Chapter 1 OHDSI 커뮤니티
Chapter leads: Patrick Ryan & George Hripcsak
함께 모이면 시작되고, 함께 지내면 진보하고, 함께 일하면 성공한다. -헨리 포드
1.1 데이터에서 근거로의 여정
대학병원과 의원, 규제 기관 및 의료 제품 제조업체, 보험 회사 및 정책 기관, 그리고 환자와 의료 제공자 간의 모든 상호관계를 포함하는 전 세계 보건 의료의 어느 곳에서나 다음과 같은 공통적인 과제가 있다. 우리는 과거를 통해 배운 것을 어떻게 미래를 위하여 적용하여 더 나은 결정을 내릴 수 있을 것인가?
10년이 넘도록, 많은 사람들이 스스로 학습하는 보건의료 체계 learning healthcare system의 비전에 대해서 논의해 왔다. “그것은 각 환자와 의료 제공자가 함께 의료 행위를 결정할 때 필요한 최상의 근거를 생성하고 적용하기 위함이다. 또한, 환자 치료의 부산물로서 새로운 의학적 발견이 가능하도록 유도하며, 보건의료의 혁신, 질, 안전 및 가치를 보장하기 위함이다.” (Olsen et al. 2007) 이 원대한 계획의 주요한 요소는 일상적인 임상 치료 과정에서 수집된 환자 수준 patient-level의 데이터를 분석하여 실세계 근거 real-world evidence를 생성할 수 있으며, 의료 시스템에 전파되어 실제 임상에 정보를 제공 할 수 있으리라는 야심 찬 전망에 있다. 미국 의학 연구소 Institute of Medicine의 근거 중심 의학 원탁회 Roundtable on Evidence-Based Medicine은 2007년 보고서에서 “2020년까지 90%의 임상 결정이 정확하고, 시기적절하고, 최신의 임상 정보에 의해 뒷받침될 것이며, 그것은 가능한 최선의 근거를 반영할 것이다.”라고 예측했다. (Olsen et al. 2007) 비록 여러 가지 면에서 엄청난 발전이 있었지만, 우리는 여전히 이 위대한 열망에는 한참 미치지 못하고 있다.
무엇 때문인가? 부분적으로는 환자 수준의 데이터에서 신뢰할만한 근거를 생성하는 여정이 몹시 고되기 때문일 것이다. 데이터로부터 근거를 생성하는 과정에는 정해진 하나의 길이 없으며, 어떠한 지도도 그 길을 안내해주지 않는다. 사실, “데이터 data”가 무엇인지, 그리고 “근거 evidence”가 무엇인지에 대한 통일된 관념도 존재하지 않는다.
