Chapter 11 임상적 특성 분석
Chapter leads: Anthony Sena & Daniel Prieto-Alhambra
관찰형 보건의료 데이터는 다양한 특성을 바탕으로 인구집단의 변화를 이해할 수 있는 귀중한 자원이다. 기술통계를 통해 인구집단의 특성을 확인하는 것은 건강과 질병에 영향을 주는 요인에 대한 가설 설정을 위한 중요한 첫 번째 단계이다. 이번 장에서는 특성 분석 characterization을 위한 방법에 관해 살펴보기로 한다:
- 데이터베이스 수준의 특성 분석 Database-level characterization: 상위 수준 top-level의 요약 통계량을 제공하여 데이터베이스 전체에 대한 이해를 돕는다.
- 코호트 특성 분석 Cohort characterization: 의무기록 집합 aggreagation 수준에서 인구집단을 기술한다.
- 치료 경로 Treatment pathways: 특정 기간 동안 한 사람에 대하여 행해진 중재 intervention 순서를 기술한다.
- 발생 Incidence: 위험 노출 기간 time at risk(TAR) 동안의 임상 결과 outcome의 발생률을 계산한다.
데이터베이스 수준의 특성 분석을 제외하고 나머지 방법은 기준 날짜 index date라고 하는 시점과 관련된 인구 집단에 관해 설명하는데 목적이 있다. 이와 같은 관심 집단은 코호트라고 정의되며 10장에 기술되어 있다. 코호트는 관심 집단의 개개인에 대한 기준 날짜를 정의한다. 기준 날짜를 기준으로 기준 날짜 이전의 시간을 기저 시간 baseline time이라 정의한다. 기준 날짜를 포함한 그 이후의 시간은 기준 후 시간 post-index time이라고 부른다.
특성 분석은 질병의 자연 경과, 치료 이용, 진료 질 개선 등과 같은 것에 활용될 수 있다. 이번 장에서는 특성 분석 방법에 관해 기술하며, ATLAS와 R을 이용한 고혈압 환자군에 대한 특성 분석을 해 볼 것이다.
11.1 데이터베이스 수준의 특성 분석 Database Level Characterization
관심 집단에 대한 특성 분석을 시행하기 전, 사용하고자 하는 데이터베이스의 특성을 이해하는 것이 선행되어야 한다. 데이터베이스 수준의 특성 분석 Database Level Characterization은 전체 데이터베이스에 대한 시간의 흐름에 따른 경향과 분포 측면에서 데이터 전체를 설명하기 위해 사용한다. 데이터베이스의 정량적 분석은 일반적으로 다음과 같은 질문을 포함한다:
- 이 데이터베이스의 총 사람 수는 몇인가?
- 환자의 연령 분포는 어떠한가?
- 환자의 관찰 기간은 얼마나 오래되었는가?
- 시간이 지남에 따라 기록/처방된 {치료, 질병, 처치 등}을 받은 사람의 비율은 어떠한가?
데이터베이스 수준의 기술 통계는 연구자가 어떠한 데이터에서 손실이 있을 수 있는지와 같이 확인할 수 없는 부분을 이해하는 데 도움을 주며 15장 데이터 품질을 설명할 때 자세히 다룬다.
11.2 코호트 특성 분석 Cohort Characterization
코호트 특성 분석 Cohort Characterization은 기준 날짜와 기준 날짜 이후 코호트 구성원의 특성을 기술한다. OHDSI는 상태 condition, 약물 drug, 치료 재료 device, 시술 procedure, 임상 관찰 clinical observation 등 개인의 의무기록에 존재하는 모든 것에 대한 기술 통계량을 바탕으로 특성 분석에 접근한다. 또한, 기준 날짜 시점에서 코호트 구성원에 대한 사회인구학적 내용에 대해 요약해준다. 이와 같은 접근 방식을 통해 관심 코호트에 대한 완벽한 요약을 제공한다. 특히, 이러한 접근을 통해 데이터의 변화에 대한 안목을 가지고 코호트에 대한 전체적인 탐색을 가능하게 하는 한편, 잠재적인 결측값을 찾을 수 있도록 한다.
코호트 특성 분석 방법은 이미 치료를 받은 사람에게서 치료의 적응증 유발률과 금기를 추정하는 개인 수준의 개인 수준의 약물 사용 연구 person-level drug utilization studies(DUS)에 이용될 수 있다. 코호트 특성 분석의 보급은 Strengthening the Reporting of Observational Studies in Epidemiology(STROBE) 가이드라인에서 자세히 제시하고 있는 관찰 연구에 권장되는 모범사례이다. (Elm et al. 2008)
11.3 치료 경로 Treatment Pathways
인구 집단의 특성을 분석하는 또 하나의 방법은 기준 날짜 이후 post-index 시간 동안의 치료 순서를 기술하는 것이다. 예를 들어, 이전 연구 (Hripcsak et al. 2016) 에서 OHDSI의 공통 데이터 모델(CDM)을 활용해 제2형 당뇨, 고혈압, 우울증에 대한 치료 경로의 특징을 분석하기 위한 기술 통계를 고안하였다. 이러한 분석 방법을 표준화함으로써, Hripcsak과 그 연구팀은 관심 집단의 특성 분석을 OHDSI 네트워크상에서 동일한 통계 방법으로 반복하여 실행하였다.
치료 경로 Treatment Pathways 분석은 가장 처음 처방/조제된 약물 이후 특정 상태에 있는 환자에 대한 치료행위 events를 요약하기 위해 시행한다. 이 연구에서는 제2형 당뇨, 고혈압, 우울증의 진단 이후의 치료행위를 기술하였다. 개개인이 받은 치료행위는 이후 요약 통계량 모음으로 합쳐지고 각각의 질병과 각각의 데이터베이스별로 시각화하였다.
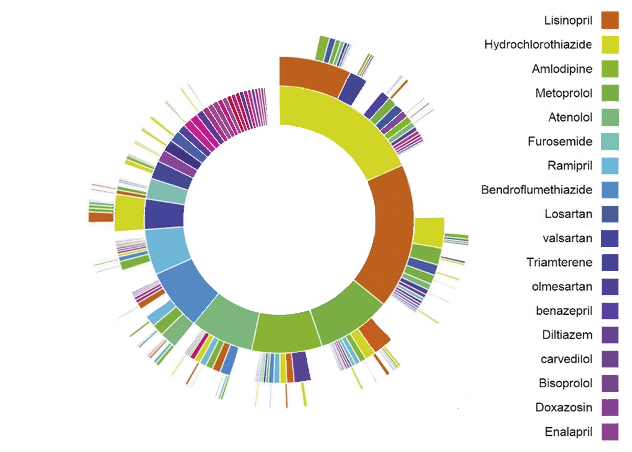
Figure 11.1: 고혈압 환자의 OHDSI 치료 경로 “sunburst” 시각화 사례
그림 11.1에서 제시된 사례는 고혈압 치료를 시작한 환자집단을 나타낸다. 가운데 위치한 첫 번째 고리는 1차 요법 first-line therapy에 대한 환자의 비율을 나타낸다. 이 사례의 경우 Hydrochlorothiazide는 고혈압 환자군의 1차 요법으로 가장 흔하게 사용되는 약물이라는 것을 알 수 있다. Hydrochlorothiazide에서 파생된 상자는 해당 코호트 대상자에서 기록된 두 번째(2nd), 세 번째(3rd) 요법을 의미한다.
치료 경로 분석은 인구집단 내의 치료 이용 현황에 대한 중요한 근거를 제공한다. 이 분석을 통해 가장 빈번히 사용되는 1차 요법을 기술할 수 있고, 치료가 중단/변경/확대된 사람의 비율을 알 수 있다. 경로 분석을 통해 metformin이 당뇨에서 가장 일반적으로 처방된 1차 치료제임을 밝혔고, 이를 통해 미국 내분비학회의 당뇨 치료 알고리즘의 일차 요법이 일반적으로 잘 적용되고 있음을 확인했다. 더불어 당뇨 환자의 10%, 고혈압 환자의 24%, 그리고 우울증 환자의 11%는 다른 데이터베이스와 비교했을 때 자신과 같은 치료경로를 가진 사람이 단 한 명도 없는 고유한 치료 경로를 따르고 있는 것으로 나타났다.
고전적인 약물 사용 연구(DUS) 용어에서, 치료 경로 분석은 특정 집단에서 하나 이상의 약물 사용률과 같은 집단 수준의 약물 사용 연구 population-level DUS 뿐 아니라 치료 방법의 지속률, 서로 다른 치료 간의 전환율과 같은 개인 수준의 약물 사용 연구 person-level DUS가 포함된다.
