Chapter 18 방법론적 타당성
Chapter lead: Martijn Schuemie
이번 장에서 우리는 다음의 질문에 대해 답하려 한다.
우리의 방법론은 연구 질문에 대해 답하기에 유효한가?
“방법 method”에는 연구 설계뿐만 아니라 데이터와 설계의 시행도 포함된다. 따라서, 방법론적 타당성은 다소 포괄적이다. 좋은 자료의 질, 임상적 타당성 및 소프트웨어 타당성 없이 좋은 방법의 유효성을 논하는 것은 때때로 불가능하다. 근거의 질적 측면은 이미 방법론적 타당성을 고려하기 전에 별도로 다루어져야 한다.
방법론적 타당성을 확립할 때 핵심 행동은 분석에서 중요한 가정이 충족되었는지의 여부를 평가하는 것이다. 예를 들어, 우리는 성향 점수 짝짓기가 두 집단을 비교할 수 있게 한다고 가정하지만, 이것이 사실인지 평가할 필요가 있다. 가능한 경우, 이러한 가정을 검증하기 위해 경험적 검정을 해야 한다. 예를 들어, 우리는 두 집단이 실제로 짝짓기 후에 넓은 범위의 특성에서 비교 가능하다는 것을 보여주기 위해 진단을 생성할 수 있다. OHDSI에서 우리의 분석이 수행될 때마다 생성되고 평가되어야 하는 많은 표준화된 진단을 개발하였다.
이 장에서는 인구 수준 추정에 사용되는 방법의 타당성에 초점을 맞출 것이다. 먼저, 일부 연구 설계별 진단을 간략히 강조한 다음, 모든 모집단 수준의 추정 연구가 아닌 대부분의 진단에 적용 가능한 진단에 대해 논의할 것이다. 다음은 OHDSI 도구를 사용하여 이러한 진단을 수행하는 방법에 대한 단계별 설명이다. 우리는 OHDSI Methods Benchmark와 OHDSI 연구방법론 라이브러리 Methods Library에 대한 적용에 대해 검토하면서 이 장의 주제를 마무리한다.
18.1 설계별 진단
각 연구 설계에 대해 해당 설계마다 특정한 진단이 있다. 이러한 진단 중 많은 부분이 OHDSI 연구방법론 라이브러리의 R 패키지로 구현이 되어있고, 쉽게 사용할 수 있다. 예를 들어, 12.9절에는 OHDSI Methods Library 패키지에서 생성된 광범위한 진단이 나열되어 있다:
- 코호트의 초기 비교성을 평가하기 위한 성향 점수 분포 Propensity score distribution.
- 모형에서 제외해야 하는 잠재적 변수를 식별하기 위한 성향 모델 Propensity model.
- 성향 점수 propensity score 보정을 통해 코호트를 비교할 수 있는지 평가 (기저 공변량을 통해 측정)를 위한 공변량 균형 Covariate balance.
- 다양한 분석 단계에서 몇 명의 피험자가 제외되었는지를 관찰하여, 초기 관심 집단에 대한 결과의 일반화 가능성을 알리기 위한 손실표 Attrition.
- 질문에 대답하기에 충분한 데이터가 있는지 평가하기 위한 검정력 Power.
- 일반적인 관찰 시작 시간을 평가하고 콕스 Cox 모델의 비례 가정이 충족되는지 여부를 위한 Kaplan Meier curve.
다른 연구 설계는 이러한 설계의 다른 가정을 검정하기 위해 다른 진단이 필요하다. 예를 들어, 자기-대조군 환자 시리즈(SCCS) 설계의 경우 관찰의 종료가 결과와는 무관하다는 필수 가정을 확인할 수 있다. 이 가정은 심근 경색과 같이 심각하고 잠재적으로 치명적인 사건의 경우에서 종종 위반된다. 우리는 관찰 기간 종료의 시점이 중도 절단과 중도절단 되지 않은 시점을 보여주는 히스토그램인 그림 18.1에 표시된 도표를 생성하여 가정이 유지되는지의 여부를 평가할 수 있다. 데이터에서 관찰 기간이 데이터 수집의 종료 날짜 (전체 데이터베이스에서 관찰이 중단된 날짜, 예를 들어, 추출 날짜 또는 연구 종료 날짜)를 중도절단 되지 않은 것으로 간주하고, 다른 모든 관찰을 중도 절단한 것으로 간주한다. 그림 18.1에서 우리는 두 분포 사이의 사소한 차이만을 보고도, 우리의 가정이 유지된다는 것을 시사한다.
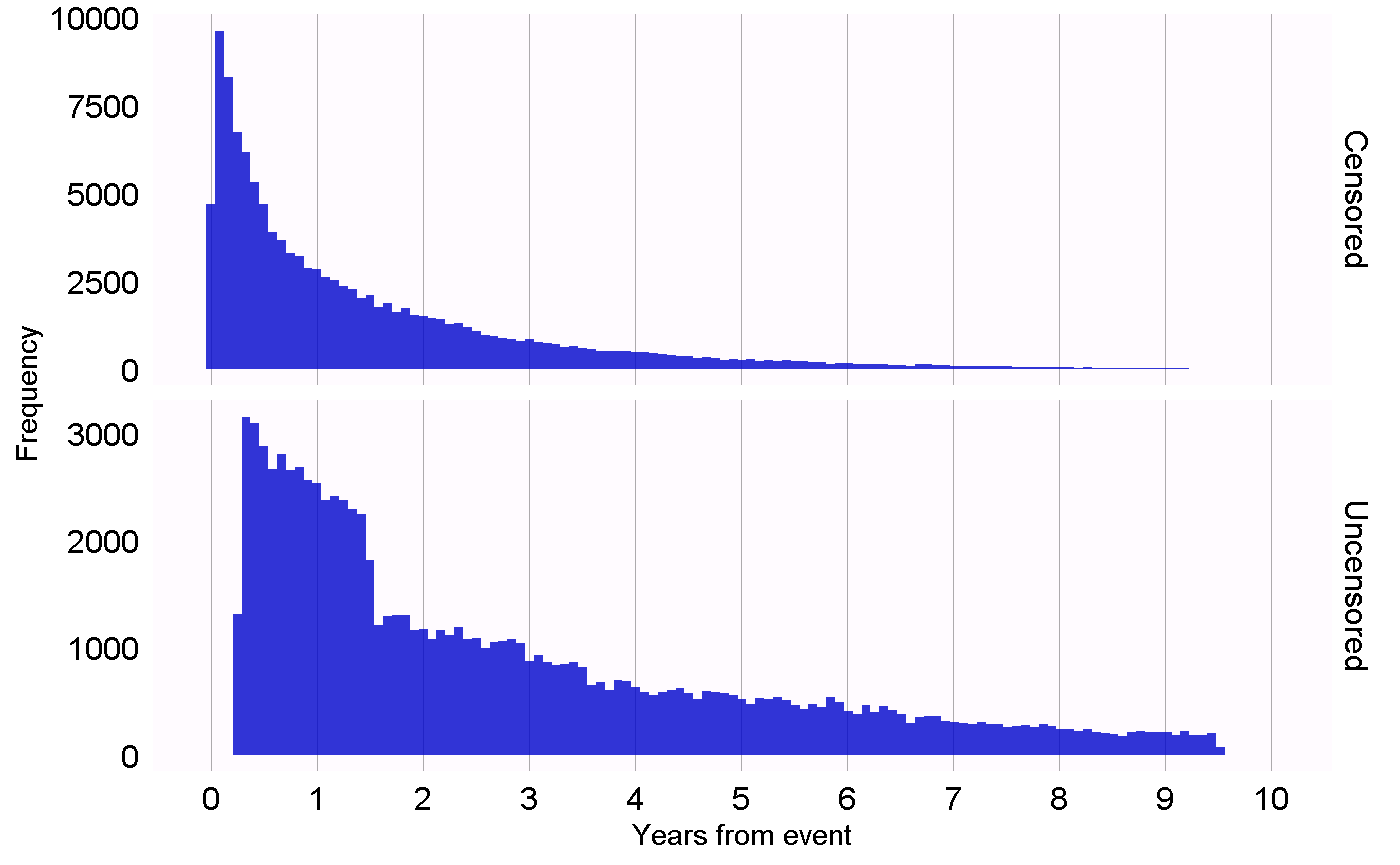
Figure 18.1: 중도 절단된 사람과 중도절단 되지 않은 사람에 대한 관찰 종료 시간.
18.2 모든 추정을 위한 진단법
연구 설계 특이적인 진단 후, 모든 인과 효과 추정 방법에 걸쳐 적용 가능한 몇 가지 진단법이 있다. 이 중 대부분이 대조 가설의 사용과 해답이 이미 알려진 연구 질문에 의존한다. 대조군 가설을 활용하면 우리의 설계가 사실과 일치하는 결과를 산출하는지 평가할 수 있다. 대조군은 음성 대조군과 양성 대조군으로 나눌 수 있다.