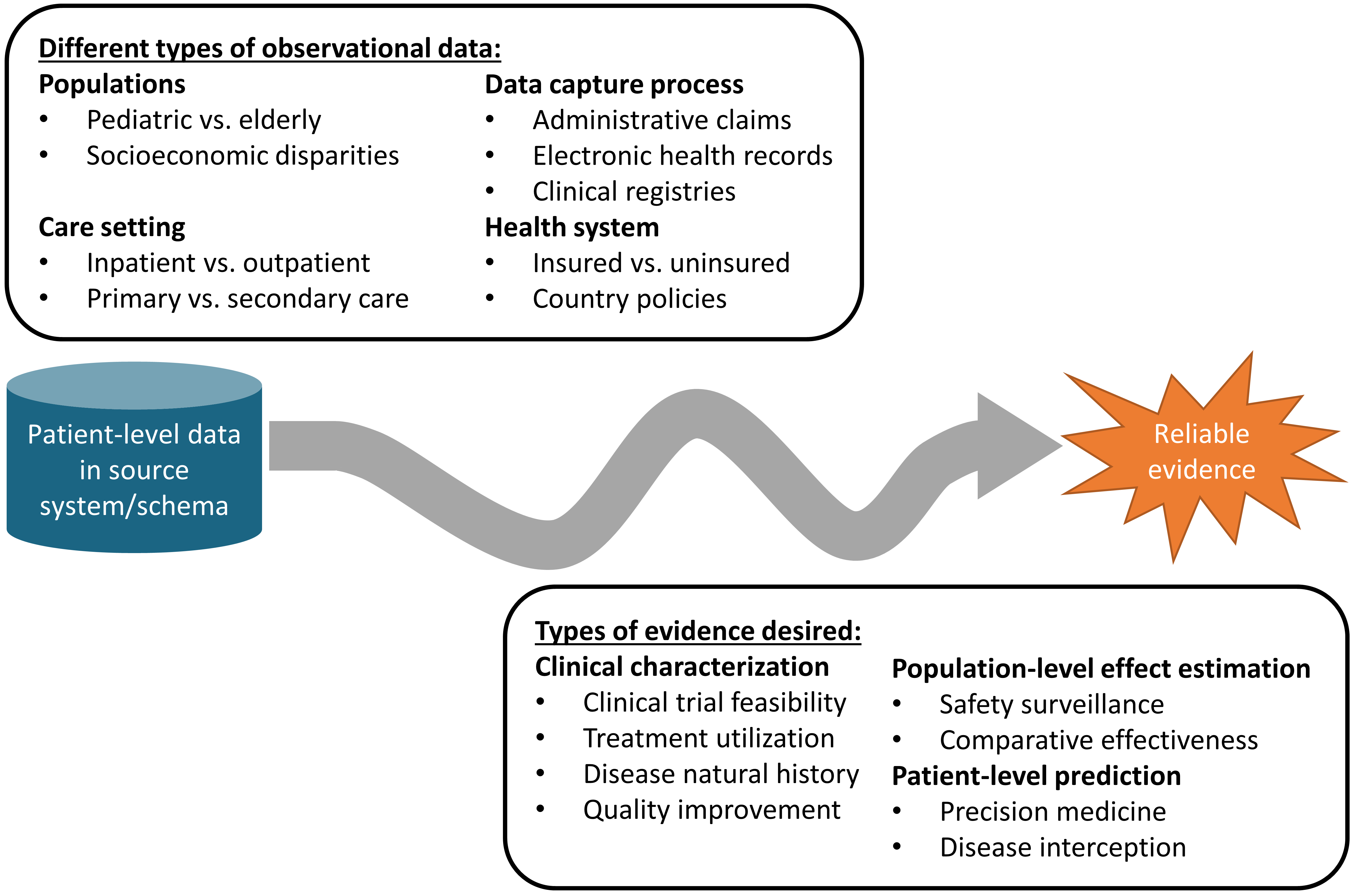
Figure 1.1: 데이터에서 근거로의 여정
원천 시스템에는 다양한 환자 수준의 데이터를 수집하는 여러 유형의 관찰 데이터베이스 observational database가 있다. 이 데이터베이스는 서로 다른 의료 시스템 내부의 인구, 치료 설정 및 데이터 수집 프로세스의 이질성만큼 다양하다. 의사 결정에 도움이 될 수 있는 다양한 유형의 근거가 있으며, 분석 방법론에 따라 임상적 특성 분석 clinical characterization, 인구 수준 추정 population-level estimation 및 환자 수준 예측 patient-level prediction으로 분류할 수 있다. 출발지(원천 데이터)와 원하는 목적지(근거) 자체에 대한 이해뿐 아니라, 광범위한 임상, 과학 및 기술 역량들이 모두 필요하기에 이 여정은 더욱 어려워진다. 보험 청구나 진료 과정이 데이터로 수집되면서 보건 정책이나 보험 환급과 관련된 행동 동기들로 인해 데이터 수집 및 정제 과정에서 발생할 수 있는 비뚤림을 비롯하여 환자와 의료 제공자 간의 진료 현장에서 원천 데이터가 수집되는 전반적인 과정에 대한 철저한 의료정보학적 이해도 필요하다. 임상적 의문으로부터 해답을 도출하는 데 적합한 관찰 연구를 설계하기 위해선 역학 원칙과 통계적 방법도 숙지하고 있어야 한다. 수백만 명 환자의 수년간의 종적 추적에 걸친 수십억 건의 임상 관찰을 가진 데이터 세트에 대해 계산적으로 효율적인 데이터 처리 알고리즘을 구현하고 실행할 수 있는 기술적 능력 역시 필요하다. 관찰형 연구를 통해 습득한 내용을 다른 근거와 통합하고, 이 새로운 지식이 건강 정책 및 임상 관행에 어떤 영향을 미칠지 고려하기 위해서는 임상 지식 또한 필요하다. 그렇기 때문에 한 개인이 데이터를 이용하여 근거를 성공적으로 만들어 내는 데 필요한 기술과 자원을 모두 보유하는 것은 매우 드문 일이다. 따라서 이용 가능한 최선의 데이터를 가장 적절한 방법으로 분석하여 모든 이해당사자가 그들의 의사결정 과정에 믿고 사용할 수 있는 근거를 생산하기 위해서는, 종종 많은 개인이나 기관과의 협력이 필요하다.