11.4 발생 Incidence
발생률 incidence rate과 발생비 incidence proportion는 공중 보건에서 위험 노출 기간 time-at-risk(TAR) 동안 인구집단 내 새로운 질병 outcome의 발생 평가에 사용되는 통계적 지표이다. 그림 11.2는 한 사람에게서 발생률 계산에 필요한 구성요소를 보여주고 있다:
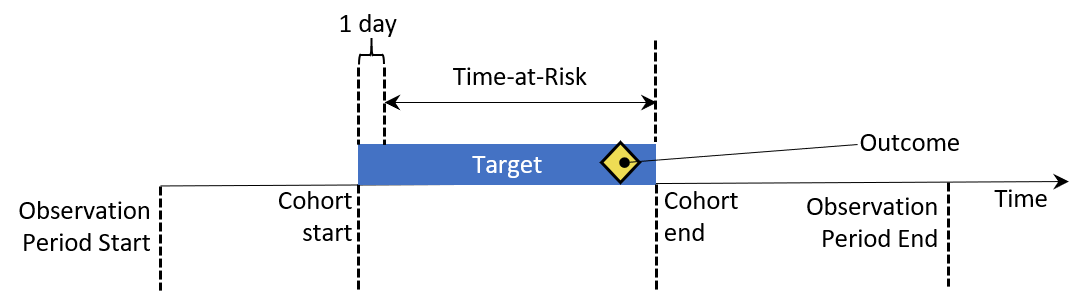
Figure 11.2: 개인 수준에서의 발생률 계산의 구성 성분. 본 예시에서 위험 노출 기간은 코호트가 시작하고 하루 이후부터 코호트가 끝나는 시점으로 정의됨.
그림 11.2에서 한 사람은 데이터 내에서 관찰이 시작되고 observation period start 끝나는 시점 observation period end이 표시된 기간을 갖는다. 그다음, 그 사람은 몇몇 연구 기준 eligibility criteria에 의해 코호트에 들어가는 시점 cohort start과 나오는 시점 cohort end을 갖게 된다. 위험 노출 기간은 우리가 질병 outcome의 발생을 보고자 하는 기간을 의미한다. 만일 질병이 위험 노출 기간 내에 발생한다면, 그 질병 한 건이 발생한 것으로 계산한다.
발생 incidence을 계산하기 위해서는 두 가지 측정법이 있다:
\[ Incidence\;Proportion = \frac{\#\;persons\;in\;cohort\;with\;new\;outcome\;during\;TAR}{\#\;persons\;in\;cohort\;with\;TAR} \]
발생 분율 incidence proportion은 위험 노출 기간 동안 집단 내 새로운 outcome의 발생을 측정하는 방법이다. 다시 말해, 관심 집단에서 정해진 시간의 틀 안에서 발생한 outcome의 비율이다. (역자 주: incidence proportion = cumulative incidence (누적 발생률): 코호트에서 관찰 기간 내 새롭게 발생하는 환자 수 / 관찰 시작 시점의 코호트 인구수)
\[ Incidence\;Rate = \frac{\#\;persons\;in\;cohort\;with\;new\;outcome\;during\;TAR}{person\;time\;at\;risk\;contributed\;by\;persons\;in\;cohort} \]
발생률 incidence rate은 인구집단에서 누적되는 위험 노출 기간의 새로 발생한 outcome의 횟수를 측정한 것이다. 만일 한 환자가 위험 노출 기간 내에서 outcome을 경험했을 때, 그 환자가 전체의 인-시 person-time에 outcome이 발생하기까지의 시간만큼 기여했다고 산정한다. 누적된 위험 노출 기간은 인-시라고 하고, 단위는 일(인-일), 월(인-월), 혹은 연(인-년)으로 표현된다. (역자 주: incidence Rate = cumulative incidence (누적 발생률): 코호트에서 관찰 기간 내 새롭게 발생하는 환자 수 / 코호트 내 총 위험 노출 인-시)
치료 요법에 대하여 계산할 때, 정해진 치료 요법의 사용 비율 혹은 발생률을 계산하는 것은 전형적인 인구 집단 수준의 약물 사용 연구 (population-level DUS)라 할 수 있다.
11.5 고혈압 환자의 임상적 특성 분석
세계보건기구(WHO)의 고혈압에 대한 보고서 (Who 2013) 에 따르면, 고혈압의 초기 발견과 적절한 치료 및 양호한 혈압 조절은 건강과 경제적인 면에서 상당한 이득이 있다. WHO의 보고서에는 고혈압의 개요 및 여러 국가의 질병 부담의 특성을 보여주고 있다. WHO는 지역과 사회 경제적 계급 및 성별 고혈압에 대한 기술통계를 제공하고 있다.
WHO가 수행한 고혈압 환자의 특성 분석과 동일한 분석을 관찰형 데이터를 이용해 수행 할 수 있다. 이 장의 다음 절에서는 고혈압 환자 집단의 구성을 이해하기 위한 데이터베이스 탐색을 ATLAS와 R을 이용해 시행하는 방법을 살펴볼 것이다. 또한, 같은 도구를 사용해 고혈압 환자의 자연 경과와 치료 패턴을 기술하려고 한다.
11.6 ATLAS를 활용한 데이터베이스의 특성 분석
여기서는 ATLAS에 탑재된 데이터 탐색 모듈을 사용하여 ACHILLES로 생성된 데이터베이스의 통계치를 살펴보고, 고혈압 환자와 관련된 데이터베이스 수준의 특성을 찾아내는 방법을 설명하고자 한다. 시작하기 위해 ATLAS의 왼쪽 바에 있는  를 클릭하자. ATLAS의 첫 번째 드롭다운 목록에서 데이터 탐색 database to explore을 선택한다. 그리고, 데이터베이스 아래의 드롭다운 목록을 통해 보고서 탐색을 시작할 수 있다. 고혈압 환자에 대한 데이터베이스 수준의 특성 분석을 위해 두 번째 드롭다운 목록인 report 드롭다운 목록에서 Condition Occurrence를 선택하면 해당 데이터베이스의 모든 질병에 대한 트리 맵 시각화 결과가 표시된다:
를 클릭하자. ATLAS의 첫 번째 드롭다운 목록에서 데이터 탐색 database to explore을 선택한다. 그리고, 데이터베이스 아래의 드롭다운 목록을 통해 보고서 탐색을 시작할 수 있다. 고혈압 환자에 대한 데이터베이스 수준의 특성 분석을 위해 두 번째 드롭다운 목록인 report 드롭다운 목록에서 Condition Occurrence를 선택하면 해당 데이터베이스의 모든 질병에 대한 트리 맵 시각화 결과가 표시된다:
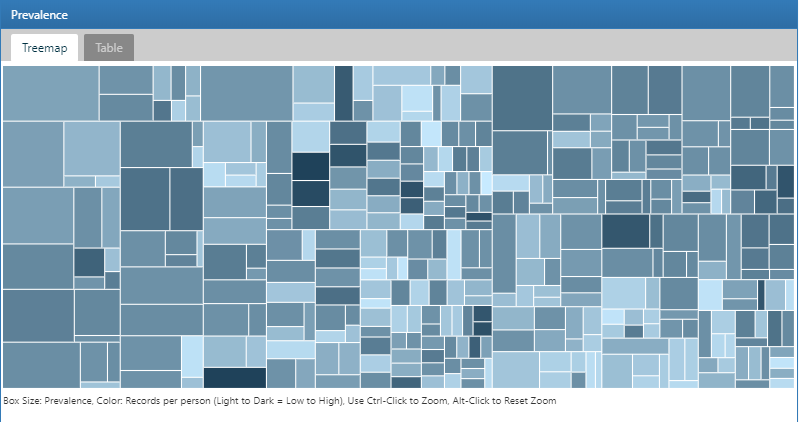
Figure 11.3: Atlas 데이터 원천: Condition Occurrence Treemap
특정 관심 질환을 검색하기 위해 Table 탭을 클릭하면 환자 수, 유병률, 환자별 기록 건수를 포함하는 데이터베이스의 전체 condition 목록이 나타난다. 상단의 filter 상자를 이용해 “hypertension”을 포함하는 concept name만을 걸러낼 수 있다:
