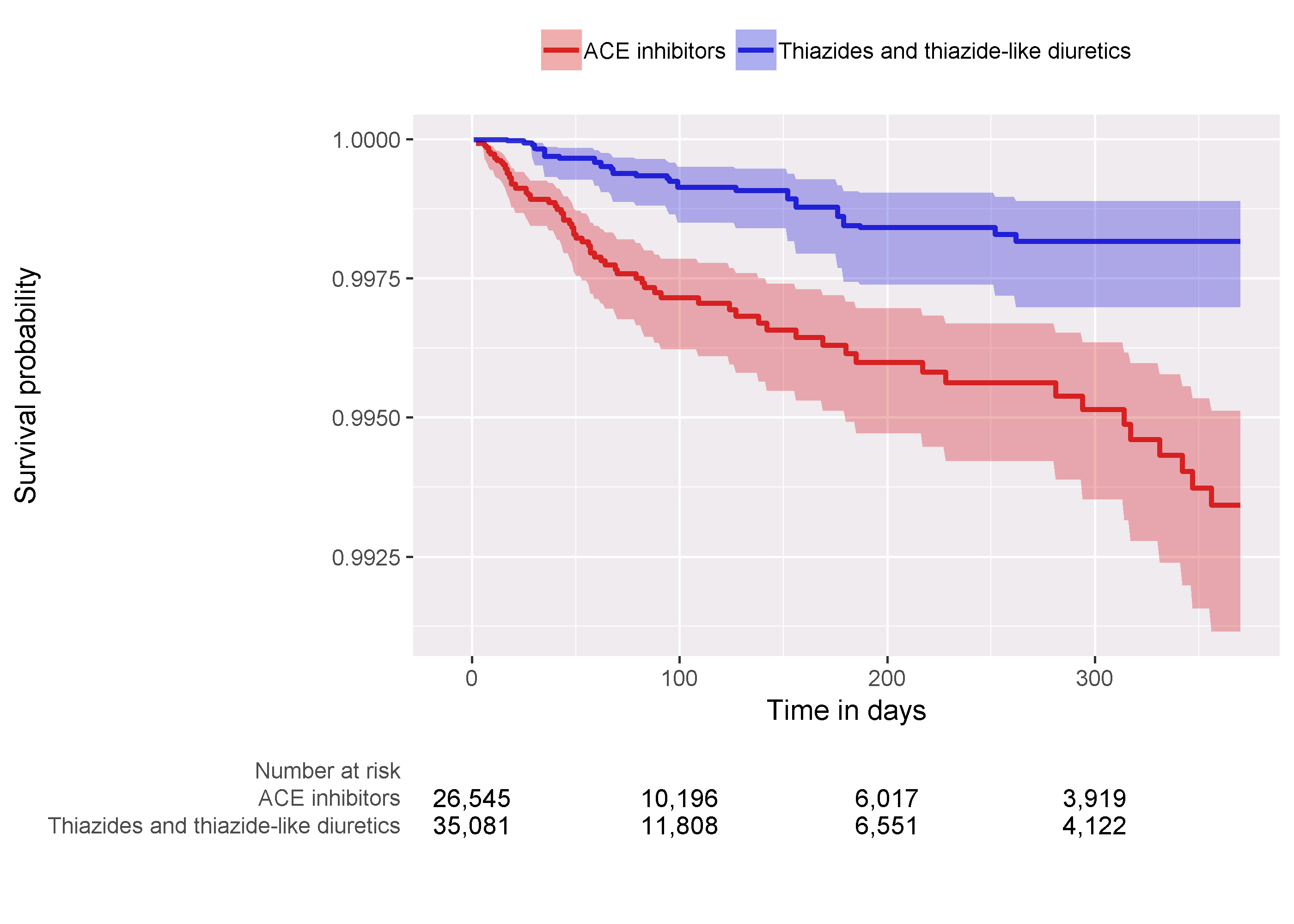
Figure 12.22: Kaplan-Meier plot.
12.9.5 효과 크기 추정치
혈관 부종에 대한 위험 비는 4.32 (95% 신뢰 구간: 2.45 - 8.08)이며, 이는 ACEi가 THZ와 비교하여 혈관 부종의 위험을 증가시키는 것을 의미한다. 마찬가지로, 심근경색에 대한 위험 비는 1.13 (95% 신뢰 구간: 0.59 - 2.18)이며, 심근경색에 대한 영향은 거의 또는 전혀 없음을 알 수 있다. 앞에서 검토한 것처럼 연구가 잘 수행됐는지를 검사하는 진단 방법은 의심의 여지가 없다. 그러나 궁극적으로 이러한 근거의 질과 신뢰 여부는 14장에서 설명한 대로 연구 진단이 커버하지 못하는 많은 요인에 달려 있다.
12.10 요약
인구 수준 추정은 관찰형 데이터의 인과 관계를 추론하는 것을 목적으로 한다.