1.2 OMOP (Observational Medical Outcomes Partnership)
협력 관찰형 연구 모델의 주목할만한 예시로 OMOP(Observational Medical Outcomes Partnership)이 있다. OMOP은 미국 식품의약국 FDA이 주관하고, 미국 국립 보건원 National Institutes of Health 관리하에 학술 연구자, 보건 데이터 파트너 및 협력 제약사간의 컨소시엄으로 구성되었으며, 관찰형 보건의료 데이터를 이용하여 능동적 의료 제품 안전성 감시의 발전을 꾀하고자 만들어진 민관 협력체였다. (Stang et al. 2010) OMOP은 다수의 이해관계자 간의 거버넌스 구조를 확립했고, 다수의 청구자료 및 전자 의무 기록 데이터베이스에 적용하여 참인 약물 안전성 연관성과 거짓 양성 소견을 식별할 수 있는 대안적인 역학 설계 및 통계 방법의 성능을 경험적으로 검증하는 일련의 방법론적 실험을 설계하였다.
분산된 관찰형 데이터베이스를 통해 연구를 진행하면서 기술적인 난제를 인식하고, 연구진들은 데이터의 구조, 내용 및 용어를 표준화하여 하나의 통계 분석 코드가 모든 데이터 파트너에서 공통으로 사용될 수 있도록, OMOP 공통 데이터 모델 Common Data Model(CDM)을 설계하였다. (Overhage et al. 2012) OMOP 실험은 공통 데이터 모델과 표준화된 어휘를 확립하는 것이 가능하다는 것을 증명하였으며, 이는 서로 다른 의료체계에서 다른 용어체계를 통해서 생성된 다른 데이터 유형을 수용하여 기관 간 협업과 계산적으로 효율적인 분석을 용이하게 할 수 있는 방식으로 구현되었다.
OMOP은 처음부터 오픈 사이언스 정책을 채택하여 연구 설계, 데이터 표준, 분석 코드, 경험적 결과 등 모든 작업의 결과를 공공에 배포함으로써 투명성을 증진하고, OMOP이 수행하고 있는 연구에 대한 신뢰를 쌓을 뿐 아니라, 또한 다른 이들의 연구 목적을 위하여 발전할 수 있도록 하였다. OMOP의 원래 초점은 약물 안전성이었지만, 의학적 중재나 보건 시스템 정책에 대한 비교 효과연구를 포함하여 다양한 분석 사용사례를 지원하기 위해 지속적으로 발전하고 있다.
OMOP은 대규모의 경험적 실험 large-scale empirical experiments을 성공적으로 수행하였고, (Ryan et al. 2012; Ryan et al. 2013) 방법론적인 혁신을 이루고, (Schuemie et al. 2014) 관찰형 데이터를 이용한 안정성에 관련된 의사결정에 유용한 지식 생성을 위한 적절한 방법론을 제시하였다. (Madigan et al. 2013; Madigan, Ryan, and Schuemie 2013) OMOP 프로젝트는 종료되었지만, 오픈 사이언스 원칙과 함께 OMOP의 유산은 OHDSI가 이어받았다.
OMOP 프로젝트가 FDA의 능동 감시에 도움을 줄 수 있는 관찰형 연구를 완료하고 종료된 이후, 사람들은 OMOP의 종료가 새로운 여정의 시작이 되어야 한다고 생각했다. OMOP의 방법론적 연구가 관찰 데이터에서 생성되는 근거의 품질을 명시적으로 개선할 수 있는 모범 사례 best practice를 제시하였지만, 많은 연구자들은 이러한 모범 사례를 채택하기를 주저했다. 이를 방해하는 몇 가지 장애물들이 있었는데, 1) 방법론적인 혁신을 내세우기 전 관찰형 자료의 품질에 대한 근본적인 우려 2) 방법론적 문제와 해결책에 대한 불충분한 개념적 이해 3) 개별 데이터 파트너의 로컬 환경 내에서 솔루션을 독립적으로 구현할 수 없다는 점 4) 이러한 접근방식이 다른 연구자들이 관심이 있는 임상적 문제에 적용 가능한지에 대한 불확실성 등이었다. 이러한 모든 장애물에 대해 변화를 만들기 위해서는 한 개인의 힘이 아니라, 여러 사람이 협력하여야만 한다는 것을 깨달을 수 있었다. 다음과 같은 협력이 필요했다:
- 기초 데이터 품질에 대한 신뢰도를 높이며 구조, 콘텐츠 및 의미론적 일관성을 촉진하여 표준화된 분석이 가능하도록 개방형 커뮤니티 open community의 데이터 구조, 어휘 및 추출 변환 적재 Extract-Transform-Load(ETL) 표준규약 구축을 위한 협업
- 약물 안전성 연구 외에도 임상적 특성 분석, 인구 수준 추정 및 환자 수준 예측을 위한 보다 광범위한 모범 사례를 확립하기 위한 협업. 방법론적 연구를 통해 입증된 과학적 모범 사례를 코드로 구현하고 연구자들이 쉽게 채택할 수 있는 오픈 소스 분석 소프트웨어 개발에 대한 협업
- 주요한 보건 문제를 해결할 공통의 질문에 대한 임상 적용을 위한 협업으로써, 커뮤니티를 아울러서 데이터에서 근거로의 여정을 총괄적으로 인도해줄 수 있는 협업체계
이러한 통찰을 통해 OHDSI가 태어났다.