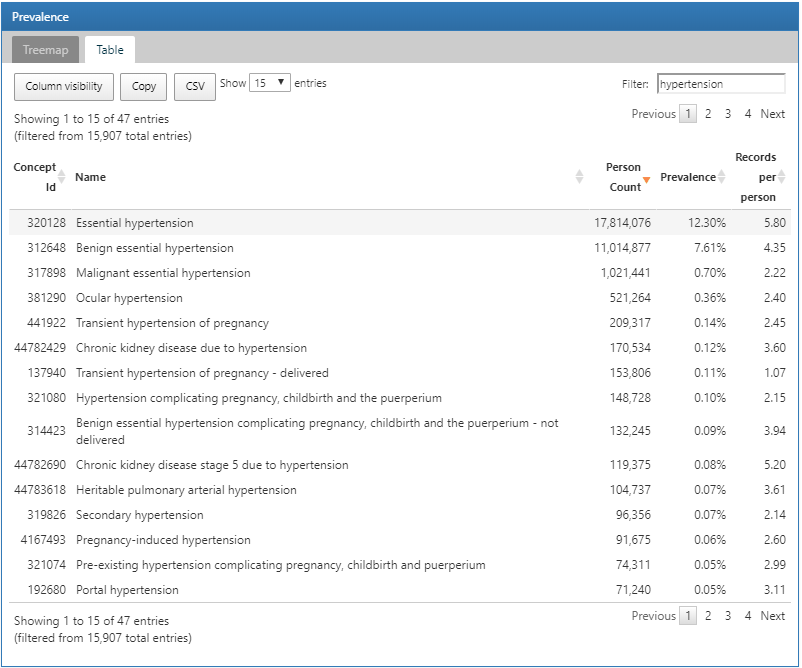
Figure 11.4: Atlas 데이터 원천: concept name에서 “고혈압 hypertension”이라는 단어를 이용해 걸러낸 결과
하나의 행을 클릭하면 해당 condition에 대한 자세한 드릴다운 보고서를 확인할 수 있다. 이 경우 “essential hypertension”을 선택한 결과이며, 선택된 condition의 시간에 따른 경향과 성별, 월별 유병률, 기록 유형 (주상병 혹은 부상병 등) 그리고 최초 진단 시 나이의 경향을 알 수 있다:
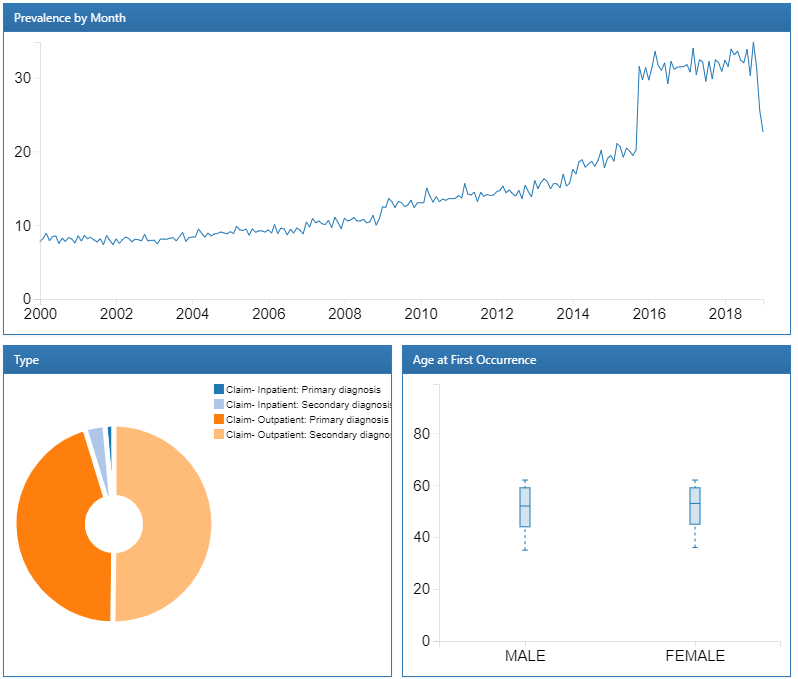
Figure 11.5: Atlas 데이터 원천: Essential hypertension 드릴다운 보고서
지금까지 고혈압이라는 concept에 대한 데이터의 특성과 시간에 따른 경향을 살펴보았다. 데이터베이스 수준의 특성 분석을 통해 고혈압 환자의 치료에 사용된 약물에 관해서도 확인할 수 있다. 이는 RxNorm 성분명에 요약된 약물 특성 검토를 위해 Drug Era report를 사용한 것 외에는 위와 동일하게 진행하면 된다. 관심 있는 항목에 대한 데이터베이스 특성 탐색을 마쳤다면, 이제는 특성화하고자 하는 고혈압 환자의 특성 분석을 위한 코호트를 설계하는 단계로 나아갈 준비를 마친 것이다.
11.7 ATLAS를 이용한 코호트 특성 분석
이 장에서는 ATLAS를 이용한 대규모의 코호트 특성 분석 방법 cohort characterization에 관해 설명할 것이다. ATLAS의 왼쪽 바에 있는  를 클릭하면, 새로운 특성 분석을 만들 수 있다. 분석을 명명하고
를 클릭하면, 새로운 특성 분석을 만들 수 있다. 분석을 명명하고  버튼을 눌러 저장한다.
버튼을 눌러 저장한다.
11.7.1 설계
특성 분석은 하나 이상의 코호트와 분석하고자 하는 하나 이상의 속성이 필요하다. 예시의 경우, 두 개의 코호트를 사용할 것이다. 첫 번째 코호트는 고혈압 치료를 시작한 환자로 기준 날짜 index date 이전 1년간 한 번이라도 고혈압 진단을 받은 환자로 정의하자. 또한 이 코호트에 속한 사람은 고혈압 치료제를 복용하기 시작한 후 최소 1년의 관찰 기간을 갖는다고 정의하자 (부록 B.6). 두 번째 코호트는 첫 번째 코호트와 모든 조건이 동일하지만, 최소관찰 기간을 1년 대신 3년을 갖는다고 한다 (부록 B.7).
코호트 정의
Figure 11.6: 특성 디자인 탭 - 코호트 정의 선택
해당 코호트는 10장에서 이미 만들어져 있다고 가정한다.  를 클릭하고 그림 11.6에서 보이는 바와 같이 코호트를 선택한다. 그다음, 두 코호트 특성 분석을 위해 사용할 속성을 설정한다.
를 클릭하고 그림 11.6에서 보이는 바와 같이 코호트를 선택한다. 그다음, 두 코호트 특성 분석을 위해 사용할 속성을 설정한다.
속성 선택
ATLAS에서 OMOP CDM에서 모델링 된 임상 도메인에서 특성 분석을 수행하기 위해 미리 만들어 둔 100개 이상의 특성 분석 도구 feature analysis (역자 주: CHADS2 score, Charlson comorbidity index 등 복잡한 쿼리나 계산을 해야만 구할 수 있는 각종 계산 값)가 정의되어 있다. 각각의 미리 정의해 둔 특성 분석 도구는 선택된 분석 대상 코호트에 대한 임상 관찰을 집계하고 요약하는 기능을 수행한다. 이와 같은 계산은 코호트의 index date 그리고 index date 후 특성을 설명하기 위해 수천 가지의 속성을 제공한다. ATLAS는 OHDSI에서 제공하는 FeatureExtraction R package를 이용해 개별 코호트에 대한 특성 분석을 시행하며, 이 FeatureExtraction이라는 R package를 사용하는 방법에 대하여 다음 절에서 더 자세하게 다룰 것이다.
분석하고자 하는 속성을 선택하기 위해 를 클릭한다. 아래에는 코호트의 특성 분석을 위해 사용할 속성의 리스트가 있다:
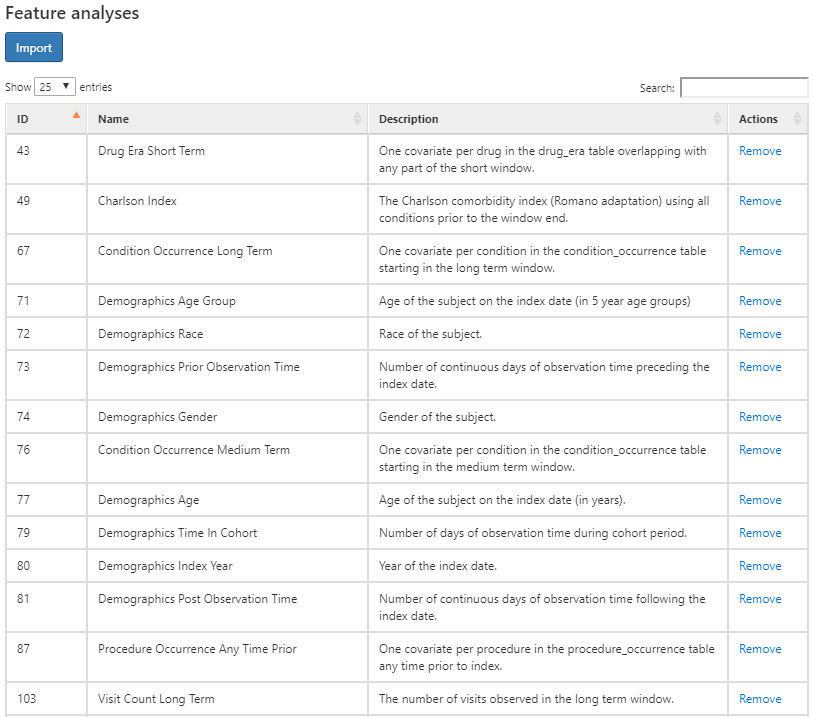
Figure 11.7: 특성 디자인 탭 - 속성 선택.
위 그림은 각의 코호트에서 분석할 속성에 어떤 것이 있는지를 설명과 함께 목록을 나타낸 것이다. “Demographics”라고 시작하는 속성은 각 환자의 인구 통계학적인 정보를 코호트의 시작 시점에서 계산한다. 도메인 이름으로 시작한 속성 (예를 들어, Visit, Procedure, Condition, Drug 등)은 해당 도메인에 기록된 모든 관찰 값의 특성을 나타낸 것이다. 각각의 도메인의 특성은 코호트 시작 지점에 앞서 네 가지의 시간대의 옵션이 있다:
Any time prior: 환자의 관찰 기간 내에서 코호트 시작 지점 전의 모든 시간대를 사용
Long term: 코호트 시작 지점을 포함하여 365일 이전까지
Medium term: 코호트 시작 지점을 포함하여 180일 이전까지
short term: 코호트 시작 지점을 포함하여 30일 이전까지
하위 집단 분석
만일 성별에 따라 특성에 차이가 있는지가 알고 싶다면 어떻게 해야 할까? 이때 우리는 “하위 집단 분석 subgroup analyses”을 이용할 수 있다. 이는 특성 분석 안에서 새로운 관심 하위 집단에 대한 정의를 할 수 있도록 해준다. 하위 집단을 만들기 위해 하위 그룹에 대한 기준을 클릭해 더하면 된다. 이 단계는 코호트 정의에 사용되는 기준과 유사하다. 이 사례에서 우리는 코호트 내의 여성을 확인할 수 있는 기준 모음을 정의할 것이다:
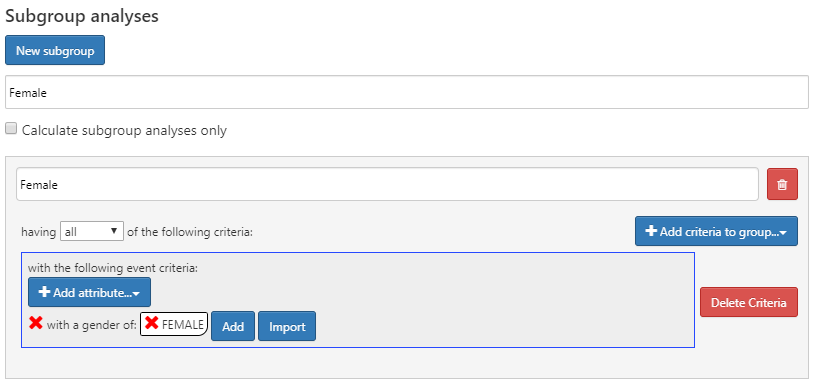
Figure 11.8: 여성에 대한 하위 그룹 분석을 위한 특성 분석 디자인.
