Chapter 6 추출 변환 적재 Extract Transform Load
Chapter leads: Clair Blacketer & Erica Voss
6.1 서론
원천 데이터에서 OMOP 공통 데이터 모델 Common Data Model(CDM)을 얻기 위해서는 추출 변환 적재 Extract Transform Load(ETL) 절차가 필요하다. 이 절차는 데이터를 CDM으로 변환하는 과정이며, 표준용어로의 매핑, SQL 코드를 이용한 자동화된 절차로 이루어지게 된다. ETL 절차는 원천 데이터가 갱신될 때마다 언제든지 재수행할 수 있게끔 반복할 수 있게 구축하는 것이 중요하다.
ETL을 진행하기 위해서는 다양한 작업이 필요하다. 몇 년 동안의 경험을 통해 우리는 4가지 주요 단계로 이루어진 모범사례를 개발하였다.
- 데이터 전문가와 CDM 전문가가 함께 ETL을 설계할 것.
- 의학 지식이 있는 사람이 용어 매핑을 할 것.
- 엔지니어가 ETL을 수행할 것.
- 모든 사람이 질 관리에 참여할 것.
이 장에서 우리는 각 단계를 세부적으로 살펴볼 것이다. 각 절차를 보조하기 위해 OHDSI 커뮤니티는 다양한 도구를 개발해 왔고, 이 도구에 대해서도 다룰 것이다. 마지막으로 CDM과 ETL의 유지에 관해 이야기하며 마무리할 것이다.
6.2 1단계: ETL 설계
ETL 설계와 ETL 수행을 명확하게 분리하는 것이 중요하다. ETL을 설계하는 것은 원천 데이터와 CDM 모두에 대한 넓은 지식이 필요하다. 반대로 ETL을 수행할 때는 ETL을 기술적인 측면에서 효율적으로 수행하는 방법에 대해 엔지니어에게 의존하게 된다. 만약 동시에 두 가지 모두를 진행하려 한다면, 전체적인 그림에 집중할 때보다 세부적인 사항에서 막히게 될 가능성이 높다.
ETL 설계를 위해 두 가지 밀접하게 연관된 도구가 개발되었다: White Rabbit과 Rabbit-in-a-Hat
6.2.1 White Rabbit
ETL 절차를 시작하기 위해서는 테이블, 필드, 내용을 포함한 데이터에 대한 이해가 필요하다. 하단의 링크에 White Rabbit에 대한 정보가 기록되어 있다. White Rabbit은 보건의료 종단 longitudinal 데이터베이스에서 OMOP CDM으로의 ETL 작업 준비를 도와주기 위한 소프트웨어이다. White Rabbit은 원천 데이터를 탐색하고 ETL 설계를 시작하기 위한 필수 정보에 대한 보고서를 생성해준다. 모든 원천 코드, 설치 방법 및 설명서는 Github에서 확인할 수 있다.28
범위와 목표
White Rabbit의 주요 기능은 원천 데이터에 대한 탐색을 수행하고, 테이블, 필드, 필드 값에 대한 세부적인 정보를 제공하는 것이다. 원천 데이터는 comma-separated(CSV) 텍스트 파일일 수도 있고, 데이터베이스 (MySQL, SQL Server, Oracle, PostgreSQL, Microsoft APS, Microsoft Access, Amazon RedShift)에 적재되어 있을 수도 있다. 탐색 과정에서 Rabbit-In-a-Hat 도구와 함께 쓴다면 ETL을 설계할 때 참고할 수 있는 보고서를 생성할 수 있다. White Rabbit은 다른 표준 데이터 프로파일링 소프트웨어와는 달리 개인 식별 정보 Personally Identifiable Information(PII)가 결과 데이터 파일에서 보이는 것을 방지한다.
절차 개요
원천 데이터를 탐색하기 위해 소프트웨어를 사용하는 일반적인 순서:
- 결과를 내보낼 작업 폴더를 로컬 컴퓨터에 설정.
- 데이터베이스 혹은 CSV 텍스트 파일과의 연결 및 연결 확인.
- 탐색 대상 테이블 선택 및 탐색.
- White Rabbit의 원천 데이터에 대한 정보 생성 및 내보내기.
작업 폴더 설정
White Rabbit 애플리케이션의 다운로드 및 설치 이후, 처음으로 할 일은 작업 폴더를 설정하는 것이다. White Rabbit이 생성하는 모든 파일은 설정한 로컬 폴더에 생성될 것이다. 그림 6.1에서 보이는 “Pick Folder” 버튼을 사용하여 탐색 문서가 저장될 로컬 환경을 탐색할 수 있다.
Figure 6.1: “Pick Folder” 버튼으로 White Rabbit 애플리케이션의 작업 폴더를 설정한다
데이터베이스 연결
White Rabbit은 CSV 텍스트 파일과 다양한 데이터베이스 플랫폼을 지원한다. 마우스를 올리면 다양한 필드에 대한 필요 항목의 설명을 확인할 수 있다. 자세한 설명은 설명서에서 확인할 수 있다.