1.3 개방형 과학 공동체로서의 OHDSI
OHDSI(Observational Health data Sciences and Informatics)는 보다 더 나은 의료 결정과 더 나은 보건 관리를 촉진할 수 있는 과학적 근거를 공동으로 생성하도록 함으로써 보건 수준을 향상하는 것을 목표로 하는 개방형 과학 공동체다. (Hripcsak et al. 2015) OHDSI는 관찰 보건 데이터 observational health data의 적절한 사용에 대한 과학적 모범 사례를 확립하기 위한 방법론적 연구를 수행하고, 이러한 연구방법론을 일관되고 투명하며 재현 가능한 솔루션으로 코드화하는 오픈 소스 분석 소프트웨어를 개발하여, 보건의료 정책 및 환자 치료에 도움이 될 수 있는 임상적 근거를 마련하는 데에 적용할 수 있도록 노력한다.
1.3.1 OHDSI의 사명 Mission
더 나은 의학적 결정과 의료 발전을 촉진할 수 있는 근거를 상호협력하에 생성할 수 있도록 공동체에 힘을 실어줌으로써 보건을 개선한다.
To improve health by empowering a community to collaboratively generate the evidence that promotes better health decisions and better care.
1.3.2 OHDSI의 이상 Vision
관찰형 연구를 통해 건강과 질병에 대한 포괄적인 이해가 가능한 세상
A world in which observational research produces a comprehensive understanding of health and disease.
1.3.3 OHDSI의 목표 Objectives
- 혁신 Innovation: 관찰 연구는 파괴적 사유 disruptive thinking를 통해서 가장 큰 혜택을 얻을 수 있는 분야이다. 우리는 우리의 업무에 새로운 방법론적인 접근을 적극적으로 찾고 격려한다.
Observational research is a field which will benefit greatly from disruptive thinking. We actively seek and encourage fresh methodological approaches in our work.
- 재현 Reproducibility: 보건향상을 위해서는 정확하고 재현 가능하며 잘 보정된 근거가 필요하다.
Accurate, reproducible, and well-calibrated evidence is necessary for health improvement.
- 공동체 Community: 우리는 OHDSI에 적극적으로 참여하는 모든 사람 (환자, 의료직 전문가, 연구자, 또는 단순히 우리의 주장을 믿는 사람)을 환영한다.
Everyone is welcome to actively participate in OHDSI, whether you are a patient, a health professional, a researcher, or someone who simply believes in our cause.
- 협력 Collaboration: 우리는 우리 공동체 참여자들의 현실적 요구를 최우선으로 다루기 위해서 함께 일한다.
We work collectively to prioritize and address the real world needs of our community’s participants.
- 개방 Openness: 우리는 방법론, 도구, 우리가 생성하는 근거 등 우리 공동체의 모든 진행 사항을 개방하고 공개적으로 접근 가능할 수 있도록 최대한 노력한다.
We strive to make all our community’s proceeds open and publicly accessible, including the methods, tools and the evidence that we generate.
- 선행 Beneficence: 우리는 우리 공동체에 속한 개인과 기관의 권리를 보호하기 위해서 항상 노력한다.
We seek to protect the rights of individuals and organizations within our community at all times.
1.4 OHDSI의 역사
OHDSI는 2014년 설립된 이래 성장을 지속하여 컴퓨터 과학, 역학, 통계, 의생명 정보학, 보건 정책 및 임상 의학 등 다양한 분야를 대표하는 학계, 의료 제품 산업, 규제 기관, 정부, 보험자, 기술 제공자, 의료 시스템, 임상의사 및 환자 집단 등 2,500명 이상의 다양한 이해관계자가 온라인 포럼에서 활동하고 있다. OHDSI 협력체로써 자발적으로 보고한 기관 및 데이터베이스의 리스트는 OHDSI 웹사이트에서 확인할 수 있다.1 OHDSI 참가자 지도 (그림 1.2 참조)는 폭넓은 국제 공동체로서의 다양성을 상기시킨다.