11.7.2 실행
특성 분석의 설계가 끝났다면, 우리의 환경 내에서 사용할 수 있는 하나 이상의 데이터베이스에 대하여 설계한 특성 분석을 시행할 수 있다. Execution 탭으로 이동하여 Generate 버튼을 클릭하면 선택된 데이터베이스에서 분석이 시작된다.
Figure 11.9: 설계한 특성 분석의 실행 - CDM source 선택.
분석이 완료되면, “All Executions” 버튼을 클릭하고 실행 목록에서 “View Reports”를 선택하면 보고서를 볼 수 있다. 이와 별도로 “view latest result”를 클릭하면 가장 최근에 시행된 분석의 결과를 확인할 수 있다.
11.7.3 결과
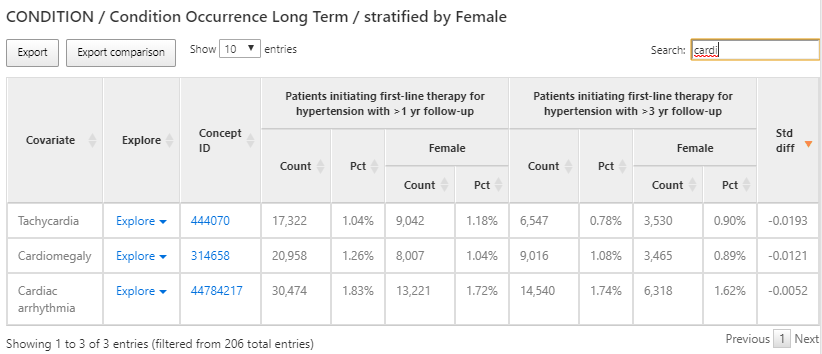
Figure 11.10: 특성 분석 결과 - condition occurrence long term
설계 시 선택한 각 코호트의 여러 속성은 표 형식으로 나타난다. 그림 11.10에서 보이는 것처럼 코호트 시작일로부터 365일 이전에 두 코호트에 존재하는 모든 질환을 요약하여 확인할 수 있다. 각 변수는 개별 코호트와 코호트 내에서 정의한 여성 하위그룹에 대한 수 count와 백분율 percentage을 보여준다.
어떤 심혈관 질환이 모집단에서 관찰되는지 이해하고자 심부정맥 cardiac arrhythmia 과거력을 갖는 환자의 비율이 얼마인지를 알아보기 위해 검색창에서 필터를 사용하였다. 심부정맥 개념 옆의 Explore 링크를 이용하면 그림 11.11에 보이는 것과 같이 하나의 코호트에 대하여 더 자세한 내용이 들어 있는 새로운 창을 띄울 수 있다:
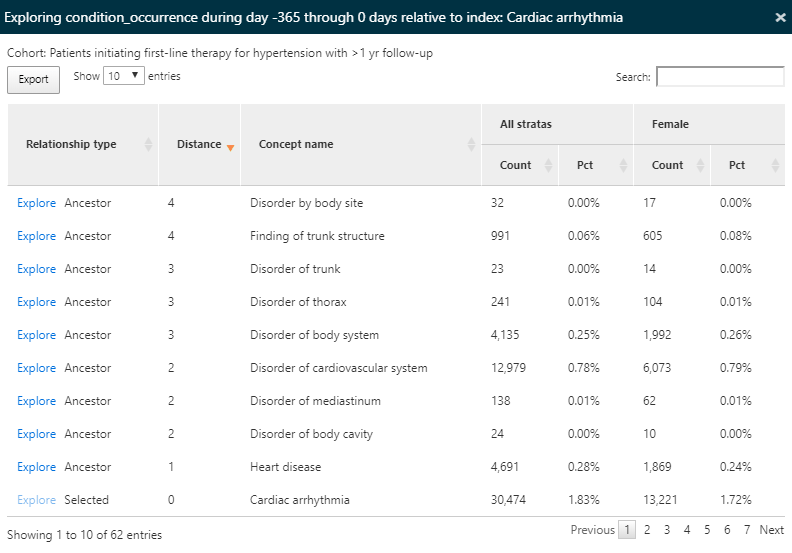
Figure 11.11: 특성 분석 결과 - 하나의 concept에 대하여 자세한 내용이 들어 있는 새로운 창.
분석하고자 하는 코호트에 대하여 모든 condition에 대한 개념을 분석하고 나면, 탐색 옵션을 통해 선택된 모든 개념의 모든 상, 하위 관계에 있는 개념을 확인할 수 있다. 본 연구의 경우 심부정맥에 관하여 확인했다. 이와 같은 탐색 기능은 개념의 계층 구조를 탐색 할 수 있도록 하며, 고혈압 환자에서 나타날 수 있는 다른 심장 질환을 확인할 수 있도록 한다. 요약된 결과처럼 (갯)수와 백분율로써 화면에 출력된다.
같은 특성 분석은 혈관 부종과 같은 항고혈압제제의 부작용에 의한 상태를 찾는 분석에도 사용할 수 있다. 방법은 위의 분석과 같이 그림 11.12에 나온 것처럼 ’부종 edema’를 검색하여 진행할 수 있다:
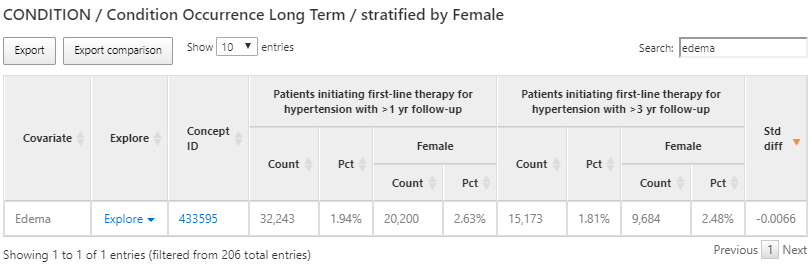
Figure 11.12: 특성 분석 결과 - 금기 상태 contraindicated condition를 탐색한 결과.
다시 한번, 고혈압 환자에서 혈관 부종의 발병률을 알아보기 위해 부종의 특성을 보는 탐색 기능을 사용할 것이다:
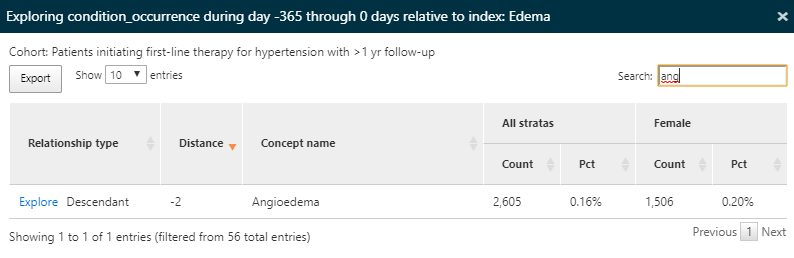
Figure 11.13: 특성 분석 결과 - 금기 상태에 대한 자세한 결과.
항고혈압제제를 시작하기 1년 전부터 혈관 부종의 기록이 있었던 사람의 비율을 확인할 수 있었다.
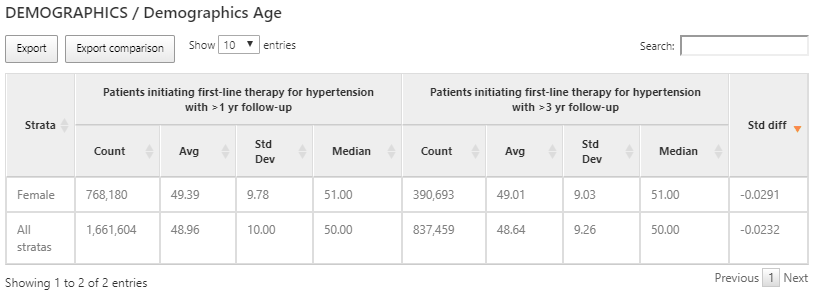
Figure 11.14: 각 코호트와 하위 집단의 연령 관련 특성 분석 결과.