18.2.1 음성 대조군
음성 대조군은 인과적 효과가 없을 것으로 생각되는 노출-결과 쌍이며, 교란 confounding, (Lipsitch, Tchetgen Tchetgen, and Cohen 2010) 선택비뚤림 selection bias, 측정 오류 measurement error를 감지하기 위한 수단으로 권장해온 음성 대조군 혹은 “falsification endpoints” (Prasad and Jena 2013) 을 포함한다. (Arnold et al. 2016) 예를 들어, 소아기 질병과 후기 다발성 경화증 multiple sclerosis의 관계를 조사하는 한 연구에서 (Zaadstra et al. 2008), 저자는 다발성 경화증을 유발하지 않는 것으로 생각되는 세 가지 음성 대조군을 포함했다: 팔 골절, 뇌진탕, 편도선 절제술. 연구자의 분석 결과 이 세 가지 대조군 중 두 가지가 다발성 경화증과 통계적으로 유의한 연관성이 있는 것으로 나타났는데, 그것은 그 연구에 비뚤림이 있을 수 있음을 의미한다.
여러 음성 대조군 중에서 관심 가설과 비교 가능한 음성 대조군을 선택해야 한다. 즉, 일반적으로 관심 가설과 동일한 결과 (“결과 대조군 outcome controls”이라고 한다) 또는 동일한 노출(“exposure controls”)을 갖는 노출-결과 쌍을 선택해야 한다. 음성 대조군은 다음 기준을 충족해야 한다:
- 노출이 결과의 원인이 되어선 안 된다. 인과 관계를 생각하는 한 가지 방법은 반사실적 counterfactual인 사고이다: 환자가 노출된 경우와 비교하여 환자가 노출되지 않은 경우에서 결과가 초래 (혹은 예방) 될 수 있는가? 때로는 명확한데, 예를 들어 ACEi는 혈관 부종을 유발하는 것으로 알려져 있다. 다른 경우에는 훨씬 덜 명확하다. 예를 들어 고혈압을 유발할 수 있는 약물은, 고혈압의 결과인 심혈관 질환을 간접적으로 유발할 수 있다.
- 노출은 또한 결과를 예방하거나 치료해서도 안 된다. 이것은 단지 또 다른 인과관계로서, 실제 효과 크기가 1이라고 믿어야 할 경우에는 존재해서는 안 되는 인과 관계이다.
- 음성 대조군은 연구자가 가지고 있는 데이터에 존재해야 하며, 이상적으로는 충분한 숫자를 가지고 있어야 한다. 음성 대조군의 유병률에 따라 우선순위를 정해서 달성한다.
- 음성 대조군은 이상적으로 독립적이어야 한다. 예를 들어, 서로의 조상 (예를 들어, “내성 손톱”과 “내성 발톱”)이거나, 형제자매 (예를 들어, “fracture of left femur”나 “fracture of right femur”)인 음성 대조군은 피해야 한다 (개념간에 조상-자녀, 형제 관계에 있으면 안 된다).
- 음성 대조군은 이상적으로 어느 정도의 비뚤림의 가능성이 있어야 한다. 예를 들어, 누군가의 사회 보장 번호의 마지막 숫자는 기본적으로 임의의 숫자이며 교란을 의미하진 않는다. 따라서 음성 대조군으로 사용해서는 안된다.
음성 대조군이 노출-결과 쌍과 동일한 교란 요인 구조를 가져야 한다는 주장도 있다. (Lipsitch, Tchetgen Tchetgen, and Cohen 2010) 그러나, 우리는 이 교란 구조는 알 수 없다고 믿는다. 현실에서 발견되는 변수 사이의 관계는 때때로 사람들이 상상하는 것보다 훨씬 더 복잡하다. 또한, 교란 요인의 구조가 알려진 경우에도, 정확히 동일한 구조로 되어 있지만, 직접적인 인과 효과가 없는 음성 대조군이 존재할 가능성은 작다. 이런 이유로 OHDSI에서는 많은 수의 음성 대조군을 동시에 사용하는데, 그러한 다양한 음성 대조군 모음은 연구자가 설계한 연구의 비뚤림을 포함하여 다양한 유형의 비뚤림을 가지고 있을 것이기 때문이다.
노출과 결과 사이에 인과 관계가 없다는 것은 거의 출판 되어 있지 않다. 그래서 우리는 연관성에 대한 근거가 부족하다는 것이 연관성의 결여를 의미한다고 종종 가정한다. 노출과 결과 모두 광범위하게 연구되었으므로 연관성이 탐지될 수 있었다면 이 가정은 유지될 가능성이 더 높다. 예를 들어, 완전히 새로운 약물에 대한 근거의 부족은 연관성의 부족이 아니라 아직은 관련 지식이 부족함을 의미한다. 이러한 원칙을 염두에 두고 음성 대조군을 선택하기 위한 반 자동적인 절차를 개발하였다. (Voss et al. 2016) 간략하게 설명하면, 문헌, 제품 라벨 및 자발적 보고에 대한 정보를 자동으로 추출하고 합성하여 음성 대조군 후보 목록으로 생성한다. 이 목록은 자동화된 추출이 정확한지 검증하고, 또한 생물학적 타당성과 같은 추가 기준도 고려해야 하므로 사람의 직접 검토를 거쳐야 한다.
18.2.2 양성 대조군
실제 상대 위험이 1보다 작거나 클 때, 연구자의 연구 방법론이 어떻게 행동하는지 이해하려면 귀무가설이 참이 아닌 것으로 간주하는 양성 대조군을 사용해야 한다. 불행하게도, 관측 연구에 대한 실제 양성 대조군은 세 가지 이유로 문제가 되는 경향이 있다. 첫 번째, 대부분의 연구 상황에서, 예를 들어 두 치료의 효과를 비교할 때, 특정 상황과 관련된 양성 대조군이 부족하다는 점이다. 두 번째, 양성 대조군을 찾을 수 있더라도 효과 크기의 규모를 아주 정확히 알 수는 없으며, 때때로 효과 크기를 측정하는 모집단에 의존해야 한다는 점이다. 세 번째, 치료가 특정 결과를 유발하는 것으로 널리 알려진 경우, 예를 들면 원치 않는 결과의 위험을 완화하기 위한 조치를 하는 등, 그것을 처방하는 의사의 행동에 변화가 생긴다는 점 때문에 양성 대조군을 평가 수단으로 사용할 수 없게 만든다. (Noren et al. 2014)
그래서 오딧세이에서는 합성 양성 대조군을 이용하는데, (Schuemie, Hripcsak, et al. 2018) 음성 대조군을 수정하여 위험 노출 기간 동안 결과가 발생한 것처럼 모의 결과를 주입하여 만든다. 예를 들어, ACEi에 노출되는 동안, 음성 대조군의 결과 “내성 손톱”이 n번 발견되었다고 가정한다. 노출 중에 n 개의 모의 발생을 추가하면 위험이 두 배가 된다. 이것이 음성 대조군이었기 때문에, 반 사실적으로 비교했을 때의 상대 위험은 1이지만, 모의 결과를 주입한 후에는 2가 된다.
중요한 문제 중 하나는 교란을 유지하는 것이다. 음성 대조군은 강력한 교란을 가질 수 있는데, 추가 결과를 무작위로 주입하게 된다면 이러한 새로운 결과는 교란을 가지고 있지 않으므로, 우리가 양성 대조군에서 교란을 대하는 능력에 긍정적 평가를 할 수 있게 된다. 교란을 보존하기 위해, 환자 특성에 기인한 기저 공변량이 기존의 결과 outcome에 보이는 것과 마찬가지의 유사한 연관성이 새로운 결과에도 나타나기를 원한다. 이를 달성하기 위해 각 결과에 대해 위험 노출 전에 발생한 기저 공변량을 사용하여 노출 중 결과에 대한 생존율을 예측하는 모델을 학습시킨다. 공변량은 인구 통계학적 뿐만 아니라, 기록된 모든 진단, 약물 노출, 측정 및 의료 처치가 포함된다. 정규화된 하이퍼-파라미터를 선택하기 위해 10회 교차 검증된 L1-regularized Poisson regression (Suchard et al. 2013) 예측 모형을 적합시킨다. 그런 다음, 예측된 비율을 시뮬레이션한 결과에 적용하여, 실제 효과 크기를 원하는 규모로 늘린다. 결과적으로 양성 대조군은 실제 결과와 모의한 결과 모두를 포함한다.
그림 18.2가 과정을 보여준다. 이 절차는 몇 가지 중요한 비뚤림의 요인을 모의하지만, 모든 것을 다 포착하진 않는다. 예를 들어, 일부 측정 오류는 포함되지 않는다. 합성 양성 대조군은 일정한 양성 예측도와 민감도를 암시하지만, 실제로는 그렇지 않을 수 있다.
