Chapter 14 근거의 질
Chapter leads: Patrick Ryan & Jon Duke
14.1 신뢰성 있는 근거의 속성
본격적인 여정 시작에 앞서, 우리가 바라는 이상적인 종착지가 어디인지 상상해보는 것은 도움이 될 것이다. 데이터를 근거로 만들기 위한 우리의 여정을 지원하기 위해서, 우리는 근거의 신뢰도를 높일 수 있는 바람직한 속성을 강조하고자 한다.
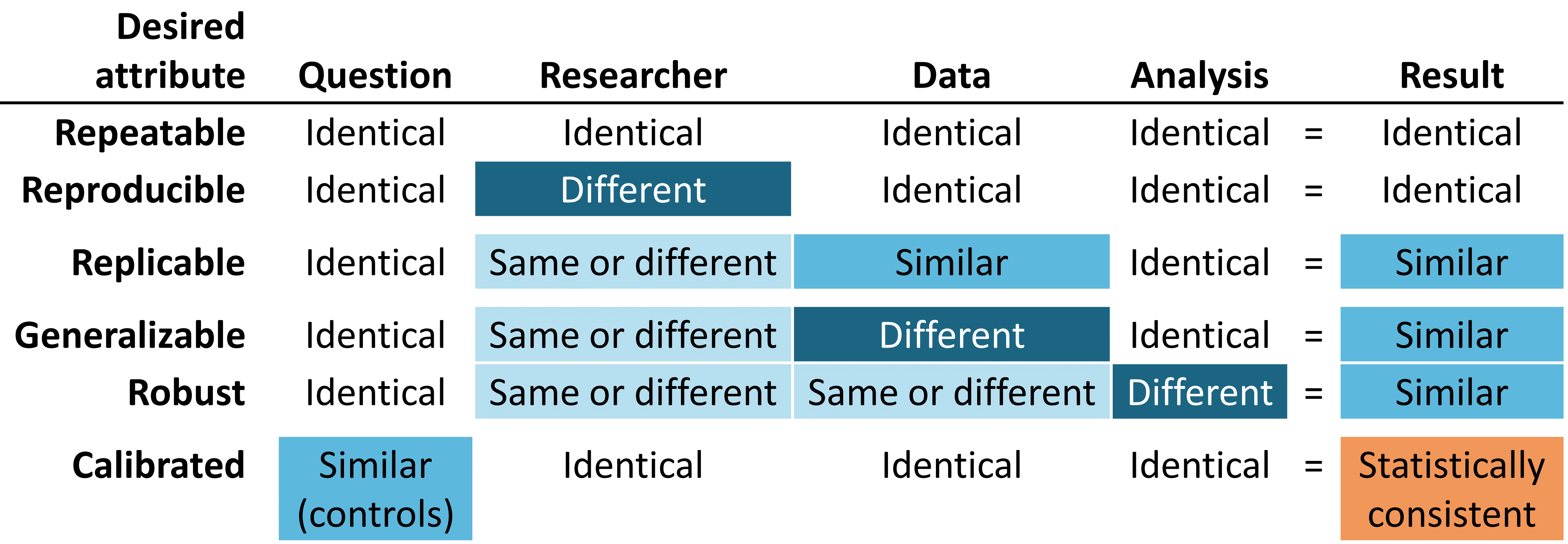
Figure 14.1: 이상적인 신뢰성을 위한 근거의 속성
신뢰할 수 있는 근거는 반복 가능 repeatable 해야 한다. 즉, 연구자가 주어진 질문에 대해 동일한 데이터를 이용하여 동일한 분석을 수행할 때 동일한 결과가 나올 것이라 기대할 수 있어야 한다. 근거의 반복 가능성에 대한 최소한의 요구 조건은 근거가 특정 데이터를 입력하고 정의된 절차를 수행하여서 나온 결과라는 점과, 사후 의사 결정 과정에서 수동적인 개입에서 벗어나야 한다는 점이다. 조금 더 이상적으로는, 신뢰할 수 있는 근거는 재현 가능 reproducible해야 하는데, 다른 연구자가 주어진 데이터와 분석 방법을 가지고 동일한 업무를 수행하였을 때 첫 연구자의 수행 결과와 동일한 결과를 낼 수 있어야 한다는 것이다. 재현 가능성을 위해서 연구 절차는 일반적인 사람이 읽을 수 있고, 컴퓨터가 실행할 수 있으며 충분히 구체화 되어 있어 추가적인 연구자의 결정이 연구 결과에 반영되지 않도록 해야 한다. 반복성과 재현성을 충족시킬 수 있는 가장 효과적인 방법은 사전에 정의한 데이터의 입출력을 이용하여 표준화된 분석 방법을 사용하고, 이러한 절차를 버전이 관리되는 데이터베이스에 적용하는 것이다.