도메인 변수는 이분 변수 binary variable를 사용해 계산되는 반면 (즉, 과거력 유/무), 코호트 시작 시점의 연령과 같은 일부 변수는 연속적인 값 continuous variable을 갖는다. 위의 예시와 같이 두 코호트에서 연령에 대한 특성 분석 결과는 사람의 총 수, 연령의 평균, 연령의 중앙값 그리고 표준 편차를 통해 확인할 수 있었다.
11.7.4 사용자-정의 속성 Defining Custom Features
사전에 정의되어 제공되는 특성뿐 아니라 ATLAS에서는 사용자가 필요에 따라 특성을 주문 제작하고 정의할 수 있는 기능을 지원한다. 왼쪽 메뉴에서 characterization을 클릭하고, Feature Analysis 탭을 클릭한 후, New Feature Analysis 버튼을 클릭하면 사용자가 정의한 속성 분석을 할 수 있다. 사용자가 원하는 속성 분석을 정의하고, 버튼을 통해 저장할 수 있다.
예를 들어, 코호트 시작 이후에 ACE inhibitors의 drug era를 갖는 각각의 코호트에 속하는 사람 수를 알아본다고 하자:
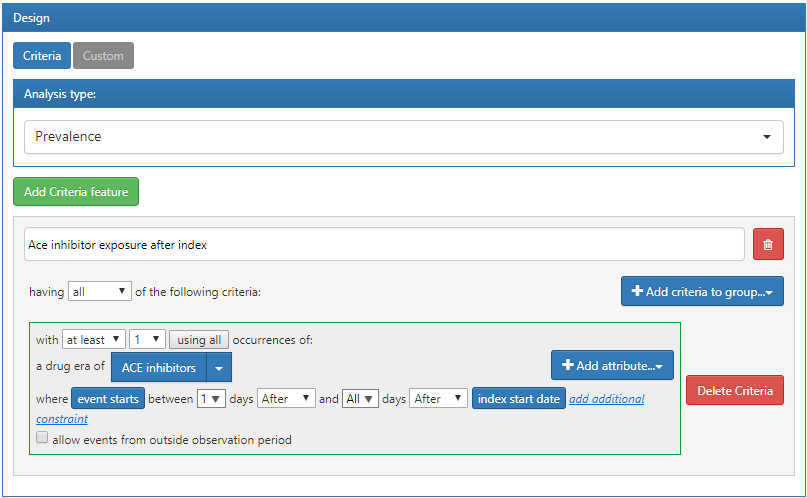
Figure 11.15: ATLAS를 이용한 사용자가 정의하는 속성.
위에서 정의한 기준은 코호트 시작 날짜에 적용된다고 가정하자. 이전에 정의한 기준을 저장했다면, 이전 절에서 디자인한 특성 분석에 이를 적용할 수 있다. 이는 위해 characterization을 열고, Feature Analysis로 이동해 보자. 버튼을 누르고 메뉴에서 new custom features를 선택하자. 그러면 분석할 특특성 목록에 사용자 정의 속성이 올라간 것이 보일 것이다. 앞 절에서 설명한 것과 같이 사용자 정의 속성에 대한 분석을 데이터베이스에 적용하여 시행할 수 있다:

Figure 11.16: 사용자 정의 속성을 적용하여 특성 분석을 진행한 결과 창
11.8 R을 이용한 코호트 특성 분석
코호트의 특성 분석은 R을 통해서도 가능하다. R에서 고혈압 코호트에서 기저 특성(변수)을 생성하기 위해 OHDSI의 FeatureExtraction이라고 하는 R package를 사용하는 방법을 알아보기로 한다. FeatureExtraction은 세 가지 방법으로 변수를 구성할 수 있는 기능을 제공한다. 그 방법은 다음과 같다:
- 기본 설정된 변수 모음을 선택
- 사전 지정된 분석 모음 중에서 선택
- 사용자 정의 분석 모음 생성
FeatureExtraction은 개인 수준 특성 person-level feature과 통합된 특성의 두 가지 방법으로 변수를 만든다. 개인 수준의 특성은 기계 학습에 적용할 때 유용하다. 이 절에서는 관심 코호트를 설명하는 기저 변수를 생성할 때 유용한 통합된 특성의 사용 방법을 집중적으로 설명할 것이다. 더불어 사전 지정된 분석과 사용자가 정의하는 분석의 두 가지 변수를 구성 방법에 대해 알아볼 것이다. (기본 설정 모음에 대해서는 독자의 연습을 위해 남겨두도록 하겠다)
11.8.1 코호트 생성 Cohort Instantiation
특성 분석을 위해 우선 코호트를 예시를 들어 설명하겠다. 코호트 생성 예시는 10장에서 실습했었다. 본 실습에서는 고혈압의 1차 약물치료를 시작한 사람 중 1년간 관찰된 사람을 사용할 것이다 (부록 B.6). 부록 B의 다른 코호트는 독자의 연습을 위해 남겨두었다. cohort definition ID가 1인 scratch.my_cohorts라는 테이블에 실습에 사용할 코호트가 있다고 가정하자.
11.8.2 데이터 추출 Data Extraction
먼저 R이 서버에 접속할 수 있도록 해야 한다. FeatureExtraction은 DatabaseConnector package의 createConnectionDetails 함수를 이용해 서버와 연결할 수 있다. ?createConnectionDetails를 입력하면 다양한 데이터베이스 관리 시스템(DBMS)이 요구하는 설정값이 어떤 것이 있는지 확인할 수 있다. 예를 들어, PostgreSql 데이터베이스와 연결해야 하는 경우 다음과 같이 연결 설정을 해야 한다:
library(FeatureExtraction)
connDetails <- createConnectionDetails(dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
cdmDbSchema <- "my_cdm_data"
cohortsDbSchema <- "scratch"
cohortsDbTable <- "my_cohorts"
cdmVersion <- "5"마지막 네 줄의 코드는 cdmDbSchema, cohortsDbSchema, cohortsDbTable 변수를 정의하고 CDM 버전 또한 정의하기 위함이다. 이러한 정의는 나중에 R에게 CDM 형식의 데이터가 있는 위치, 관심 코호트가 만들어진 위치, 어떤 버전의 CDM이 사용되었는지를 확인할 수 있도록 해준다. Microsoft SQL Server에서 주의할 점은, 데이터베이스 스키마는 데이터베이스와 스키마 정보를 둘 다 필요로 한다는 것이다. 예를 들면 다음과 같다. cdmDbSchema <- "my_cdm_data.dbo".
11.8.3 미리 만든 분석 정의 사용 Using Prespecified Analyses
createCovariateSettings 함수는 사전에 정의된 대규모 변수의 모음을 선택할 수 있도록 한다. ?createCovariateSettings를 입력하면 사용 가능한 옵션을 확인할 수 있다. 예를 들어:
settings <- createCovariateSettings(
useDemographicsGender = TRUE,
useDemographicsAgeGroup = TRUE,
useConditionOccurrenceAnyTimePrior = TRUE)다음과 같이 입력하면 성별, 연령 (5년 단위의 연령 그룹), 그리고 코호트 시작 날짜를 포함한 이전의 모든 condition_occurrence 테이블에서 관찰된 각각의 concept에 대하여 이분 변수 binary variable를 생성할 수 있다.
많은 사전 정의 분석은 단기 short term, 중기 medium term, 혹은 장기 long term 구간 time window을 지정할 수 있다. 기본적으로 구간은 다음과 같이 정의되어 있다:
- Long term : 코호트 시작 날짜를 포함한 365일 이전까지의 구간.
- Medium term : 코호트 시작 날짜를 포함한 180일 이전까지의 구간.
- short term : 코호트 시작 날짜를 포함한 30일 이전까지의 구간.
그러나 아래의 예시와 같이 사용자가 시간 구간을 변경 할 수 있다:
settings <- createCovariateSettings(useConditionEraLongTerm = TRUE,
useConditionEraShortTerm = TRUE,
useDrugEraLongTerm = TRUE,
useDrugEraShortTerm = TRUE,
longTermStartDays = -180,
shortTermStartDays = -14,
endDays = -1)이 코드에서 새로 정의된 장기 구간은 코호트 시작 날짜를 포함하지 않고 180일 이전까지의 구간을 나타내고, 단기 구간은 코호트 시작 날짜를 포함하지 않고 14일 이전까지의 구간을 나타낸다. 또한, 변수 구성에서 필수적으로 들어가야 할 것과 빠져야 할 concept ID를 지정할 수 있다:
settings <- createCovariateSettings(useConditionEraLongTerm = TRUE,
useConditionEraShortTerm = TRUE,
useDrugEraLongTerm = TRUE,
useDrugEraShortTerm = TRUE,
longTermStartDays = -180,
shortTermStartDays = -14,
endDays = -1,
excludedCovariateConceptIds = 1124300,
addDescendantsToExclude = TRUE,
aggregated = TRUE)aggregated = TRUE로 바꾸면 위에 표시된 모든 사례에 대하여 FeatureExtraction으로 하여금 모든 요약 통계치를 표시하도록 한다. 이 지표를 제외하면 코호트 내의 각 사람에 대한 변수값이 계산될 것이다.