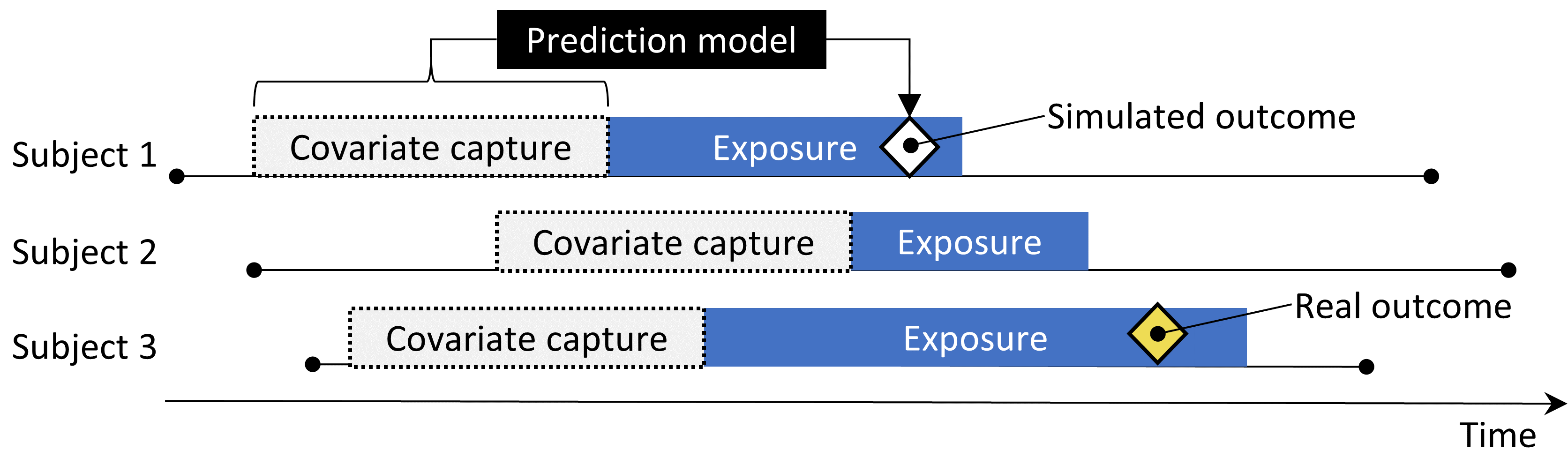
Figure 18.2: 음성 대조군을 이용해서 양성 대조군 합성하기.
각각의 대조군에 대해 하나의 실제 “효과 크기”를 언급하지만, 상이한 방법은 상이한 치료 효과 통계량을 추정한다. 인과 관계가 존재하지 않는다고 판단되는 음성 대조군의 경우, 상대 위험 relative risk, 위험 비 hazard ratio, 교차비 odds ratio, 발생률 비 incidence rate ratio, 조건부 conditional, 한계 marginal뿐만 아니라 average treatment effect in the treated(ATT)와 overall average treatment effect(ATE)까지도 포함한 모든 통계량은 1로 동일하다. 양성 대조군을 생성하는 과정은 한계 효과가 달성되는 지점까지 이 비율이 일정하게 유지되는 환자에 대해 조건부 모형을 사용하여 시간에 따라, 그리고 환자 간에 일정한 발생률 비율로 결과를 합성한다. 따라서 실제 효과 크기는 치료에서 한계 발생률 비율로 유지된다. 합성 중에 사용된 결과 모델이 정확하다는 가정하에 조건부 효과 크기와 ATE도 동일하다. 모든 결과가 드물기 때문에 교차비 odds ratios는 상대 위험 relative risk과 거의 동일하다.
18.2.3 경험적 평가
사용하고자 하는 방법론에 대하여 음성 및 양성 대조군의 추정치를 기반으로 다음과 같은 다양한 측정 기준을 계산하여 작동 특성을 이해할 수 있다:
- Area Under the receiver operator Curve(AUC): 양성 대조군과 음성 대조군 구별력.
- Coverage: 실제 효과 크기가 95% 신뢰 구간 내에 포함된 정도.
- Mean precision: 정밀도는 \(1 / (standard \ error) ^ 2\)로 계산되며 정밀도가 높을수록 신뢰구간이 좁아진다. 기하 평균을 사용하여 정밀도의 치우친 분포를 설명한다.
- Mean squared error(MSE): 효과 크기의 점추정치 로그와 실제 효과 크기 로그 사이의 평균 제곱 오차.
- Type 1 error: 음성 대조군의 경우, 귀무가설이 기각된 정도 (at \(\alpha = 0.05\)). 이는 위 양성도 및 \(1 - specificity\)에 해당한다.
- Type 2 error: 양성 대조군의 경우, 귀무가설이 기각되지 않는 정도 (at \(\alpha = 0.05\)). 이는 위 음성도 및 \(1 - sensitivity\)에 해당한다.
- Non-estimable: 대조군 방법에서 추정치를 산출할 수 없었던 대조군은 몇 개인가? 추정할 수 없는 이유는 여러 가지가 있을 수 있는데, 예를 들어 성향 점수 매칭 후 남은 환자나 결과를 가진 환자가 없는 경우이다.
활용 사례에 따라 이러한 작동 특성이 우리의 목표에 적합한지 평가할 수 있다. 예를 들어, 징후 탐지를 수행하고자 하는 경우, type 1과 type 2 오류를 고려하거나 \(\alpha\)의 임계 값을 수정하려는 경우 AUC를 대신 검사할 수 있다.
18.2.4 P-Value 보정
때로는 type 1 error (at \(\alpha = 0.05\)) 가 5%보다 크다. 다시 말해서, 실제로 귀무가설이 참임에도 불구하고 귀무가설을 기각할 가능성이 5% 이상인 경우가 많다. 그 이유는 p-value는 임의 오차만 반영하기 때문이다. 즉, 제한된 표본 크기로 인한 오차가 발생한다. 예를 들어, 교란으로 인해 발생한 체계적인 오차의 경우 반영되지 않는다. OHDSI는 p-value를 보정하여 type 1 error를 명목값 (nominal)으로 복원하는 과정을 개발하였다. (Schuemie et al. 2014) 우리는 음성 대조군에 대한 실제 효과 추정치로부터 경험적 귀무분포를 유도한다. 음성 대조군의 추정치는 귀무가설이 참일 때 기대할 수 있는 것에 대한 지표를 제공하며 경험적 귀무 분포를 추정하는 데 사용한다.
공식적으로, 우리는 각 추정치의 표집 오차를 고려하여 추정치에 가우스 확률 분포를 적합시킨다. \(\hat{\theta}_i\) 는 \(i\)번째 음성 대조군 약물-결과 쌍으로 추정된 로그 효과 추정치 (상대 위험, 오즈 혹은 발생률 비)를 나타내고, \(\hat{\tau}_i\) 는 이에 해당하는 추정된 표준 오차 \(i=1,\ldots,n\) 를 나타낸다. \(\theta_i\) 는 실제 로그 효과 크기를 나타내고 (음성 대조군의 경우 0으로 가정), \(\beta_i\)가 실제 (하지만 알 수 없는) 짝지어진 \(i\) 와 연관된 비뚤림을 나타낸다. 즉, 실제 효과 크기의 로그와 연구에서 \(i\) 로 반환될 것으로 추정하는 값의 차이는 무한으로 커진다. 일반적인 p-value 계산처럼, 우리는 \(\hat{\theta}_i\) 가 평균이 \(\theta_i + \beta_i\) 이고, 표준편차가 \(\hat{\tau}_i^2\) 인 정규 분포를 따른다고 가정한다. 전통적인 p-value 계산에서, \(\beta_i\) 는 항상 0과 같다고 가정하지만, \(\beta_i\) 는 평균이 \(\mu\) 이고 분산이 \(\sigma^2\) 인 정규분포에서 구해진다. 이는 귀무 (비뚤림) 분포를 나타낸다. 우리는 최대 우도를 통해 \(\mu\) 와 \(\sigma^2\) 를 추정한다. 요약해서 우리는 다음과 같이 가정한다:
\[\beta_i \sim N(\mu,\sigma^2) \text{ and } \hat{\theta}_i \sim N(\theta_i + \beta_i, \tau_i^2)\]
\(N(a,b)\)는 평균 \(a\)와 분산 \(b\)를 갖는 가우시안 분포를 나타내고, 다음과 같이 우도를 최대화하여 \(\mu\)와 \(\sigma^2\)을 추정하여:
\[L(\mu, \sigma | \theta, \tau) \propto \prod_{i=1}^{n}\int p(\hat{\theta}_i|\beta_i, \theta_i, \hat{\tau}_i)p(\beta_i|\mu, \sigma) \text{d}\beta_i\]
최대우도 추정량 \(\hat{\mu}\) 과 \(\hat{\sigma}\)를 얻는다. 우리는 경험적 귀무 분포를 이용하여 보정된 p-value를 계산한다. 여기서, \(\hat{\theta}_{n+1}\)은 새로운 약물-결과 쌍으로부터 추정된 효과의 로그를 나타내고, \(\hat{\tau}_{n+1}\)는 이에 상응하는 표준 오차이다. 앞서 언급한 가정으로부터, 동일한 귀무 분포로부터 \(\beta_{n+1}\)를 얻는다고 가정할 경우 다음과 같다:
\[\hat{\theta}_{n+1} \sim N(\hat{\mu}, \hat{\sigma} + \hat{\tau}_{n+1})\]
\(\hat{\theta}_{n+1}\)이 \(\hat{\mu}\) 보다 작은 경우, 새로운 쌍에 대해 보정된 단측 p-value는:
\[\phi\left(\frac{\theta_{n+1} - \hat{\mu}}{\sqrt{\hat{\sigma}^2 + \hat{\tau}_{n+1}^2}}\right)\]
여기서 \(\phi(\cdot)\) 은 표준 정규 분포의 누적 분포 함수를 나타낸다. \(\hat{\theta}_{n+1}\)이 \(\hat{\mu}\)보다 클 때, 보정된 단측 p-value는:
\[1-\phi\left(\frac{\theta_{n+1} - \hat{\mu}}{\sqrt{\hat{\sigma}^2 + \hat{\tau}_{n+1}^2}}\right)\]
18.2.5 신뢰 구간 보정
마찬가지로, 우리는 일반적으로 95% 신뢰 구간의 적용 범위가 95% 미만임을 관찰한다: 95% 이내의 시간 동안 실제 효과 크기가 95% 신뢰구간 내에 존재. 신뢰 구간의 보정 (Schuemie, Hripcsak, et al. 2018) 을 위해 우리는 양성 대조군을 사용하여 p-value 보정을 위한 프레임 워크를 확장한다. 일반적으로 보정된 신뢰 구간은 명목 신뢰 구간보다 넓지만, 표준적인 절차에서는 설명되지 않던 문제 (측정되지 않은 교란, 선택비뚤림, 그리고 측정 오차와 같은)가 반영된다.