또한 동일한 질문에 대해 비슷한 데이터를 가지고 동일 분석 방법을 적용하여 비슷한 결과를 얻을 수 있는, 복제 가능성 replicable 을 확인한다면 우리가 주장하는 근거는 더욱 신뢰할 만하다고 자신할 수 있다. 예를 들어, 한 대규모 보험사의 청구 데이터베이스에 대한 분석에서 생성된 근거는 다른 보험사의 청구 데이터베이스를 이용하여 복제가 가능할 경우 그 근거가 강화될 수 있다. 인구 수준 효과 추정의 관점에서도 이 속성은 Austin Bradford Hill 경의 인과적 관점과 잘 일치한다. “다른 사람, 다른 장소, 환경 및 시간에서도 반복적으로 관찰되었습니까? …(중략)… 반복적인 상황과 관찰만이 우연으로 설명되는 현상인지 혹은 실재하는 위험인지 답할 수 있다.” (Hill 1965) 환자 수준 예측의 맥락에서 복제 가능성은 외부 검증 external validation의 시행에 대한 중요성뿐 아니라, 한 데이터베이스에서 훈련된 모델이 다른 데이터베이스에 적용될 때 결과를 구별할 수 있는 판별 정확도 discriminative accuracy와 보정 calibration을 관찰함으로써 모델의 성능을 평가할 수 있는 능력을 강조할 수 있다. 서로 다른 데이터베이스에 대해 동일한 분석을 수행하고, 여전히 유사한 결과를 보이는 상황에서 우리는 그 근거가 일반화될 수 있다 generalizable는 확신을 얻는다. OHDSI 연구 네트워크의 핵심 가치는 다른 인구, 지역, 자료 획득 과정 등으로 대표되는 다양성이다. Madigan et al. (2013) 은 효과 추정치 effect estimates가 데이터의 선택에 따라 민감하게 변할 수 있음을 보여주었다. 각 데이터 원천이 단일 연구의 신뢰도를 하락시킬 수 있는 고유의 한계점과 비뚤림이 있다는 점을 인식한 상태에서, 서로 다른 데이터 세트를 사용하여도 유사한 결과 패턴이 관측된 것은 어마어마하게 강력한 의미가 있다. 이는 데이터 원천 각각이 가지고 있는 비뚤림의 가능성을 상당 부분 감소 시켜, 연구 결과를 설명할 수 있기 때문이다. 네트워크 연구의 인구 수준 효과 추정치가 미국, 유럽, 아시아 그리고 다양한 청구데이터, 전자의무기록 데이터상에서 일관된 결과를 보여줄 때 해당 의학적 중재는 의학적 의사 결정 과정에서 더 큰 영향을 줄 수 있는 더욱 강력한 근거로서 인식되어야 한다.