11.8.4 통합된 변수의 생성 Creating Aggregated Covariates
다음의 코드는 코호트에 대한 통합 공변량을 생성하도록 한다:
covariateSettings <- createDefaultCovariateSettings()
covariateData2 <- getDbCovariateData(
connectionDetails = connectionDetails,
cdmDatabaseSchema = cdmDatabaseSchema,
cohortDatabaseSchema = resultsDatabaseSchema,
cohortTable = "cohorts_of_interest",
cohortId = 1,
covariateSettings = covariateSettings,
aggregated = TRUE)
summary(covariateData2)그 결과값은 다음과 비슷하게 보일 것이다:
## CovariateData Object Summary
##
## Number of Covariates: 41330
## Number of Non-Zero Covariate Values: 4133011.8.5 결과 형식 Output Format
통합된 공변량 데이터 covariateData에서 주요한 두 가지 구성요소는 이분 binary 혹은 연속적 continuous변수에 대한 공변량 covariates과 공변량 양 covariatesContinuous이다:
covariateData2$covariates
covariateData2$covariatesContinuous11.8.6 사용자 정의 공변량 Custom Covariates
FeatureExtraction은 또한 공변량을 사용자가 정의하고 사용할 수 있도록 사용자 정의 공변량 기능을 제공한다. 이는 고급 주제로 다음 링크를 통해 사용자 문서에서 자세히 볼 수 있다: http://ohdsi.github.io/FeatureExtraction/.
11.9 ATLAS에서 코호트 경로 Cohort Pathways in ATLAS
경로 분석은 하나 이상의 관심 코호트에서 치료 과정의 순서를 이해하기 위해 시행한다. 분석 방법은 Hripcsak의 연구 (Hripcsak et al. 2016) 의 디자인을 기반으로 한다. 이 방법은 ATLAS의 Cohort Pathways 기능으로 일반화되고 체계화되었다.
Cohort pathways는 하나 이상의 분석하고자 하는 대상 코호트 target cohort의 코호트 시작 날짜 이후 발생한 사건을 요약하는 분석 기능 제공을 목표로 한다. 이를 위해 분석 대상 모음에서 관심 임상 사건을 식별하기 위한 사건 코호트 event cohort 모음을 정의하고 생성해야 한다.
대상 코호트에서 한 환자를 어떻게 찾는지를 보면 다음과 같다:
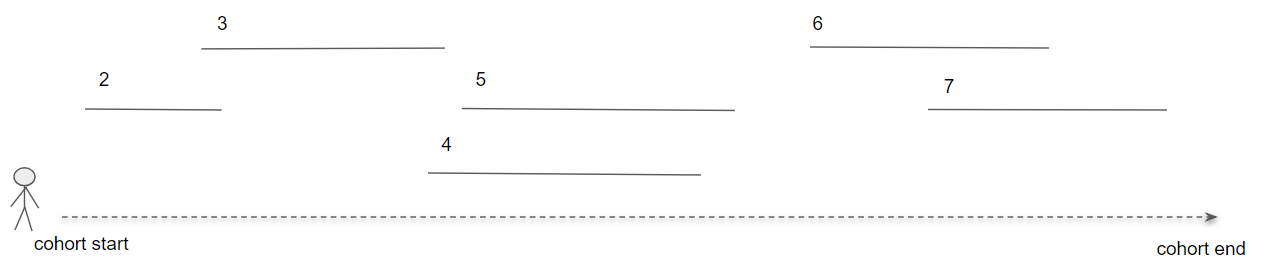
Figure 11.17: 한 환자의 경로 분석의 내용.
그림 11.17에서 대상 코호트에 속한 환자의 정의된 시작과 마지막 날짜를 볼 수 있다. 숫자가 매겨진 조각난 선은 해당 환자에게서 해당 구간 동안 사건 코호트가 발생한 위치를 표현한 것이다. 사건 코호트를 통해 CDM에서 표현되는 관심 있는 모든 임상적 사건을 설명 할 수 있기 때문에 단일 도메인 혹은 개별 concept에 대한 경로를 만드는 데 제한을 받지 않는다.
경로 분석을 시작하기 위해서는 ATLAS 왼쪽 바에 있는  를 눌러 새로운 코호트 경로 분석 연구를 생성한다. 분석을 명명하고 저장 버튼을 눌러 저장한다.
를 눌러 새로운 코호트 경로 분석 연구를 생성한다. 분석을 명명하고 저장 버튼을 눌러 저장한다.
11.9.1 디자인
사용할 코호트는 고혈압 1차 치료를 시작하고 환자 1년간 관찰된 환자 코호트와 3년간 추적 관찰된 환자 코호트로 이전 분석에서 사용된 코호트를 지속해서 사용할 것이다 (부록 B.6과 B.7). 두 개의 코호트를 불러오기 위해 버튼을 사용하자.
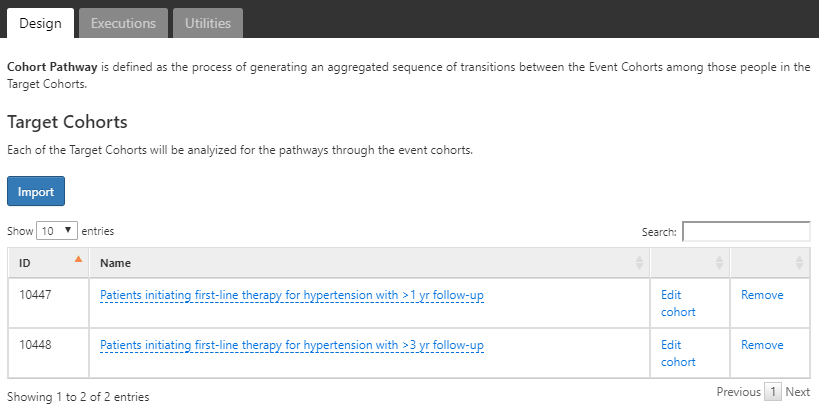
Figure 11.18: 선택된 대상 코호트를 이용한 경로 분석.
그 다음, 각각 분석하고자 하는 일차 고혈압 치료 약제에 대한 코호트를 사건 코호트로 정의한다. 이를 위해 ACE inhibitor 사용에 대한 코호트를 생성하고 코호트 마지막 날짜를 약물의 마지막 노출이 끝나는 날짜로 정의한다. 여덟 개의 다른 고혈압 약제에 대하여 같은 방식으로 코호트를 생성하고, 코호트 생성에 필요한 여러 정의는 부록 B.8-B.16에서 찾아볼 수 있다. 완료한 후 버튼을 눌러 경로 분석 디자인의 Event Cohort 부분에 삽입한다:
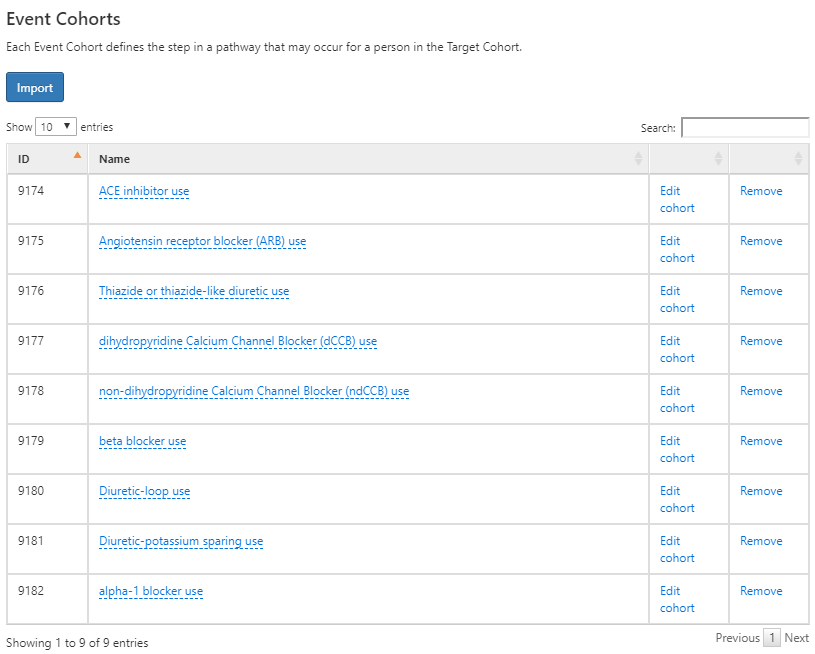
Figure 11.19: 고혈압 일차 치료 시작의 경로 분석을 위한 사건 코호트.
모든 과정을 완료하고 나면 다음과 같이 된다. 그 이후에 몇 가지 추가 설정을 해야 한다:
- Combination window: 이 세팅을 사용하면 사건이 겹쳐질 경우 사건을 조합 combination으로 간주할 수 있도록 하는 시간 구간 window of time 설정할 수 있도록 해주며, 일 days 단위로 정의할 수 있도록 한다. 예를 들어, 만약 두 개의 사건 코호트 (사건 코호트 1과 사건 코호트 2)로 정의한 두 개의 약물이 그 조합 구간 combination window안에 노출 시간이 겹치면 경로 알고리즘은 두 사건 코호트를 합쳐서 “사건 코호트 1 + 사건 코호트 2”로 만든다.
- Minimum cell count: 사건 코호트가 이 수보다 적으면 개인정보 보호를 위해 결과에서 제외된다.
- Max path length: 최대의 연속 사건 sequential event의 수 (pathway 몇 단계까지 볼 것인지 설정)
11.9.2 실행 Executions
경로 분석의 디자인이 완료된 후, 하나 이상의 데이터베이스 내에서 분석 실행 execution할 수 있다. 방법은 ATLAS의 코호트 특성 분석에서 진행한 것과 같은 방식으로 진행된다. 실행이 끝나면 분석 결과를 확인할 수 있다.