공식적으로, 우리는 쌍 \(i\) 와 관련된 비뚤림인 \(beta_i\) 가 다시 가우시안 분포에서 나온다고 가정하지만, 이번에는 실제 효과 크기인 \(theta_i\) 와 선형으로 관련된 평균 및 표준편차를 사용한다:
\[\beta_i \sim N(\mu(\theta_i) , \sigma^2(\theta_i))\]
일때,
\[\mu(\theta_i) = a + b \times \theta_i \text{ and } \\ \sigma(\theta_i) ^2= c + d \times \mid \theta_i \mid\]
우리는 관찰되지 않은 \(\beta_i\) 를 통합하는 주변 우도를 최대화하여 \(a\), \(b\), \(c\), \(d\) 를 추정한다:
\[l(a,b,c,d | \theta, \hat{\theta}, \hat{\tau} ) \propto \prod_{i=1}^{n}\int p(\hat{\theta}_i|\beta_i, \theta_i, \hat{\tau}_i)p(\beta_i|a,b,c,d,\theta_i) \text{d}\beta_i ,\]
최대우도 추정량인 \((\hat{a}, \hat{b}, \hat{c}, \hat{d})\) 를 얻는다.
우리는 체계적 오차 모형을 사용하는 보정된 신뢰구간을 계산한다. 여기서 \(\hat{\theta}_{n+1}\)는 다시 추정 효과의 로그를 다시 표시하고, \(\hat{\tau}_{n+1}\)는 해당하는 추정의 표준 오차를 나타낸다. 위 가정에서 \(\beta_{n+1}\)이 동일한 체계 오차 모형에서 발생한다고 가정하면 다음과 같다:
\[\hat{\theta}_{n+1} \sim N( \theta_{n+1} + \hat{a} + \hat{b} \times \theta_{n+1}, \hat{c} + \hat{d} \times \mid \theta_{n+1} \mid) + \hat{\tau}_{n+1}^2) .\]
\(\theta_{n+1}\) 에 대한 방정식의 해로 보정된 95% 신뢰구간의 하한을 찾는다:
\[\Phi\left( \frac{\theta_{n+1} + \hat{a} + \hat{b} \times \theta_{n+1}-\hat{\theta}_{n+1}} {\sqrt{(\hat{c} + \hat{d} \times \mid \theta_{n+1} \mid) + \hat{\tau}_{n+1}^2}} \right) = 0.025 ,\]
여기서 \(\Phi(\cdot)\)는 표준 정규 분포의 누적 분포 함수를 나타낸다. 상한도 유사하게 확률 0.975에서 찾는다. 확률 0.5를 이용하여 보정된 점 추정치를 정의한다.
EmpiricalCalibration 패키지에서 p-값 보정과 신뢰 구간 보정이 모두 구현된다.
18.2.6 기간 관 분석 반복 Replication Across Sites
방법 검증의 또 다른 형태는 다른 인구와 다른 의료 시스템 혹은 데이터 수집 과정이 다른 데이터베이스에서 연구를 반복 실행하는 것이다. 기존 연구에서 서로 다른 데이터베이스에서 동일한 연구 설계를 실행하면 효과 크기 추정치가 크게 다른 것으로 나타났으며, (Madigan et al. 2013) 이는 모집단마다 효과 크기가 다르거나 설계가 다른 데이터베이스에서 발견된 다양한 비뚤림을 적절하게 해결하지 못하고 있음을 시사한다. 실제로, 우리는 신뢰구간의 경험적 보정을 통한 데이터베이스의 잔차 비뚤림을 고려하면 연구 간의 이질성이 크게 줄어듦을 보고 있다. (Schuemie, Hripcsak, et al. 2018)
데이터베이스간의 이질성을 표현하는 하나의 방법은 \(I^2\) 점수이며, 우연히 발생한 것이 아닌 이질성으로 인해 전체 연구에서 전체 분산의 백분율을 나타낸다. (Higgins et al. 2003) \(I^2\) 값에 대해 단순한 분류는 모든 상황에서 적합하지 않긴 하지만, 25%, 50%, 그리고 75%에서 \(I^2\) 점수에 대해 낮음, 중간, 높음의 표현을 임시로 할당할 수 있다. 대규모 성향 점수 보정을 사용한 새로운 사용자 코호트 new-user cohort 설계를 사용하여 많은 우울증 치료 효과를 추정하는 연구에서, (Schuemie, Ryan, et al. 2018) 추정치의 58%만이 \(I^2\) 의 25% 미만인 것으로 관찰되었다. 이는 경험적 보정 후에 83%로 증가했다.
18.2.7 민감도 분석
연구를 설계할 때, 때때로 설계 선택이 불확실하다. 예를 들어, 층화 성향 점수 짝짓기를 사용해야 하는지? 층화를 한다면, 어느 정도 층화를 해야 하는가? 적절한 위험 노출 기간은 무엇인가? 이러한 불확실성에 직면할 때, 하나의 해결법은 다양한 옵션을 평가하고, 선택한 디자인에 대한 결과의 민감도를 관찰하는 것이다. 다양한 옵션에서 추정치가 일관되고 유지되면 불확실성에 대해 연구가 굳건하다고 말할 수 있다.
민감도 분석에 대한 이러한 정의는 “연구의 결론이 다양한 규모의 숨겨진 비뚤림에 의해 어떻게 변경될 수 있는지 평가하는 것”이라고 민감도 분석을 정의한 Rosenbaum (2005) 과 같은 다른 연구자가 사용하는 정의와 혼동되어서는 안 된다.
18.3 실무에서의 연구 방법론 검증
여기서, 우리는 thiazides and thiazide-like diuretics(THZ)보다 ACE 억제제(ACEi)와 비교하여 혈관 부종 및 급성 심근 경색의 위험에 대한 ACEi의 효과를 조사하는 12장의 예를 바탕으로 한다. 이 장에서는 우리가 이미 사용했던 설계, 즉 CohortMethod에 관한 많은 진단을 살펴보았다. 여기에는 다른 디자인을 사용한 경우에도 적용할 수 있는 추가 진단법이 적용된다. 12.7절에 설명한 대로, ATLAS를 사용하여 연구를 구현하는 경우 ATLAS에서 생성한 연구의 R 패키지에 포함된 Shiny 앱에서 이러한 진단을 사용할 수 있다. 연구를 12.8절에 설명한 것처럼 R을 이용하여 구현한다면, 다음 절에서 설명한 대로 다양한 패키지에서 사용할 수 있는 R 함수를 사용해야 한다.
18.3.1 음성 대조군 선택하기
연구자는 인과 관계에 영향이 없는 것으로 생각되는 음성 대조군, 노출-결과 쌍을 선택해야 한다. 예제 연구와 같은 비교 효과 추정을 위해, 목적이나 비교 노출로 인해 야기되지 않는다고 여겨지는 음성 대조군을 선택한다. 대조군에서 다양하게 혼합된 비뚤림을 확보하고 경험적 보정을 가능하도록 표현된 충분한 음성 대조군을 원한다. 실용적으로 50-100개의 음성 대조군을 목표로 한다. 이러한 대조군을 완전히 직접 만들어 쓸 수도 있지만, 다행히 ATLAS는 문헌, 제품 라벨 및 자발적 보고서의 데이터를 사용하여 음성 대조군을 선택할 수 있는 기능을 제공한다.