반사실 counterfactual, 즉 피험자가 만일 표적 치료제에 노출되지 않았다거나, 또는 다른 대체 약물에 노출되었다면 어떤 일이 벌어졌을까라고 하는 것은 관찰할 수 없다.
각 연구 설계는 서로 다른 방식으로 반사실을 구성하는 것을 목적으로 한다.
- OHDSI 연구방법론 라이브러리 Methods Library에 구현된 다양한 연구설계는 적절한 반사실을 만들기 위한 가정이 충족되었는지 여부를 평가하는 진단 방법을 제공한다.
12.11 예제
전제조건
이 예제를 위해서는 R, R-studio, Java가 8.4.5절에서 설명한 바와 같이 설치되어 있어야 한다. 또한 다음과 같이 SqlRender, DatabaseConnector, Eunomia, CohortMethod 패키지를 모두 설치해야 된다.
install.packages(c("SqlRender", "DatabaseConnector", "devtools"))
devtools::install_github("ohdsi/Eunomia", ref = "v1.0.0")
devtools::install_github("ohdsi/CohortMethod")Eunomia 패키지는 당신의 로컬 R 세션에서 작동할 수 있도록 CDM 형태의 가상 데이터를 제공한다. 데이터베이스 접속은 다음과 같이 설정하면 된다.
connectionDetails <- Eunomia::getEunomiaConnectionDetails()CDM 데이터 스키마는 “main”이다. 이 연습문제는 또한 몇 가지 코호트를 이용한다. Eunomia 패키지의 createCohorts 함수를 이용하여 COHORT 테이블에 코호트를 생성할 수 있다.
Eunomia::createCohorts(connectionDetails)문제 정의
디클로페낙Diclofenac 새 사용자와 비교하였을 때 celecoxib 새 사용자의 위장 출혈 위험은 얼마인가?
celecoxib 새 사용자 코호트는 COHORT_DEFINITION_ID = 1 값을 가진다. 디클로페낙 새 사용자 코호트는 COHORT_DEFINITION_ID = 2 값을 가진다. 위장 출혈 코호트는 COHORT_DEFINITION_ID = 3 값을 가진다. Celecoxib와 디클로페낙의 성분 개념 ID는 각각 1118084과 1124300이다. 위험 노출 기간은 치료가 시작된 날부터 시작하며, 관찰이 종료될 때 멈춘다 (intent-to-treat 분석이라고 부른다).
Exercise 12.1 CohortMethod R 패키지를 사용하여, 공변량의 기본 모음을 사용하고 CDM에서 CohortMethodData 추출해 보라. CohortMethodData의 요약본을 생성해 보라.
Exercise 12.2 createStudyPopulation 기능을 사용하여 연구 집단를 생성하는데, 180일의 휴약기간를 가지며, 사전 결과를 가진 사람을 배제하고 두 코호트에 공통으로 나타나는 사람을 제거해야 한다. 사람의 수가 적어지는가?
Exercise 12.3 아무 조정을 사용하지 않고 Cox 비례 위험 모델을 만들어라. 이렇게 진행하면 무엇이 잘못되는가?
Exercise 12.4 성향 모델을 만들어라. 그 두 집단은 비교되는가?
Exercise 12.5 5개의 계층을 사용하여 PS 계층화를 수행하라. 공변량 균형은 달성되었는가?
Exercise 12.6 PS strata를 사용하여 Cox 비례 위험 모델을 구축하라. 조정되지 않은 모델과 결과가 다른 이유는 무엇인가?
제안된 답변은 부록 E.8에서 찾을 수 있다.
References
Austin, Peter C. 2011. “Optimal Caliper Widths for Propensity-Score Matching When Estimating Differences in Means and Differences in Proportions in Observational Studies.” Pharmaceutical Statistics 10 (2). Wiley Online Library: 150–61.
Farrington, C. P. 1995. “Relative incidence estimation from case series for vaccine safety evaluation.” Biometrics 51 (1): 228–35.
Farrington, C. P., Karim Anaya-Izquierdo, Heather J. Whitaker, Mounia N. Hocine, Ian Douglas, and Liam Smeeth. 2011. “Self-Controlled Case Series Analysis with Event-Dependent Observation Periods.” Journal of the American Statistical Association 106 (494). Taylor & Francis: 417–26. doi:10.1198/jasa.2011.ap10108.
Hernan, M. A., and J. M. Robins. 2016. “Using Big Data to Emulate a Target Trial When a Randomized Trial Is Not Available.” Am. J. Epidemiol. 183 (8): 758–64.
Hernan, M. A., S. Hernandez-Diaz, M. M. Werler, and A. A. Mitchell. 2002. “Causal knowledge as a prerequisite for confounding evaluation: an application to birth defects epidemiology.” Am. J. Epidemiol. 155 (2): 176–84.
Maclure, M. 1991. “The case-crossover design: a method for studying transient effects on the risk of acute events.” Am. J. Epidemiol. 133 (2): 144–53.