11.9.3 결과 시각화
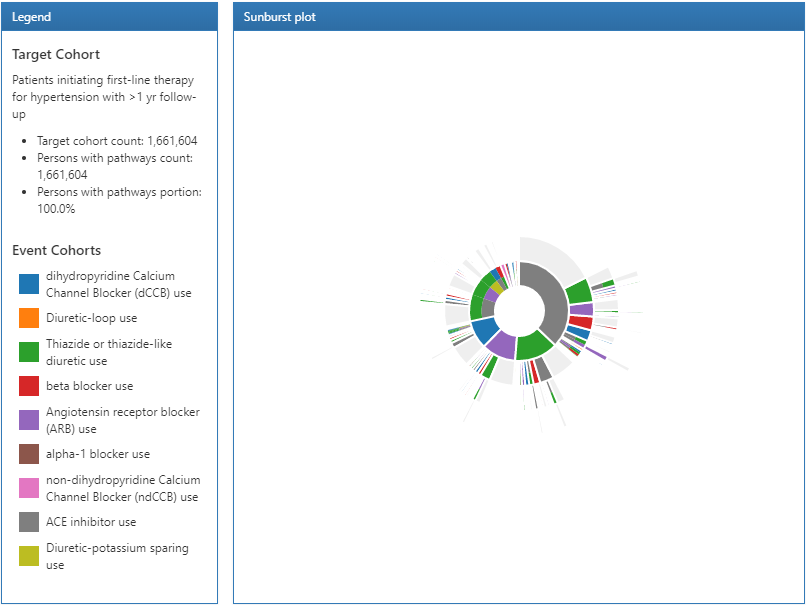
Figure 11.20: 경로 분석 결과의 범례와 sunburst 그래프를 통한 시각화.
경로 분석에 관한 결과는 3개의 부분으로 나누어진다. 범례 legend 부분은 대상 코호트의 총 환자 수를 나타내는데, 이는 하나 이상의 사건이 있는 환자 수를 나타낸다. 아래의 요약은 sunburst plot의 가운데 부분을 각 코호트에 색을 지정해 표현하였다.
sunburst plot은 시간에 따라 한 사람이 겪는 다양한 사건 경로를 시각화한다. 그래프의 가운데 부분은 코호트의 시작 부분을 나타내고 첫 번째 색으로 구분된 고리는 전체 코호트에서 각 사건 코호트의 환자 비율을 보여준다. 본 예시에서 가장 가운데의 원은 고혈압 환자가 처음으로 시작한 일차 약제를 의미한다. 그리고 sunburst plot의 첫 번째 고리는 사건 코호트에서 정의한 것과 같이 시작한 일차 약제의 유형별 비율을 나타낸다 (예를 들어, ACE inhibitor, Angiotensin receptor blocker 등). 두 번째 모음의 고리는 환자의 두 번째 사건 코호트를 의미한다. 특정 사건의 과정에서, 어떤 환자는 두 번째 사건 코호트를 가지지 않을 수 있는데, 그럴 경우 그 비중은 고리에서 (연한) 회색으로 표현되어 있다 (역자 주: 즉 첫 번째 약만 복용한 경우).
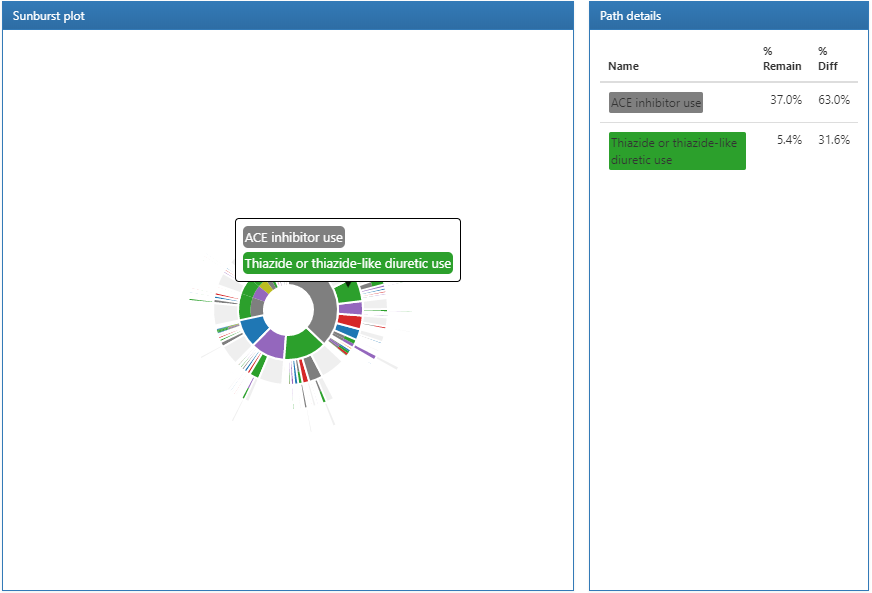
Figure 11.21: 더 자세한 경로 분석의 결과 창.
sunburst plot의 세션을 클릭하면 오른편에 세부 경로가 나타난다. 이를 통해 대상 코호트에서 가장 많은 비율을 차지하는 환자가 일차 약제로 ACE inhibitor를 시작한 환자임을 알 수 있고, 가장 작은 비율을 차지하는 약제는 thiazide나 thiazide diuretics임을 알 수 있다.
11.10 ATLAS를 이용한 발생률 분석
발생률 계산 시 대상 코호트의 사람 중 위험 노출 기간 동안 결과 코호트를 경험한 환자에 대하여 설명하도록 한다. 예를 들어, ACE inhibitor(ACEi)를 시작한 사람과 Thiazides와 tiazide-like diuretics(THZ)를 시작한 사람 중 혈관 부종과 급성 심근경색 outcome 발생을 분석하는 발생률 분석을 디자인했다고 하자. 이를 위해 약물에 노출된 사람의 위험 노출 기간 동안 이 outcome을 평가해야 한다. 더불어, Angiotensin receptor blockers(ARBs)에 대한 약물 노출 결과를 추가하기 위해 대상 코호트 (ACEi와 THZ)에 속해 있는 동안 ARBs 약물 사용의 발생을 outcome으로 추가한다. 이 outcome은 대상 코호트에 속해있는 동안 얼마나 ARBs 사용이 발생했는지를 측정해 줄 수 있다.
발생률 분석을 시작하기 위해서는 ATLAS의 왼쪽 바에서  버튼을 누른다. 분석의 이름을 적고 버튼을 눌러 저장한다.
버튼을 누른다. 분석의 이름을 적고 버튼을 눌러 저장한다.
11.10.1 디자인
이미 이전 10장에서 ATLAS로 예제에 사용할 코호트를 만들었다고 가정해 보자. 부록에서 예제에 사용할 대상 코호트 (부록 B.2, B.5)의 모든 정의와 결과 (부록 B.4, B.3, B.9)를 확인할 수 있다.

Figure 11.22: 발생률 분석에 사용할 대상 코호트와 결과 코호트의 정의.
definition 탭을 클릭해서 New users of ACE inhibitors 코호트와 New users of Thiazide or Thiazide-like diuretics 코호트를 선택한다. 선택한 코호트가 분석 디자인에 추가되었는지 확인하기 위해 대화 상자를 닫아야 한다. 그다음 대화 상자에서 클릭해 결과 코호트를 추가한다. acute myocardial infarction events, angioedema events와 Angiotensin receptor blocker(ARB) use 코호트 등이 결과 코호트로 선택되어야 한다. 분석 디자인에 결과 코호트가 추가되었는지 확인하기 위해 대화 상자를 닫아야 한다.
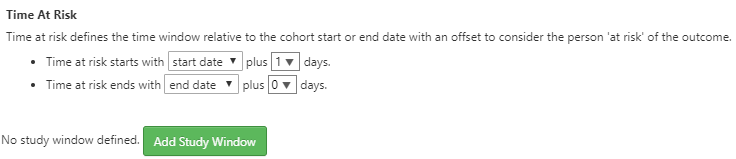
Figure 11.23: 발생률 분석에 사용할 대상 코호트와 결과 코호트의 정의.
이후 분석에 필요한 위험 노출 기간을 정의해야 한다. 위에서 보이는 바와 같이 위험 노출 기간은 코호트 시작과 마지막 날짜에 기반하여 정해진다. 예제에서는 위험 노출 기간의 시작일을 대상 코호트의 코호트 시작일보다 1일 후로 정의했다. 위험 노출 기간의 마지막 날짜는 코호트 마지막 날짜로 정의했다. 이 경우, ACEi와 THZ 코호트는 코호트의 정의에 따라 약물 노출이 끝나면 코호트 또한 종료된다.
ATLAS는 또한 분석의 선택 사항의 일부분으로 대상 코호트의 층화 기능을 제공한다:
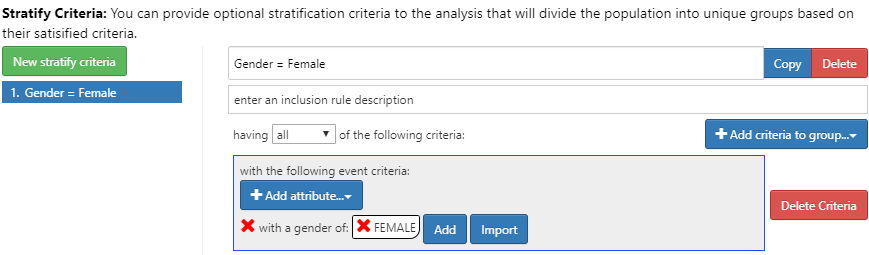
Figure 11.24: 여성에 대한 층화를 정의한 발생률.