신뢰할 만한 근거는 분석 내에서 주관적 선택에 지나치게 민감하지 않은 강건성 robust 을 가져야 한다. 주어진 연구에 대해서 잠재적으로 합당하다고 생각되는 대안적인 통계 방법이 있다면, 결과에 따라서 다른 분석 방법을 통해 얻은 동일한 결과로 기존 연구 결과에 대해 확신을 더하거나, 혹은 상충하는 결과를 통해 기존 연구에 대한 경각심을 얻을 수 있다. (Madigan, Ryan, and Schuemie 2013) 인구 수준 효과 추정에서 민감도 분석에는 연구 설계 선정 (코호트 비교 연구, 자기 통제 환자군 self-controlled case series 연구 등)과 분석적 고려사항의 선정 (코호트 비교에서 혼란 변수 조정을 위한 성향점수 매칭, 계층화 또는 가중치 유무)과 같은 고급 연구 설계의 문제를 포함할 수 있다.
마지막으로 가장 중요할 수도 있는 부분은 근거는 보정되어야 한다 calibrated는 점이다. 근거 생성 시스템에 대한 성능이 검증되지 않은 상태에서는 해당 시스템이 미지의 연구 질문에 대한 답변을 제공한다고 말하기 불충분하다. 폐쇄형 시스템은 잘 알려진 작동 특성을 가져야 하며, 이는 측정 가능하고 시스템이 생성하는 어떠한 결과에 대해서도 그 상황을 잘 전달할 수 있어야 한다. 통계적 표현은 경험적으로 잘 정립된 특성이 있음을 보여줄 수 있어야 한다. 예를 들어 95% 신뢰구간이란 95%의 확률 범위를 갖는다는 뜻이고, 10%의 예상 확률이란 인구 집단에서 관측된 사건 발생의 비율이 10%이라는 뜻이다. 관찰 연구에서는 항상 연구 설계, 연구 방법, 연구 데이터에 대한 가정을 검정할 방법을 수반해야 한다. 이 검정 방법은 연구 타당성에 일차적인 위협 (선택비뚤림, 교란변수, 측정 오차)에 대해 먼저 집중하여 평가하여야 한다. 음성 대조군 Negative controls은 관찰연구에서 발생할 수 있는 계통 오차를 확인하고 감소시킬 수 있는 강력한 도구인 것으로 보고되었다. (Schuemie et al. 2016; Schuemie, Hripcsak, et al. 2018; Schuemie, Ryan, et al. 2018)
14.2 근거의 질에 대한 이해
하지만 우리의 연구 결과가 충분히 신뢰할만한 수준인지 어떻게 알 수 있을까? 누군가가 우리의 연구에서 설정해놓은 특정 환경을 신뢰할까? 규제 당국의 의사결정은 어떨까? 향후 연구의 기반이 될 수 있을까? 새로운 연구가 발표되거나 확산하는 과정에서 독자는 연구의 형태 (무작위 대조시험, 관찰 연구, 혹은 다른 유형의 분석 방법)에 관계없이 이러한 질문을 염두에 두어야 한다.
흔히 관찰 연구 observational study 즉, 실세계 데이터 real world data를 활용한 연구를 진행하면서 마주하게 되는 우려는 바로 데이터 품질에 관한 부분이다. (Botsis et al. 2010; Hersh et al. 2013; Sherman et al. 2016) 일반적으로 관찰 연구에 사용된 데이터는 원래 연구 목적으로 수집된 것이 아니므로 내재적 비뚤림 inherent biases과 같은 불완전하거나 부정확한 데이터의 수집으로 인한 문제를 겪을 수 있다. 이러한 우려로 인해 데이터 품질을 측정하고 특성화하고 이상적으로 데이터 품질을 개선하려는 방법에 대한 연구가 계속해서 증가하고 있다. (Kahn et al. 2012; Liaw et al. 2013; Weiskopf and Weng 2013) OHDSI 커뮤니티는 이러한 연구를 강력히 지지하며, 커뮤니티 회원은 OMOP CDM 및 OHDSI 네트워크의 데이터 품질을 조사하는 많은 연구를 직접 주도하고 참여하였다. (Huser et al. 2016; Kahn et al. 2015; Callahan et al. 2017; Yoon et al. 2016)
지난 10년간의 결과를 고려해보면, 데이터 품질이라는 것은 결코 완벽해질 수 없다는 것이 명백해졌다. 이 개념은 의료정보학 분야의 개척자인 Clem McDonald 박사의 인용에도 잘 반영되어 있다. :
사실 데이터 충실도의 감소는 의사의 뇌에서 의료기록으로 데이터가 이동하는 것에서부터 시작된다.