Magid, D. J., S. M. Shetterly, K. L. Margolis, H. M. Tavel, P. J. O’Connor, J. V. Selby, and P. M. Ho. 2010. “Comparative effectiveness of angiotensin-converting enzyme inhibitors versus beta-blockers as second-line therapy for hypertension.” Circ Cardiovasc Qual Outcomes 3 (5): 453–58.
Powers, B. J., R. R. Coeytaux, R. J. Dolor, V. Hasselblad, U. D. Patel, W. S. Yancy, R. N. Gray, R. J. Irvine, A. S. Kendrick, and G. D. Sanders. 2012. “Updated report on comparative effectiveness of ACE inhibitors, ARBs, and direct renin inhibitors for patients with essential hypertension: much more data, little new information.” J Gen Intern Med 27 (6): 716–29.
Rassen, J. A., A. A. Shelat, J. Myers, R. J. Glynn, K. J. Rothman, and S. Schneeweiss. 2012. “One-to-many propensity score matching in cohort studies.” Pharmacoepidemiol Drug Saf 21 Suppl 2 (May): 69–80.
Rosenbaum, P., and D. Rubin. 1983. “The Central Role of the Propensity Score in Observational Studies for Causal Effects.” Biometrika 70 (April): 41–55. doi:10.1093/biomet/70.1.41.
Rubin, Donald B. 2001. “Using Propensity Scores to Help Design Observational Studies: Application to the Tobacco Litigation.” Health Services and Outcomes Research Methodology 2 (3-4). Springer: 169–88.
Ryan, P. B., M. J. Schuemie, and D. Madigan. 2013. “Empirical performance of a self-controlled cohort method: lessons for developing a risk identification and analysis system.” Drug Saf 36 Suppl 1 (October): 95–106.
Sabroe, R. A., and A. K. Black. 1997. “Angiotensin-converting enzyme (ACE) inhibitors and angio-oedema.” Br. J. Dermatol. 136 (2): 153–58.
Schneeweiss, S. 2018. “Automated data-adaptive analytics for electronic healthcare data to study causal treatment effects.” Clin Epidemiol 10: 771–88.
Simpson, S. E., D. Madigan, I. Zorych, M. J. Schuemie, P. B. Ryan, and M. A. Suchard. 2013. “Multiple self-controlled case series for large-scale longitudinal observational databases.” Biometrics 69 (4): 893–902.
Suchard, M. A., S. E. Simpson, Ivan Zorych, P. B. Ryan, and David Madigan. 2013. “Massive Parallelization of Serial Inference Algorithms for a Complex Generalized Linear Model.” ACM Trans. Model. Comput. Simul. 23 (1). New York, NY, USA: ACM: 10:1–10:17. doi:10.1145/2414416.2414791.
Suissa, S. 1995. “The case-time-control design.” Epidemiology 6 (3): 248–53.
Tian, Y., M. J. Schuemie, and M. A. Suchard. 2018. “Evaluating large-scale propensity score performance through real-world and synthetic data experiments.” Int J Epidemiol 47 (6): 2005–14.
Toh, S., M. E. Reichman, M. Houstoun, M. Ross Southworth, X. Ding, A. F. Hernandez, M. Levenson, et al. 2012. “Comparative risk for angioedema associated with the use of drugs that target the renin-angiotensin-aldosterone system.” Arch. Intern. Med. 172 (20): 1582–9.
Vandenbroucke, J. P., and N. Pearce. 2012. “Case-control studies: basic concepts.” Int J Epidemiol 41 (5): 1480–9.
Walker, Alexander M, Amanda R Patrick, Michael S Lauer, Mark C Hornbrook, Matthew G Marin, Richard Platt, Véronique L Roger, Paul Stang, and Sebastian Schneeweiss. 2013. “A Tool for Assessing the Feasibility of Comparative Effectiveness Research.” Comp Eff Res 3: 11–20.
Whelton, P. K., R. M. Carey, W. S. Aronow, D. E. Casey, K. J. Collins, C. Dennison Himmelfarb, S. M. DePalma, et al. 2018. “2017 ACC/AHA/AAPA/ABC/ACPM/AGS/APhA/ASH/ASPC/NMA/PCNA Guideline for the Prevention, Detection, Evaluation, and Management of High Blood Pressure in Adults: Executive Summary: A Report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines.” Circulation 138 (17): e426–e483.
Whitaker, H. J., C. P. Farrington, B. Spiessens, and P. Musonda. 2006. “Tutorial in biostatistics: the self-controlled case series method.” Stat Med 25 (10): 1768–97.
Wickham, Hadley. 2015. R Packages. 1st ed. O’Reilly Media, Inc.
Zaman, M. A., S. Oparil, and D. A. Calhoun. 2002. “Drugs targeting the renin-angiotensin-aldosterone system.” Nat Rev Drug Discov 1 (8): 621–36.