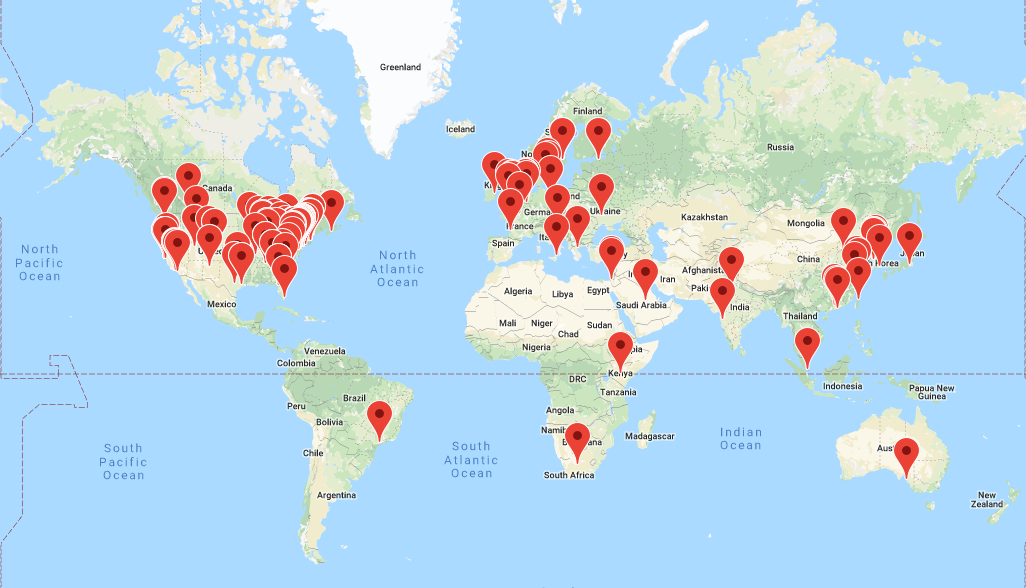
Figure 1.2: 2019년 8월 기준 OHDSI 참가자 지도
OHDSI는 OMOP-CDM이라는 개방형 공동체 데이터 표준 기반으로 2019년 8월 기준으로 20여 개국, 100개 이상의 의료 데이터베이스들로 구성된 분산 연구망 distributed research network(DRN)를 구축했다. 분산 연구망에서는 환자 수준의 데이터를 개인이나 조직 간에 공유할 필요가 없다. 분산 연구망에서는 데이터를 기관 폐쇄망 안에 두고 연구자는 프로토콜 형태의 분석 코드/프로그램을 공유하기 때문이다. 데이터 파트너들은 연구자의 요청에 따라 기관 안에서 연구 프로토콜을 실행해 자동으로 생성되는 요약 집합정보 (평균, 합, 표준편차, 교차비, 위험도 등)만 연구자에게 회신하는 방식으로, 연구자는 폐쇄망 안에 있는 환자의 개별 정보를 보거나 취득하지 않는다. OHDSI 분산망에서 각 데이터 파트너는 환자 수준 데이터의 사용에 대한 완전한 자율성을 유지하고, 각 기관이 기관의 데이터 거버넌스 정책을 지속해서 준수할 수 있다.