분석을 위해서 New Stratify Criteria 버튼을 누르고 11장에서 설명한 것과 같은 단계로 진행한다. 분석 디자인이 완성되면 하나 이상의 데이터베이스를 이용해 실행할 수 있다.
11.10.2 실행
Generation 탭을 누르고  버튼을 클릭하면, 분석에 사용할 데이터베이스 목록을 볼 수 있다:
버튼을 클릭하면, 분석에 사용할 데이터베이스 목록을 볼 수 있다:
Figure 11.25: 발생률 분석의 실행.
하나 이상의 데이터베이스를 선택하고 Generate 버튼을 누르면 주어진 분석 디자인의 대상과 결과의 모든 조합에 대하여 발생 분석이 실행된다.
11.10.3 결과 보기
Generation 탭의 상단의 화면은 결과를 확인할 때 대상과 결과를 선택할 수 있도록 해준다. 바로 아래에는 분석에 사용된 각 데이터베이스에 대한 요약과 발생에 관한 내용이 표시된다.
대상 코호트 중 ACEi 사용자와 outcome 코호트 중에서 Acute Myocardial Infarction(AMI)을 드롭다운 목록에서 선택해 보자. 그리고  버튼을 누르면 발생 분석의 결과가 나온다:
버튼을 누르면 발생 분석의 결과가 나온다:
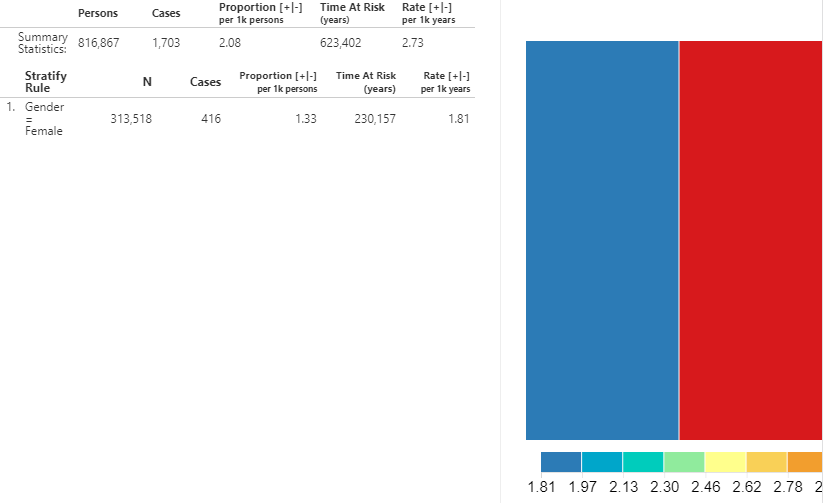
Figure 11.26: ACEi 의 새로운 사용자에서 AMI의 발생률을 분석한 결과.
결과를 통해 데이터베이스 내 해당 코호트에서 위험 노출 기간 동안 발생한 모든 증례에 해당하는 전체 환자 수를 요약해 보여준다. 발생 비율은 1,000명당 발생 건수로 표시한다. 위험 노출 기간은 대상 코호트에서 연 단위로 계산된다. 발생률은 1,000인-년당 발생 건수로 표현된다.
또한 분석 디자인에서 층화를 위해 정의 한 계층에 대한 발생률을 확인할 수 있다. 각 계층에 대해 위에 언급한 바와 동일한 방식으로 계산되었다. 더불어, 트리 맵 시각화 방법을 통해 각 계층의 비율을 상자 공간으로 표현했다. 아래 눈금에 표시된 대로 색상은 발생률을 나타낸다.
ACEi 환자군 내에서 ARBs를 새롭게 사용하기 시작한 신규 환자군의 발생을 확인하기 위한 정보도 얻을 수 있다. 상단의 드롭다운을 사용하여 ARBs의 사용으로 outcome을 바꾸고, 버튼을 누르면 자세한 내용이 나타난다.
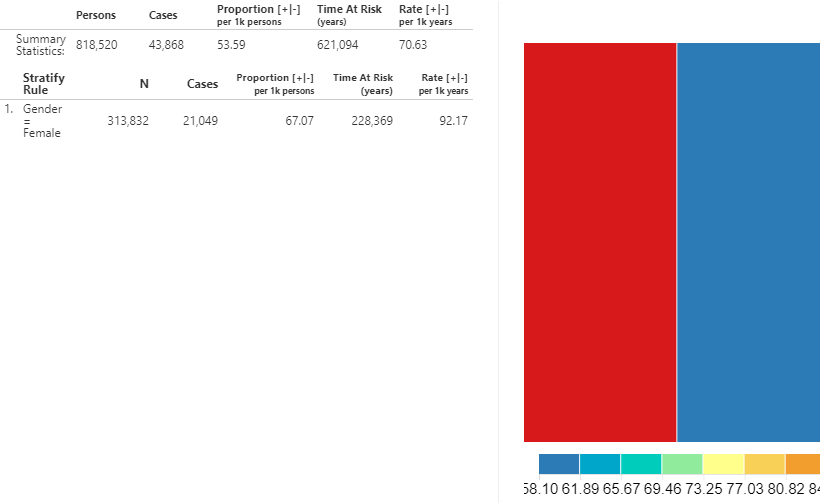
Figure 11.27: 발생률 - ACEi 노출 기간 중 ARBs 치료를 새로 시작한 ACEi 사용 환자군.
위에 보이는 것처럼, 지금까지 사용한 방법과 동일한 방식으로 계산되었지만, 입력값이 (ARB 사용) 건강에 대한 outcome에서 약물 사용에 대한 평가로 바뀌었기 때문에 해석이 달라진다.
11.11 요약
OHDSI는 모든 데이터베이스 혹은 관심 코호트에 대한 특성을 분석하는 도구를 제공한다.
코호트의 특성 분석은 index date 이전 (baseline)과 index date 후 (post-index) 시간 동안의 관심 코호트를 설명해 준다.
ATLAS의 특성 분석 모듈과 OHDSI 연구방법론 라이브러리 Methods Library는 다양한 관찰 기간에 대한 기저 특성에 대해 계산 할 수 있는 기능을 제공한다.
- ATLAS의 경로 pathway와 발생률 incidence모듈은 index date 이후 시간 동안의 기술 통계를 제공한다.
11.12 예제
전제조건
본 예제를 위해 ATLAS에 접근할 수 있어야 한다. 다음의 ATLAS를 사용하거나 http://atlas-demo.ohdsi.org, 혹은 개별적으로 구축하여 접속 가능한 ATLAS가 있다면 사용해도 좋다.
Exercise 11.1 실제 임상에서 celecoxib가 얼마나 사용되는지를 알고 싶다. 시작하기에 앞서 데이터베이스에 약물에 대한 데이터베이스의 데이터를 이해해야 한다. ATLAS의 Data Sources를 이용해 celecoxib에 대한 정보를 찾아보자.
Exercise 11.2 celecoxib 사용자의 질병 자연 경과에 대해 더 알고 싶다. celecoxib의 새로운 사용자에 대한 간단한 코호트를 만들어 보자. 이때, 365일의 휴약 washout 기간을 설정하자 (어떻게 해야 하는지 자세히 알고 싶다면 10장을 참고한다). 그리고 ATLAS에서 이 코호트의 characterization을 생성하고, 동반 상병 질환과 약물 노출을 찾아보자.
Exercise 11.3 celecoxib 치료를 받는 사람이 이후 기간에 상관없이 위장관 출혈 gastrointestinal(GI) bleeds가 얼마나 자주 발생하는지를 알고 싶다. 우선 GI bleed의 사건 코호트를 생성해야 한다. 해당 코호트의 정의를 위해 192671 (“Gastrointestinal hemorrhage”)으로 정의된 concept이나 그 하위 concept을 사용하자. 이전 예제에서 정의한 약물 노출 코호트를 이용해, celecoxib을 시작한 이후 GI bleed의 발생률을 계산하자.
답변은 부록 E.7 에서 찾을 수 있다.
References
Elm, Erik von, Douglas G. Altman, Matthias Egger, Stuart J. Pocock, Peter C. Gøtzsche, and Jan P. Vandenbroucke. 2008. “The Strengthening the Reporting of Observational Studies in Epidemiology (Strobe) Statement: Guidelines for Reporting Observational Studies.” Journal of Clinical Epidemiology 61 (4): 344–49. doi:10.1016/j.jclinepi.2007.11.008.
Hripcsak, George, Patrick B. Ryan, Jon D. Duke, Nigam H. Shah, Rae Woong Park, Vojtech Huser, Marc A. Suchard, et al. 2016. “Characterizing treatment pathways at scale using the OHDSI network.” Proceedings of the National Academy of Sciences 113 (27). National Academy of Sciences: 7329–36. doi:10.1073/pnas.1510502113.
Who, A. 2013. “Global Brief on Hypertension.” World Health Organization. https://www.who.int/cardiovascular_diseases/publications/global_brief_hypertension/en/.