음성 대조군 후보 목록을 생성하려면, 먼저 관심 있는 모든 노출을 포함하는 개념 모음을 생성해야 한다. 이 경우 그림 18.3과 같이 ACEi 및 THZ 클래스의 모든 성분을 선택한다.
Figure 18.3: 대상군 및 비교군의 노출을 정의하는 개념을 포함하는 개념 모음.
다음으로, ‘Explore Evidence” 탭으로 가서  버튼을 클릭한다. 근거 개요를 작성하는 데는 몇 분이 걸리고, 그 후
버튼을 클릭한다. 근거 개요를 작성하는 데는 몇 분이 걸리고, 그 후  버튼을 클릭할 수 있다. 그러면 그림 18.4에 표시된 결과와 같은 목록이 열린다.
버튼을 클릭할 수 있다. 그러면 그림 18.4에 표시된 결과와 같은 목록이 열린다.
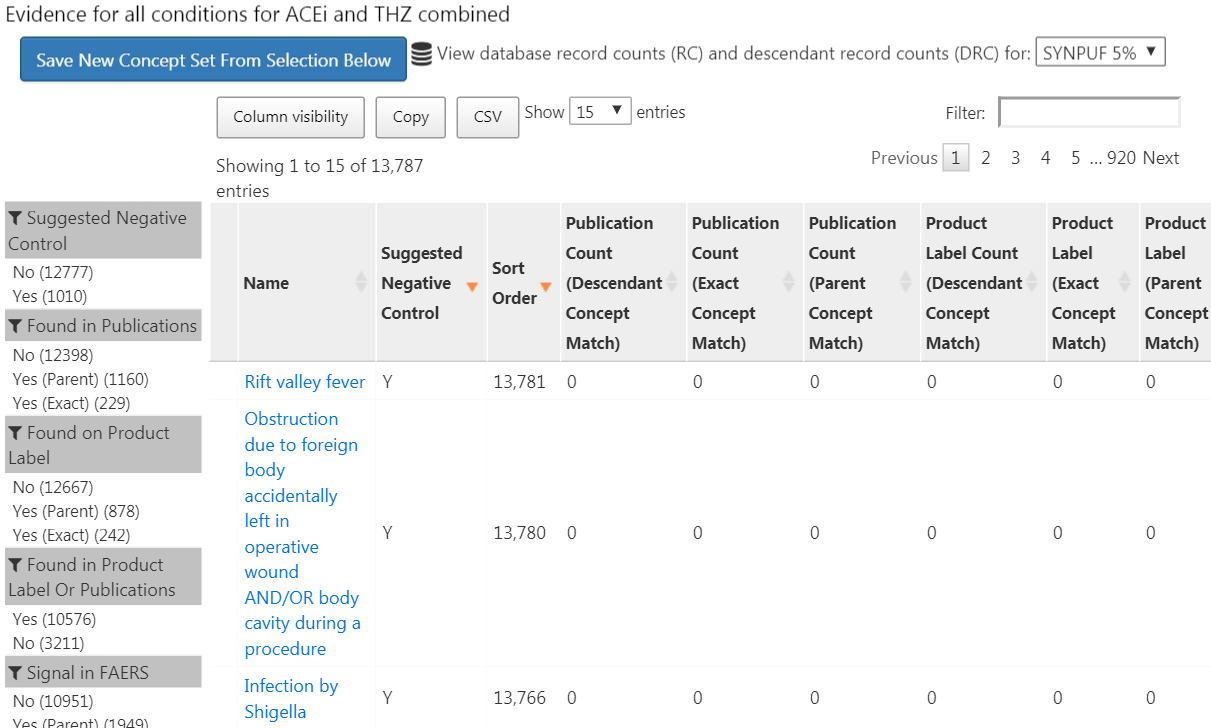
Figure 18.4: 문헌, 제품 라벨, 자발적 보고서의 개요에서 발견된 증거를 가진 후보 대조군 결과.
이 목록은 진단 개념과 우리가 정의한 노출 중 하나를 연결하는 근거의 개요를 보여준다. 예를 들어, 다양한 전략을 사용하여 PubMed에서 찾은 결과와 노출을 연결하는 출판물 수, 우리의 관심거리가 되는 노출의 제품 라벨에서 발생 가능한 부작용 진단 리스트의 수, 그리고 자발적인 보고서 수를 볼 수 있다. 기본적으로 이 목록은 음성 대조군의 후보를 먼저 표시하도록 정렬된다. 그런 다음 관측형 데이터베이스에서 수집된 진단의 유병률을 나타내는 “Sort Order”로 정렬된다. Sort Order가 높을수록 유병률이 높다. 이 데이터베이스의 유병률은 우리가 연구를 수행하려는 데이터베이스의 유병률과 일치하지 않을 수 있지만, 좋은 근사치일 수 있다.
다음 단계는 일반적으로 후보의 유병률이 가장 높은 진단부터 시작하여, 충분히 납득할 수 있을 때까지 대조군의 목록을 직접 검토하는 것이다. 이 작업을 수행하는 일반적인 방법 중 하나는 목록을 CSV (쉼표로 구분된 값) 파일로 내보내어 임상의가 18.2.1절에서 언급된 기준을 고려하여 이를 검토하는 것이다.
예제 연구에서는 부록 C.1에 나열된 76개의 음성 대조군을 선택한다.
18.3.2 대조군 포함하기
음성 대조군의 집합을 정의했다면, 그것을 연구에 포함해야 한다. 우리는 먼저 음성 대조군의 개념을 결과 코호트로 바꾸기 위한 몇 가지 논리를 정의해야 한다. 12.7.3절은 ATLAS가 사용자가 선택해야 하는 몇 가지 선택을 기반으로 이러한 코호트를 생성하는 방법을 설명한다. 우리는 종종 음성 대조군의 혹은 그 자손의 발생에 기초하여 코호트를 만들기로 선택한다. 본 연구가 R에서 구현된다면, Structured Query Language(SQL)를 사용하여 음성 대조군 코호트를 구성할 수 있다. 9장에서는 SQL과 R을 사용하여 코호트를 만드는 방법을 설명한다. 독자가 적절한 SQL과 R을 작성하는 연습을 남겨둔다.
OHDSI 도구는 음성 대조군에서 파생된 양성 대조군을 자동으로 생성하고 포함하는 기능 역시 제공한다. 이 기능은 12.7.3절에서 설명된 ATLAS Evaluation Settings에서 찾을 수 있으며, MethodEvaluation 패키지의 syntheticPositiveControls함수에서 구현된다. 여기서 생존 모델을 사용하여 실제 효과 크기가 1.5, 2, 그리고 4인 각 음성 대조군에 대해 세 가지 양성 대조군을 생성한다:
library(MethodEvaluation)
# Create a data frame with all negative control exposure-
# outcome pairs, using only the target exposure (ACEi = 1).
eoPairs <- data.frame(exposureId = 1,
outcomeId = ncs)
pcs <- synthesizePositiveControls(
connectionDetails = connectionDetails,
cdmDatabaseSchema = cdmDbSchema,
exposureDatabaseSchema = cohortDbSchema,
exposureTable = cohortTable,
outcomeDatabaseSchema = cohortDbSchema,
outcomeTable = cohortTable,
outputDatabaseSchema = cohortDbSchema,
outputTable = cohortTable,
createOutputTable = FALSE,
modelType = "survival",
firstExposureOnly = TRUE,
firstOutcomeOnly = TRUE,
removePeopleWithPriorOutcomes = TRUE,
washoutPeriod = 365,
riskWindowStart = 1,
riskWindowEnd = 0,
endAnchor = "cohort end",
exposureOutcomePairs = eoPairs,
effectSizes = c(1.5, 2, 4),
cdmVersion = cdmVersion,
workFolder = file.path(outputFolder, "pcSynthesis"))우리의 추정 연구 설계에 사용된 위험 노출 기간 time-at-risk(TAR)을 모방해야 한다. synthesizePositiveControls함수는 노출과 음성 대조군 결과에 대한 정보를 추출하고, 쌍마다 모델링 결과를 적합하고, 결과를 합성한다. 양성 대조군의 결과 코호트는 cohortDbSchema와 cohortTable로 지정된 코호트 테이블에 추가된다. 결과인 pcs data frame은 합성된 양성 대조군에 대한 정보가 포함된다.