그러므로 우리는 공동체로서 질문해야 할 필요가 있다. –불완전한 데이터가 주어지면, 어떻게 우리는 신뢰할만한 근거를 얻을 수 있을까?
이 문제에 대한 대답은 “근거의 품질”에 대한 다음과 같은 전반적인 과정을 살펴보는 데 있다: 데이터에서부터 근거로의 과정에 대한 검토, 근거 생성 과정의 구성 요소에 대한 확인, 각 구성 요소의 질에 대한 신뢰 구축 방법의 결정, 그리고 이것을 투명하게 전달하는 방법. 근거의 질이란 단순히 관찰 데이터의 품질뿐 아니라 관찰 분석에 사용된 방법, 소프트웨어 및 임상적 정의의 타당성을 고려해야 한다.
뒤이어 나오는 단원에서 우리는 근거의 품질에 해당하는 네 가지 구성요소에 대한 부분을 살펴볼 것이며, 이를 표 14.1에 나타내었다.
| 구성요소 | 측정 대상 |
|---|---|
| 데이터 품질 | 합의된 구조와 방법을 이용하여 타당한 값을 가진 데이터가 온전히 입력되었는가? |
| 임상적 타당성 | 수행된 분석이 임상적 의도와 어느 정도 일치하고 있는가? |
| 소프트웨어의 타당성 | 데이터의 변환과 분석 과정이 우리가 의도한 대로 진행되었다고 신뢰할 수 있는가? |
| 방법론적 타당성 | 주어진 데이터의 강점과 약점을 인지하고 있는 상태에서, 적절한 연구 방법론을 사용하고 있는가? |
14.3 근거 품질의 전달
근거 품질의 중요한 측면은 데이터에서 근거로의 여정에서 발생하는 불확실성을 표현하는 능력이다. OHDSI의 활동을 통해 이루고자 하는 거시적인 목표는 OHDSI에서 생성된 근거가 –비록 여러 방면으로 불완전하더라도– 강점과 약점에 대하여 일관되게 측정되고, 엄격하고 공개적인 방식으로 전달되어 생성되었다는 신뢰감을 의료 전문가에게 제공해주는 것이다.
14.4 요약
우리가 생성한 근거는 반복 가능성 repeatable, 재현 가능성 reproducible, 복제 가능성 replicable, 일반화 가능성 generalizable, 강건성 robust을 갖추어야 하며 보정된 calibrated 결과여야 한다.
- 근거의 품질은 그 근거의 신뢰성 여부를 판단하기 위해 단순히 데이터의 품질만이 아닌 그 이상의 것을 추구한다:
- 데이터 품질
- 임상적 타당성
- 소프트웨어 타당성
- 방법론적 타당성
- 근거를 전달하는 과정에서, 근거의 품질에 대한 다양한 위협으로부터 나타나게 되는 불확실성 또한 표현해야 한다.
References
Botsis, Taxiarchis, Gunnar Hartvigsen, Fei Chen, and Chunhua Weng. 2010. “Secondary Use of Ehr: Data Quality Issues and Informatics Opportunities.” Summit on Translational Bioinformatics 2010. American Medical Informatics Association: 1.
Callahan, Tiffany J, Alan E Bauck, David Bertoch, Jeff Brown, Ritu Khare, Patrick B Ryan, Jenny Staab, Meredith N Zozus, and Michael G Kahn. 2017. “A Comparison of Data Quality Assessment Checks in Six Data Sharing Networks.” eGEMs 5 (1). Ubiquity Press.
Hersh, William R, Mark G Weiner, Peter J Embi, Judith R Logan, Philip RO Payne, Elmer V Bernstam, Harold P Lehmann, et al. 2013. “Caveats for the Use of Operational Electronic Health Record Data in Comparative Effectiveness Research.” Medical Care 51 (8 0 3). NIH Public Access: S30.