OHDSI 개발자 커뮤니티는 3가지의 사용 사례를 지원하기 위해 OMOP CDM 위에 다음 3가지의 강력한 오픈 소스 분석 소프트웨어 라이브러리를 구축하였는데 이는 다음과 같다. 1) 임상적 특성 분석: 질병의 자연 경과, 치료 행태 및 질 향상을 위한 임상 특성 분석 2) 인구 수준 추정: 의약품 안전성 감시 및 비교 효과 연구에서의 인과성 분석 3) 환자 수준 예측: 기계학습 알고리즘을 활용한 정밀 의학 또는 의료 중재. OHDSI 개발자들은 OMOP CDM의 채택, 데이터 품질 평가, OHDSI 네트워크 연구의 촉진을 지원하는 애플리케이션을 개발하고 있다. 이러한 소프트웨어에는 R과 Python에 내장된 백 엔드 통계 패키지 및 HTML과 Javascript로 개발된 프론트엔드 웹 어플리케이션이 포함된다. 모든 OHDSI 소프트웨어들은 오픈 소스 정책을 채택하여 Github을 통해 공개된다.2
오픈 소스 소프트웨어들과 함께, OHDSI의 개방형 과학 공동체적 접근은 관찰형 연구의 발전을 가능하게 했다. 첫 번째 OHDSI 네트워크 연구는 당뇨, 우울증, 고혈압의 3가지 만성 질병에 대한 치료 패턴을 분석하는 것이었다. PNAS(Proceedings of the National Academy of Science)에 출판된 연구는, 그때까지 수행된 최대 규모의 관찰 연구로써 11개의 데이터베이스에서 2억 5천만 명의 환자 데이터를 이용하여 이전에 보고된 적 없는 치료 패턴의 지역적 차이 및 환자별 치료 선택에 대한 이질성에 대해 발표하였다. (Hripcsak et al. 2016) OHDSI는 교란변수를 통제하는 새로운 통계적 방법론을 제시하였고, (Tian, Schuemie, and Suchard 2018) 인과성 검증 능력에 대해 검증하였고, (Schuemie, Hripcsak, et al. 2018) 이러한 방법론을 뇌전증 약제의 개별 안전성 연구 (Duke et al. 2017) 및 당뇨병의 이차 약제의 비교 효과 연구 (Vashisht et al. 2018), 우울증 치료의 대규모 비교 효과 연구 (Schuemie, Ryan, et al. 2018), 고혈압 환자의 이제 병합 요법의 비교 효과 연구(You et al. 2019), 대규모 고혈압 약제 비교 연구 (Suchard et al. 2019) 에 활용하였다. OHDSI 공동체는 또한 관찰형 보건의료 데이터의 기계학습 알고리즘을 활용한 프레임 워크를 구축 (Reps et al. 2018) 하여 다양한 치료 분야에 활용하였다. (Johnston et al. 2019; Cepeda et al. 2018; Reps, Rijnbeek, and Ryan 2019)
1.5 OHDSI와의 협업
OHDSI는 근거를 생성하기 위해 협업을 강화하는 것을 목표로 하는 공동체인데, OHDSI 참가자가 된다는 것은 무엇을 의미하는가? 만약 당신이 OHDSI의 사명을 믿고 데이터에서 근거에 이르는 여정의 어디든지 기여를 하는 데 관심이 있다면, OHDSI는 당신을 위한 공동체가 될 수 있다. OHDSI 참가자는 보건 의료 데이터에 접근이 가능하고, 이를 활용해 의학적 근거를 생성하고 싶은 개인일 수 있다. OHDSI 참가자는 과학적 모범 사례를 수립하고 대안적 접근법을 평가하는 데 관심이 있는 방법론 연구자일 수 있다. OHDSI 참가자는 OHDSI의 타 연구자들이 사용할 수 있는 도구를 만들기 위해 프로그래밍 기술을 적용하는 데 관심이 있는 소프트웨어 개발자일 수 있다. OHDSI 참가자는 중요한 의학 보건학적 질문을 가지고 있고 논문 발표 등을 통해 그러한 질문들에 대한 근거를 더욱더 큰 의료 커뮤니티에 제공하고자 하는 임상 연구자일 수 있다. OHDSI 참가자는 공공 보건을 위해 이러한 공통적인 사명과 가치를 믿고 해당 지역의 공동체가 OHDSI 관련 교육과 심포지엄 개최를 포함하여, 그 임무를 지속할 수 있도록 자원을 제공하는 개인 또는 단체일 수도 있다. 당신의 배경이나 소속과 관계없이, OHDSI는 개개인이 공통의 목적을 위해 함께 일할 수 있는 공동체가 되기를 추구하고 있으며, 각 개인이 공동으로 의료를 발전시킬 수 있는 기여를 하고 있다. 이 여정에 함께하고 싶다면, 2장 (“OHDSI 시작하기”)을 통해 어떻게 시작하는지 배울 수 있다.
1.6 한국 OHDSI의 역사
OMOP의 창립자 중 한 명인 Martijn Schuemie는 OMOP의 연구성과 중 하나로서 관찰형 자료에서 confounding by indication을 찾을 수 있는 LEOPARD 알고리즘을 고안하였고, 2010년 남아프리카 케이프타운에서 열린 세계의료정보학회(IMIA)에서 그 내용을 발표하였다. 당시 세계의료정보학회에 참석하였던 박래웅은 우연히 Martijn Schuemie의 LEOPARD 알고리즘과 OMOP을 접하게 되었고 강한 흥미와 유대감을 느꼈다. 이후 그는 2012년 국내 4개 대학병원의 다기관 임상 의료정보 통합시스템 개발을 진행하였고 이를 위해 자체적으로 고안한 CDM을 적용하였다. 2013년 세계약물역학학회(ICPE)가 그 해 9월 캐나다 몬트리올에서 열렸고 이 학회에서 다시 만난 Martijn Schuemie, Patrick Ryan과 박래웅은 각자 진행하던 프로젝트에 대해서 논의하였고 향후 긴밀한 협조를 결의하였다. 이후 그는 빠른 시간 내에 아주대병원 전자의무기록을 CDM으로 변환 완료하고 2014년 OHDSI의 결성을 알리는 컬럼비아대학에서 열린 첫 번째 face-to-face 모임에 참여하면서 변환 완료된 아주대병원의 CDM과 Achilles 웹페이지를 전격 공개하였다. 미국 이외의 국가에서 변환된 첫 번째 CDM이며 전 세계에서 첫 번째로 공개된 Achilles 페이지였다.