다음으로, 우리는 음성 및 양성 대조군에 대한 영향을 추정하기 위해 관심 효과를 추정하는 데 사용된 동일한 연구를 실행해야 한다. ATLAS의 비교 대화상자에서 양성 대조군 세트를 설정하면, ATLAS가 이러한 대조군에 대한 추정치를 계산하도록 한다. 마찬가지로 Evaluation Settings에서 양성 대조군을 생성하도록 지정하면, 분석에 이러한 대조군이 포함된다. R에서, 음성 및 양성 대조군은 서로 다른 결과로 취급되어야 한다. OHDSI Methods Library의 모든 추정 패키지는 효율적인 방식으로 많은 효과를 쉽게 추정할 수 있다.
18.3.3 경험적 성능
그림 18.5는 예제 효과 연구에 포함된 음성 및 양성 대조군에 대한 추정 효과 크기를 실제 효과 크기로 계층화 한 것이다. 이 도표는 ATLAS에서 생성한 R 패키지와 함께 제공되는 Shiny 앱에 포함되어 있으며, MethodEvaluation 패키지의 plotControls 함수를 사용하여 생성할 수 있다. 추정치를 생성하거나 양성 대조군을 합성하기에 충분한 데이터가 없기 때문에 대조군의 수는 때때로 정의된 것보다 적을 수 있다.
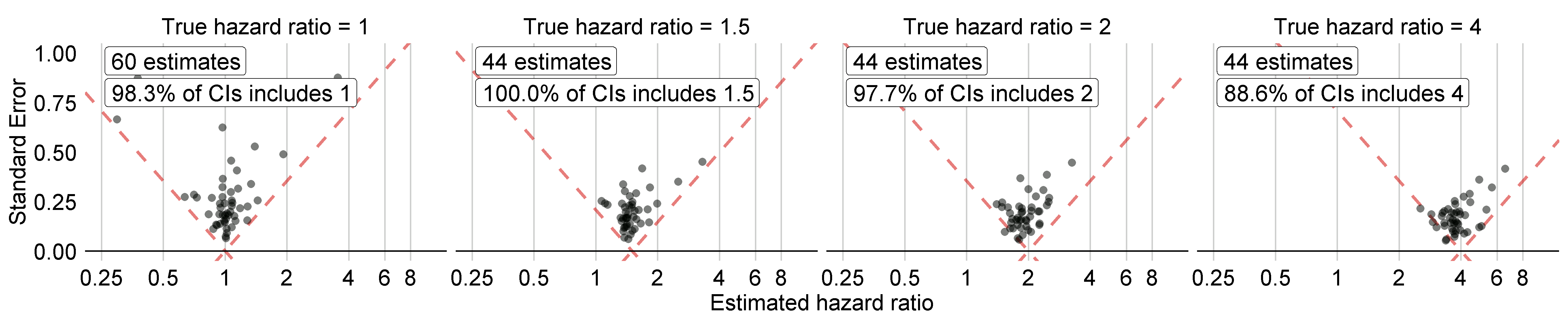
Figure 18.5: 음성 (실제 위험 비율 = 1) 및 양성 대조 (실제 위험 비율 > 1) 의 추정치. 각각의 점은 대조군을 뜻한다. 점선 아래의 추정치는 실제 효과 크기를 포함하지 않는 신뢰 구간을 가진다..
이러한 추정치를 기반으로 MethodEvaluation 패키지의 computeMetrics 함수를 사용하여 표 18.1에 표시된 측정 기준을 계산할 수 있다.
| Metric | Value |
|---|---|
| AUC | 0.96 |
| Coverage | 0.97 |
| Mean Precision | 19.33 |
| MSE | 2.08 |
| Type 1 error | 0.00 |
| Type 2 error | 0.18 |
| Non-estimable | 0.08 |
적용 범위와 type 1 error는 각각 명목 값인 95%와 5%에 매우 가깝고, AUC는 매우 높다. 항상 그런 것은 아니다.
그림 18.5에서 실제 위험 비율이 1일 때 모든 신뢰 구간에 1이 포함되는 것은 아니지만 표 18.1의 type 1 error는 0%이다. Cyclops 패키지의 신뢰 구간은 우도 profiling을 사용하여 추정되므로 기존 방법보다 정확하지만, 비대칭적인 신뢰 구간이 발생할 수 있기 때문에 예외적인 상황이다. 대신 p-value는 대칭 신뢰 구간을 가정하여 계산되며 이는 type 1 error를 계산하는 데 사용된 것이다.
18.3.4 P-Value 보정
p-value를 보정하기 위해 음성 대조군에 대한 추정값을 사용할 수 있다. 이는 Shniy 앱에서 자동으로 수행되며, R에서 수동으로도 수행할 수 있다. 12.8.6절에 설명된 대로 요약된 객체 summ을 생성했다고 가정하면 경험적 보정 효과 도표를 그릴 수 있다:
# Estimates for negative controls (ncs) and outcomes of interest (ois):
ncEstimates <- summ[summ$outcomeId %in% ncs, ]
oiEstimates <- summ[summ$outcomeId %in% ois, ]
library(EmpiricalCalibration)
plotCalibrationEffect(logRrNegatives = ncEstimates$logRr,
seLogRrNegatives = ncEstimates$seLogRr,
logRrPositives = oiEstimates$logRr,
seLogRrPositives = oiEstimates$seLogRr,
showCis = TRUE)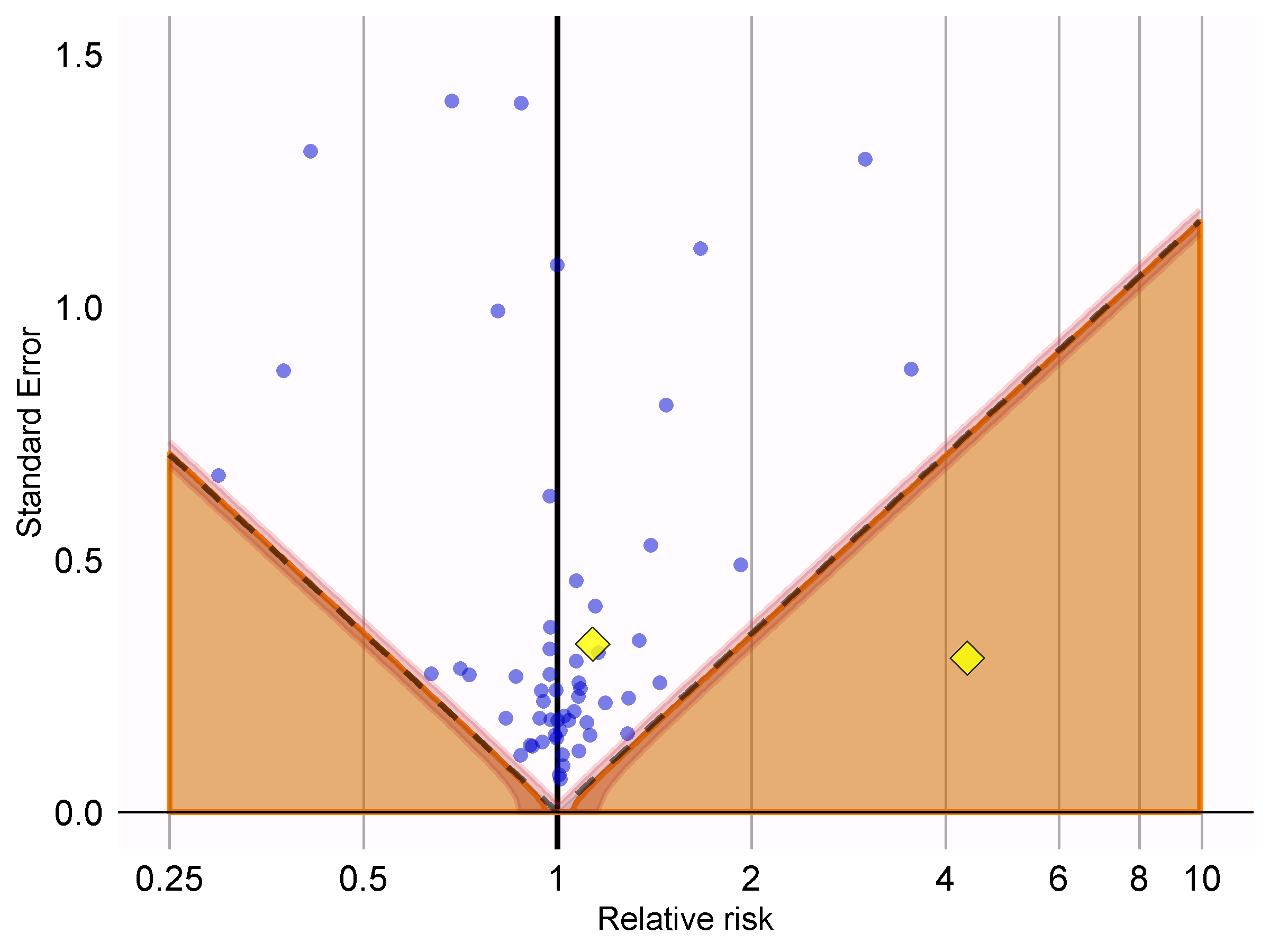
Figure 18.6: P-value 눈금: 점선 아래의 추정치는 conventional p < 0.05를 의미한다. 음영 처리된 영역의 추정치는 calibrated p < 0.05를 의미한다. 음영 처리된 영역의 가장자리 둘레에 있는 좁은 밴드는 95% credible interval을 의미한다. 점들은 음성 대조를 가리킨다. 다이아몬드 모양은 관심을 둔 연구 결과를 의미한다.