Hill, A. B. 1965. “THE ENVIRONMENT AND DISEASE: ASSOCIATION OR CAUSATION?” Proc. R. Soc. Med. 58 (May): 295–300.
Huser, Vojtech, Frank J. DeFalco, Martijn Schuemie, Patrick B. Ryan, Ning Shang, Mark Velez, Rae Woong Park, et al. 2016. “Multisite Evaluation of a Data Quality Tool for Patient-Level Clinical Data Sets.” EGEMS (Washington, DC) 4 (1): 1239. doi:10.13063/2327-9214.1239.
Kahn, Michael G, Marsha A Raebel, Jason M Glanz, Karen Riedlinger, and John F Steiner. 2012. “A Pragmatic Framework for Single-Site and Multisite Data Quality Assessment in Electronic Health Record-Based Clinical Research.” Medical Care 50. NIH Public Access.
Kahn, Michael G., Jeffrey S. Brown, Alein T. Chun, Bruce N. Davidson, Daniella Meeker, P. B. Ryan, Lisa M. Schilling, Nicole G. Weiskopf, Andrew E. Williams, and Meredith Nahm Zozus. 2015. “Transparent Reporting of Data Quality in Distributed Data Networks.” EGEMS (Washington, DC) 3 (1): 1052. doi:10.13063/2327-9214.1052.
Liaw, Siaw-Teng, Alireza Rahimi, Pradeep Ray, Jane Taggart, Sarah Dennis, Simon de Lusignan, B Jalaludin, AET Yeo, and Amir Talaei-Khoei. 2013. “Towards an Ontology for Data Quality in Integrated Chronic Disease Management: A Realist Review of the Literature.” International Journal of Medical Informatics 82 (1). Elsevier: 10–24.
Madigan, D., P. B. Ryan, and M. Schuemie. 2013. “Does design matter? Systematic evaluation of the impact of analytical choices on effect estimates in observational studies.” Ther Adv Drug Saf 4 (2): 53–62.
Madigan, D., P. B. Ryan, M. Schuemie, P. E. Stang, J. M. Overhage, A. G. Hartzema, M. A. Suchard, W. DuMouchel, and J. A. Berlin. 2013. “Evaluating the impact of database heterogeneity on observational study results.” Am. J. Epidemiol. 178 (4): 645–51.
Schuemie, M. J., G. Hripcsak, P. B. Ryan, D. Madigan, and M. A. Suchard. 2016. “Robust empirical calibration of p-values using observational data.” Stat Med 35 (22): 3883–8.
Schuemie, M. 2018. “Empirical confidence interval calibration for population-level effect estimation studies in observational healthcare data.” Proc. Natl. Acad. Sci. U.S.A. 115 (11): 2571–7.
Schuemie, M. J., P. B. Ryan, G. Hripcsak, D. Madigan, and M. A. Suchard. 2018. “Improving reproducibility by using high-throughput observational studies with empirical calibration.” Philos Trans A Math Phys Eng Sci 376 (2128).
Sherman, Rachel E, Steven A Anderson, Gerald J Dal Pan, Gerry W Gray, Thomas Gross, Nina L Hunter, Lisa LaVange, et al. 2016. “Real-World Evidence—what Is It and What Can It Tell Us.” N Engl J Med 375 (23): 2293–7.
Weiskopf, Nicole Gray, and Chunhua Weng. 2013. “Methods and Dimensions of Electronic Health Record Data Quality Assessment: Enabling Reuse for Clinical Research.” Journal of the American Medical Informatics Association: JAMIA 20 (1): 144–51. doi:10.1136/amiajnl-2011-000681.
Yoon, D., E. K. Ahn, M. Y. Park, S. Y. Cho, P. Ryan, M. J. Schuemie, D. Shin, H. Park, and R. W. Park. 2016. “Conversion and Data Quality Assessment of Electronic Health Record Data at a Korean Tertiary Teaching Hospital to a Common Data Model for Distributed Network Research.” Healthc Inform Res 22 (1): 54–58.