Figure 1.3: 2014년 최초 개최된 OHDSI Face to Face 미팅에서 아주대학교병원의 CDM과 Achilles 웹페이지를 소개하였다. 사진의 좌측하단에 Christopher Knoll이 아주대 CDM Achilles 화면을 살펴보고 있으며 많은 참석자가 각별한 관심을 보였다.
그는 2014년 6월 이후 본격적으로 한국 사회에 OHDSI를 알리기 시작하였고, 이후 국민건강보험공단을 시작으로 가천길병원 등이 OHDSI에 참여하기 시작하였다. 이후 계속 국내외에서 OMOP-CDM, OHDSI 전파를 위해 노력한 결과, 2016년부터는 최초로 국제 OHDSI committee에서 개별 국가를 위한 포럼 Korean chapter 을 개설하고, 한국의 OHDSI 참여가 본격화되었다. 첫 한국 국제 OHDSI 심포지엄은 2017년 3월 아주대학교에서 튜토리얼, 리더십 미팅을 포함하여 3일간 개최되었다.

Figure 1.4: 2017년 한국에서의 OHDSI 국제 심포지엄
한국 OHDSI 네트워크에 참여를 희망하는 병원 관계자들과 함께 2017년 3월 7일 첫 번째 리더십 미팅을 가진 후 현재까지 2달마다 전국의 의과대학/병원을 순회하며 총 15회 이상의 한국 OHDSI 리더십 미팅을 개최하며 OHDSI 전파 및 상호 협력을 꾀하고 있다.
1.7 요약
OHDSI의 사명은 참여 공동체의 상호협력 하에 의료 발전을 촉진하는 근거를 생성하는 능력을 부여하는 것이다.
OHDSI의 이상은 혁신, 재현, 공동체, 개방, 협력, 선행의 목표를 바탕으로 의료 빅데이터의 분석을 통해 세계에 건강과 질병에 대한 포괄적인 이해를 제공하는 것이다.
- OHDSI 참가자들은 개방형 공동체로서의 데이터 표준, 방법론 연구, 오픈소스 분석 소프트웨어 개발 및 임상적 적용을 통해 데이터에서부터 근거로의 여정을 발전시키고자 노력한다.
References
Cepeda, M. S., J. Reps, D. Fife, C. Blacketer, P. Stang, and P. Ryan. 2018. “Finding treatment-resistant depression in real-world data: How a data-driven approach compares with expert-based heuristics.” Depress Anxiety 35 (3): 220–28.
Duke, J. D., P. B. Ryan, M. A. Suchard, G. Hripcsak, P. Jin, C. Reich, M. S. Schwalm, et al. 2017. “Risk of angioedema associated with levetiracetam compared with phenytoin: Findings of the observational health data sciences and informatics research network.” Epilepsia 58 (8): e101–e106.
Hripcsak, George, Jon D Duke, Nigam H Shah, Christian G Reich, Vojtech Huser, Martijn J Schuemie, Marc A Suchard, et al. 2015. “Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers.” Studies in Health Technology and Informatics 216: 574–78. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4815923/.
Hripcsak, George, Patrick B. Ryan, Jon D. Duke, Nigam H. Shah, Rae Woong Park, Vojtech Huser, Marc A. Suchard, et al. 2016. “Characterizing treatment pathways at scale using the OHDSI network.” Proceedings of the National Academy of Sciences 113 (27). National Academy of Sciences: 7329–36. doi:10.1073/pnas.1510502113.
Johnston, S. S., J. M. Morton, I. Kalsekar, E. M. Ammann, C. W. Hsiao, and J. Reps. 2019. “Using Machine Learning Applied to Real-World Healthcare Data for Predictive Analytics: An Applied Example in Bariatric Surgery.” Value Health 22 (5): 580–86.
Madigan, D., P. B. Ryan, and M. Schuemie. 2013. “Does design matter? Systematic evaluation of the impact of analytical choices on effect estimates in observational studies.” Ther Adv Drug Saf 4 (2): 53–62.