그림 18.6에서 우리는 음영 영역이 점선으로 표시된 영역과 거의 정확하게 겹치는 것을 볼 수 있는데, 이는 음성 대조군에 대해 어떠한 비뚤림도 관찰되지 않았음을 나타낸다. 관심 있는 결과 중 하나 (급성 심근경색)는 점선과 음영 위에 있으며, 보정되거나 되지 않은 두 p-value에 따라 귀무가설을 기각할 수 없음을 나타낸다. 다른 결과 (혈관 부종)는 음성 대조군에서 분명히 두드러지며 보정되거나 되지 않은 두 p-value 모두 0.05보다 작은 영역에 잘 포함된다.
보정된 p-value를 계산할 수 있다:
null <- fitNull(logRr = ncEstimates$logRr,
seLogRr = ncEstimates$seLogRr)
calibrateP(null,
logRr= oiEstimates$logRr,
seLogRr = oiEstimates$seLogRr)## [1] 1.604351e-06 7.159506e-01그리고 이것을 보정되지 않은 p-value와 비교하면:
oiEstimates$p## [1] [1] 1.483652e-06 7.052822e-01예상한 대로, 비뚤림이 거의 없거나 전혀 관찰되지 않았기 때문에 보정되지 않은 p-value는 보정된 값과 매우 유사하다.
18.3.5 신뢰 구간 보정
마찬가지로, 음성 및 양성 대조군에 대한 추정값을 사용하여 신뢰 구간을 보정할 수 있다. Shiny 앱은 보정 신뢰 구간을 자동으로 보고한다. R에서는 “Empirical calibration of confidence intervals” vignette에 자세히 설명된 대로, EmpiricalCalibration 패키지의 fitSystematicErrorModel및 calibrateConfidenceinterval함수를 사용하여 구간을 보정할 수 있다.
보정하기 전에, 혈관 부종 및 급성 심근 경색의 추정 위험 비 (95% 신뢰구간)는 4.32 (2.45-8.08) 및 1.13 (0.59-2.18)이다. 보정된 위험 비는 4.75 (2.52-9.04) 및 1.15 (0.58-2.30)이다.
18.3.6 데이터베이스 간 이질성
한 데이터베이스에서 분석을 수행한 것처럼, IBM MarketScan Medcaid (MDCD) 데이터베이스에서, 우리는 다른 공통 데이터 모델(CDM) 데이터베이스에서도 동일한 분석 코드를 실행할 수 있다. 그림 18.7은 혈관 부종의 결과에 대한 총 5개의 데이터베이스에 대한 forest 도표와 메타 분석 추정치 (임의 효과를 가정) (DerSimonian and Laird 1986)를 보여준다. 이 그림은 EvidenceSynthesis 패키지의 plotMetaAnalysisForest함수를 사용하여 생성되었다.

Figure 18.7: 혈관부종의 위험을 위해 ACE 억제제를 thiazide 및 thiazides 유사 이뇨제와 비교할 때 5개 데이터베이스의 효과 크기 추정 및 95% 신뢰 구간(CI).
모든 신뢰 구간이 1 이상이고 효과가 있다는 사실에 일치하지만 \(I^2\)는 데이터베이스 간 이질성이 있음을 표시한다. 하지만 그림 18.8과 같이 보정된 신뢰구간을 사용하여 \(I^2\)를 계산하면 이질성이 음성 및 양성 대조군을 이용하여 각 데이터베이스에서 측정한 비뚤림에 의해 설명될 수 있음을 알 수 있다. 경험적 보정은 이 비뚤림을 올바르게 고려한 것으로 보인다.

Figure 18.8: ACE 억제제를 thiazide 및 thiazide 유사 이뇨제와 비교할 때 5가지 데이터베이스에서 보정된 효과 크기 추정치 및 95% 신뢰 구간 및 혈관부종의 위험 비율에 대한 메타 분석 추정치.
18.3.7 민감도 분석
분석에서 선택된 설계 중 하나는 성향 점수에 일-대-다 비율 짝짓기 variable-ratio를 사용하는 것이었다. 그러나 우리는 성향 점수에 계층화를 사용할 수도 있다. 우리는 이 선택에 대해 불확실하기 때문에, 둘 다 사용하기로 할 수 있다. 표 18.2는 일-대-다 비율 짝짓기 및 계층화 (10개의 동일한 크기의 층화)를 사용할 때 보정 및 보정되지 않은 급성 심근 경색 및 혈관 부종의 효과 크기 추정치를 보여준다.
| Outcome | Adjustment | Uncalibrated | Calibrated |
|---|---|---|---|
| Angioedema | Matching | 4.32 (2.45 - 8.08) | 4.75 (2.52 - 9.04) |
| Angioedema | Stratification | 4.57 (3.00 - 7.19) | 4.52 (2.85 - 7.19) |
| Acute myocardial infarction | Matching | 1.13 (0.59 - 2.18) | 1.15 (0.58 - 2.30) |
| Acute myocardial infarction | Stratification | 1.43 (1.02 - 2.06) | 1.45 (1.03 - 2.06) |
짝짓기와 층화 분석으로부터 얻은 추정치가 강하게 일치하는 것과 함께, 계층화에 대한 신뢰구간이 짝짓기 된 신뢰 구간 내에 완전히 포함되는 것을 볼 수 있다. 이는 연구 설계 선택에 대한 우리의 불확실성이 추정치의 타당성에 영향을 미치지 않음을 시사한다. 계층화는 우리에게 더 큰 검정력 (더 좁은 신뢰 구간)을 제공하는 것으로 보이는데, 왜냐하면 짝짓기는 많은 데이터의 손실을 초래하지만, 계층화는 그렇지 않기 때문에 이것은 놀라운 일은 아니다. 층화분석을 사용한 대가로 비뚤림이 증가할 수 있는데, 비록 보정된 신뢰구간에 비뚤림이 증가했다는 증거는 보이지 않지만 계층 내 남아있는 교란으로 인해서 그럴 수 있다.
18.4 OHDSI 방법론 벤치마크
비록 권고안이 적용된 맥락 안에서 방법론적인 성능을 경험적으로 평가하는 것이라 하더라도, 연구에서 쓰인 데이터베이스와 관심 노출-결과 쌍과 비슷한 방식 (예를 들어 같은 노출 혹은 같은 결과를 사용하는 것)의 음성과 양성 대조군을 사용하여 방법론적인 성능을 일반적으로 평가하는 것도 가치 있다. 이것이 OHDSI Methods Evaluation이 개발된 이유이다. 성능 평가 기준은 만성 혹은 급성 결과 또는 단기 노출을 포함한 광범위한 대조군 질의를 사용하여 성능을 평가한다. 이 성능 평가 기준의 결과는 분석 방법의 전반적인 유용성을 입증하는 데 도움이 될 수 있으며 상황별로 경험적 평가를 아직 사용할 수 없는 경우 분석법의 성능에 대한 사전 확신을 형성하는데 사용될 수 있다. 사용 평가 기준은 8개의 범주로 분류할 수 있는 200개의 신중하게 선택된 음성 대조군으로 구성되며 각 범주의 대조군은 동일한 노출 또는 동일한 결과를 공유한다. 이러한 200개의 음성 대조군으로부터, 18.2.2절에 기술된 바와 같이 600개의 합성 양성 대조군이 유도된다. 분석 방법을 평가하려면 모든 대조군에 대해 효과 크기 추정치를 생성하는데 사용해야 하며, 그 후 18.2.3절에 설명된 측정기준을 계산할 수 있다. 성능 평가 기준은 공개적으로 사용이 가능하며 MethodEvaluation 패키지의 Running the OHDSI Methods Benchmark vignette 비네팅 실행에 설명된 대로 배포할 수 있다.
각 분석 방법별로 다양한 옵션을 적용하여 OHDSI 연구방법론 라이브러리의 모든 분석법에 대해 벤치마크를 실행했다. 예를 들어, CohortMethod는 성향 점수 짝짓기, 층화, 그리고 가중화를 사용하여 평가했다. 이 실험은 4개의 대규모 관찰형 의료 데이터베이스에서 실행되었다. 온라인상의 Shiny 앱59 에서 볼 수 있는 결과는 여러 방법이 높은 AUC (음성대조군에서 양성 대조군을 구분하는 능력)를 보여주지만, 그림 18.9와 같이, 대부분의 설정에서 대부분의 방법이 높은 1종 오류와 (실제로 효과 없는데 효과가 있다고 판단) 95% 신뢰 구간에 포함되는 비율이 낮은 것을 보여준다.
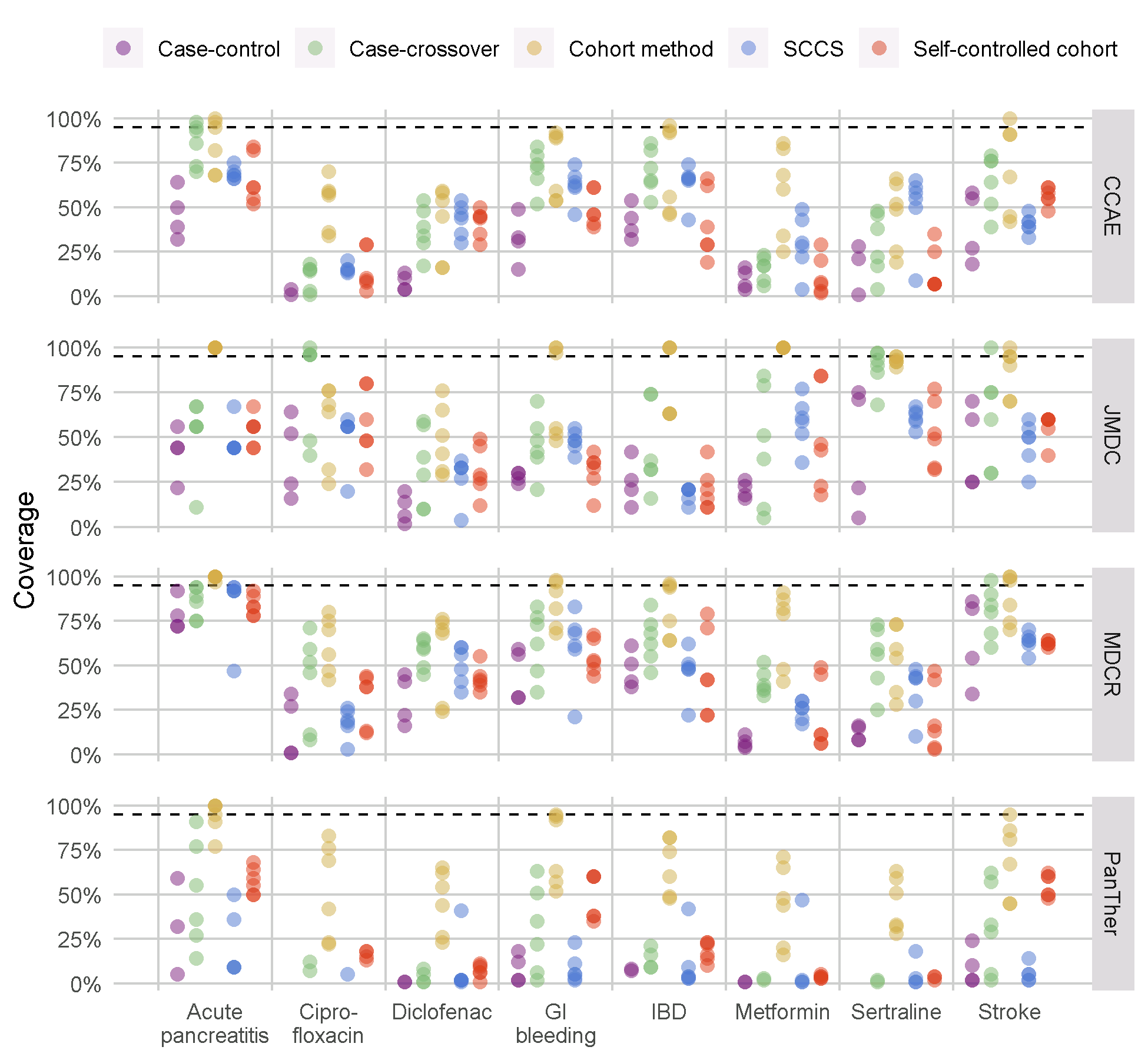
Figure 18.9: 연구방법론 라이브러리에서 방법에 대한 95% 신뢰 구간 적용 범위. 각 점은 특정 분석 선택 세트의 성능을 나타낸다. 점선은 명목 성능을 나타낸다 (95% 적용 범위). SCCS = Self-Controlled Case Series, GI = Gastrointestinal, IBD = inflammatory bowel disease.
이것은 경험적 평가와 보정의 필요성을 강조한다: 이미 출판된 거의 모든 관찰연구처럼 경험적 평가가 수행되지 않는다면, 우리는 그림 18.9의 결과와 같은 사실을 미리 알고 있어야 하며, 그 연구 결과의 실제 효과 크기가 95% 신뢰 구간에 포함되지 않을 가능성이 높다고 결론지어야 한다!
연구방법론 라이브러리의 설계에 평가까지 경험적 교정은 종종 제2종 오류 (실제로 효과가 있는데 없다고 판단)를 증가시키고 정밀도를 낮추는 대가를 지불하지만, 제1종 오류와 포함 범위를 명목 값으로 복원하는 것을 보여준다.
18.5 요약
방법의 타당성은 연구 방법의 기본 가정이 충족되는지에 따라 다르다.
가능하면 이러한 가정은 실험 진단을 사용하여 경험적으로 검사를 해야 한다.
답이 알려진 질문 대조군 가설을 사용하여 특정 연구 설계가 실제와 일치하는 답을 생성하는지 평가해야 한다.
종종 p-value와 신뢰 구간은 대조군 가설을 사용하여 측정한 명목 특성을 나타내지 않는다.
이러한 특성은 경험적 보정을 사용하여 명목값으로 복원될 수 있다.
- 연구 진단은 연구자가 관심 있는 효과에 대해 눈가림 된 채 분석을 수행해야만, 분석 설계별 옵션을 안내하고 프로토콜을 개선하는 데 사용될 수 있다.
References
Arnold, B. F., A. Ercumen, J. Benjamin-Chung, and J. M. Colford. 2016. “Brief Report: Negative Controls to Detect Selection Bias and Measurement Bias in Epidemiologic Studies.” Epidemiology 27 (5): 637–41.
DerSimonian, R., and N. Laird. 1986. “Meta-analysis in clinical trials.” Control Clin Trials 7 (3): 177–88.
Higgins, J. P., S. G. Thompson, J. J. Deeks, and D. G. Altman. 2003. “Measuring inconsistency in meta-analyses.” BMJ 327 (7414): 557–60.
Lipsitch, M., E. Tchetgen Tchetgen, and T. Cohen. 2010. “Negative controls: a tool for detecting confounding and bias in observational studies.” Epidemiology 21 (3): 383–88.
Madigan, D., P. B. Ryan, M. Schuemie, P. E. Stang, J. M. Overhage, A. G. Hartzema, M. A. Suchard, W. DuMouchel, and J. A. Berlin. 2013. “Evaluating the impact of database heterogeneity on observational study results.” Am. J. Epidemiol. 178 (4): 645–51.
Noren, G. N., O. Caster, K. Juhlin, and M. Lindquist. 2014. “Zoo or savannah? Choice of training ground for evidence-based pharmacovigilance.” Drug Saf 37 (9): 655–59.
Prasad, V., and A. B. Jena. 2013. “Prespecified falsification end points: can they validate true observational associations?” JAMA 309 (3): 241–42.
Rosenbaum, P. 2005. “Sensitivity Analysis in Observational Studies.” In Encyclopedia of Statistics in Behavioral Science. American Cancer Society. doi:10.1002/0470013192.bsa606.
Schuemie, M. 2018. “Empirical confidence interval calibration for population-level effect estimation studies in observational healthcare data.” Proc. Natl. Acad. Sci. U.S.A. 115 (11): 2571–7.
Schuemie, M. J., P. B. Ryan, W. DuMouchel, M. A. Suchard, and D. Madigan. 2014. “Interpreting observational studies: why empirical calibration is needed to correct p-values.” Stat Med 33 (2): 209–18.
Schuemie, M. J., P. B. Ryan, G. Hripcsak, D. Madigan, and M. A. Suchard. 2018. “Improving reproducibility by using high-throughput observational studies with empirical calibration.” Philos Trans A Math Phys Eng Sci 376 (2128).
Suchard, M. A., S. E. Simpson, Ivan Zorych, P. B. Ryan, and David Madigan. 2013. “Massive Parallelization of Serial Inference Algorithms for a Complex Generalized Linear Model.” ACM Trans. Model. Comput. Simul. 23 (1). New York, NY, USA: ACM: 10:1–10:17. doi:10.1145/2414416.2414791.
Voss, E. A., R. D. Boyce, P. B. Ryan, J. van der Lei, P. R. Rijnbeek, and M. J. Schuemie. 2016. “Accuracy of an Automated Knowledge Base for Identifying Drug Adverse Reactions.” J Biomed Inform, December.
Zaadstra, B. M., A. M. Chorus, S. van Buuren, H. Kalsbeek, and J. M. van Noort. 2008. “Selective association of multiple sclerosis with infectious mononucleosis.” Mult. Scler. 14 (3): 307–13.