Madigan, D., P. B. Ryan, M. Schuemie, P. E. Stang, J. M. Overhage, A. G. Hartzema, M. A. Suchard, W. DuMouchel, and J. A. Berlin. 2013. “Evaluating the impact of database heterogeneity on observational study results.” Am. J. Epidemiol. 178 (4): 645–51.
Olsen, LeighAnne, Dara Aisner, J Michael McGinnis, and others. 2007. The Learning Healthcare System: Workshop Summary. Natl Academy Pr.
Overhage, J. M., P. B. Ryan, C. G. Reich, A. G. Hartzema, and P. E. Stang. 2012. “Validation of a common data model for active safety surveillance research.” J Am Med Inform Assoc 19 (1): 54–60.
Reps, J. M., P. R. Rijnbeek, and P. B. Ryan. 2019. “Identifying the DEAD: Development and Validation of a Patient-Level Model to Predict Death Status in Population-Level Claims Data.” Drug Saf, May.
Reps, J. M., M. J. Schuemie, M. A. Suchard, P. B. Ryan, and P. R. Rijnbeek. 2018. “Design and implementation of a standardized framework to generate and evaluate patient-level prediction models using observational healthcare data.” Journal of the American Medical Informatics Association 25 (8): 969–75. doi:10.1093/jamia/ocy032.
Ryan, P. B., D. Madigan, P. E. Stang, J. M. Overhage, J. A. Racoosin, and A. G. Hartzema. 2012. “Empirical assessment of methods for risk identification in healthcare data: results from the experiments of the Observational Medical Outcomes Partnership.” Stat Med 31 (30): 4401–15.
Ryan, P. B., P. E. Stang, J. M. Overhage, M. A. Suchard, A. G. Hartzema, W. DuMouchel, C. G. Reich, M. J. Schuemie, and D. Madigan. 2013. “A comparison of the empirical performance of methods for a risk identification system.” Drug Saf 36 Suppl 1 (October): S143–158.
Schuemie, M. 2018. “Empirical confidence interval calibration for population-level effect estimation studies in observational healthcare data.” Proc. Natl. Acad. Sci. U.S.A. 115 (11): 2571–7.
Schuemie, M. J., P. B. Ryan, W. DuMouchel, M. A. Suchard, and D. Madigan. 2014. “Interpreting observational studies: why empirical calibration is needed to correct p-values.” Stat Med 33 (2): 209–18.
Schuemie, M. J., P. B. Ryan, G. Hripcsak, D. Madigan, and M. A. Suchard. 2018. “Improving reproducibility by using high-throughput observational studies with empirical calibration.” Philos Trans A Math Phys Eng Sci 376 (2128).
Stang, P. E., P. B. Ryan, J. A. Racoosin, J. M. Overhage, A. G. Hartzema, C. Reich, E. Welebob, T. Scarnecchia, and J. Woodcock. 2010. “Advancing the science for active surveillance: rationale and design for the Observational Medical Outcomes Partnership.” Ann. Intern. Med. 153 (9): 600–606.
Suchard, Marc A., Martijn J. Schuemie, Harlan M. Krumholz, Seng Chan You, RuiJun Chen, Nicole Pratt, Christian G. Reich, et al. 2019. “Comprehensive Comparative Effectiveness and Safety of First-Line Antihypertensive Drug Classes: A Systematic, Multinational, Large-Scale Analysis.” The Lancet 0 (0). doi:10.1016/S0140-6736(19)32317-7.
Tian, Y., M. J. Schuemie, and M. A. Suchard. 2018. “Evaluating large-scale propensity score performance through real-world and synthetic data experiments.” Int J Epidemiol 47 (6): 2005–14.
Vashisht, R., K. Jung, A. Schuler, J. M. Banda, R. W. Park, S. Jin, L. Li, et al. 2018. “Association of Hemoglobin A1c Levels With Use of Sulfonylureas, Dipeptidyl Peptidase 4 Inhibitors, and Thiazolidinediones in Patients With Type 2 Diabetes Treated With Metformin: Analysis From the Observational Health Data Sciences and Informatics Initiative.” JAMA Netw Open 1 (4): e181755.
You, Seng Chan, Hojun Park, Dukyong Yoon, Sooyoung Park, Boyoung Joung, and Rae Woong Park. 2019. “Olmesartan Is Not Associated with the Risk of Enteropathy: A Korean Nationwide Observational Cohort Study.” The Korean Journal of Internal Medicine 34 (1): 90–98. doi:10.3904/kjim.2017.002.