데이터베이스 테이블 탐색
데이터베이스에 연결한 이후에는 데이터베이스에 적재되어있는 테이블을 탐색할 수 있다. 탐색 과정은 ETL을 설계하는 데 도움이 되는 원천 데이터에 대한 정보를 담은 보고서를 생성할 수 있다. 그림 6.2에 보이는 Scan 탭의 “Add” (Ctrl + mouse click) 버튼을 눌러서 원천 데이터베이스의 각 테이블을 선택하거나, “Add all in DB”를 누름으로써 모든 테이블을 자동으로 선택할 수 있다.
Figure 6.2: White Rabbit Scan 탭.
탐색에 사용될 몇 가지 옵션:
- “Scan field values”는 열에 어떠한 값이 나타나는지 보고 싶을 때 사용한다.
- “Min cell count”는 필드 값을 탐색할 때 쓰이는 옵션이다. 기본값은 5로 설정되어 있으며, 이는 원천 데이터에서 5번 이하로 나타나는 값은 보고서에 나타내지 않는 것을 의미한다. 각 데이터 사용시 고유한 규칙에 따라 minimal cell count를 정해야 할 것이다.
- “Rows per table”는 필드 값을 탐색할 때 쓰이는 옵션이다. 기본값으로 White Rabbit은 테이블에서 무작위로 100,000개의 행을 선택하여 탐색할 것이다.
모든 옵션이 설정된 이후에는 “Scan tables”을 누르면 된다. 탐색이 완료된 이후에는 보고서가 작업 폴더에 생성될 것이다.
탐색 보고서의 이해
탐색이 완료된 이후에는 선택된 작업 폴더에 엑셀 파일이 생성될 것이며, 엑셀 파일에는 스캔한 각 테이블에 대한 하나의 탭과 개요 탭이 생성된다. 개요 탭은 탐색한 모든 테이블이며, 각 테이블의 필드, 각 필드의 데이터 타입, 필드의 최대 길이, 테이블의 행의 수, 탐색한 행의 수, 그리고 얼마나 많은 필드가 비어있는지 보여준다. 그림 6.3은 개요 탭의 예시를 보여준다.
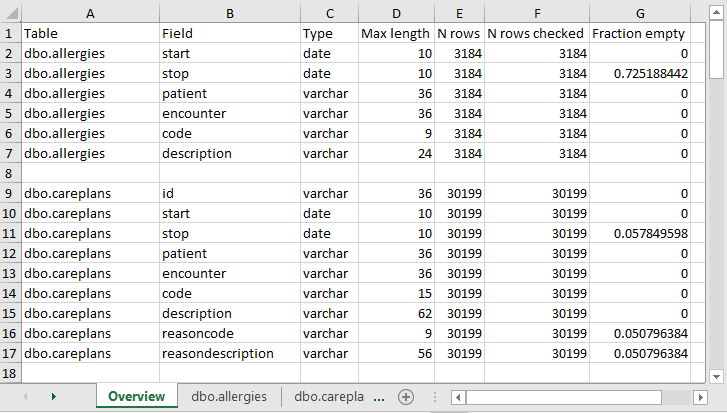
Figure 6.3: 검색 리포트의 개요 탭 예시.
각 테이블의 탭은 각각의 필드, 필드의 값, 그리고 값의 빈도를 나타낸다. 각 원천 테이블의 컬럼은 엑셀에서 두 개의 열 column으로 생성된다. 하나는 탐색 시 설정한 “Min cell count” 보다 자주 나타난 값들을 보여준다. 예를 들어, 성별 열이라면, ‘남성’, ’여성’등과 같이 열 내부에 있는 값들이 나올 것이다. 만약 고유한 값 목록 중 일부가 이러한 기준에 의해 보여지지 않는다면, 목록의 마지막 값에는 “List truncated” 가 나타날 것이다. 이는 하나 혹은 그 이상 값의 빈도가 “Min cell count” 보다 적어 사용자에게 보여지지 않음을 의미한다. 각각의 값 옆에는 빈도를 나타내는 두 번째 열이 있다 (표본에서 값이 발생하는 횟수). 이 두 열 (고유한 값과 빈도수)은 작업 workbook에 프로파일링 된 테이블의 모든 원천 변수에 대해 반복돼서 나타난다.
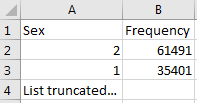
Figure 6.4: 단일 열에 대한 예제 값.
보고서는 원천 데이터에 무엇이 있는지를 강조함으로써 데이터를 이해하는 데 강력한 도움을 준다. 예를 들면, 그림 6.4에 나타난 결과가 탐색 된 테이블 열 중 하나인 “Sex”에 반환될 경우, 우리는 각각 61,491번과 35,401번 나타난 공통된 값(1과 2)이 있음을 알 수 있다. White Rabbit가 1을 남성으로, 2를 여성으로 정의하지는 않을 것이다. 데이터 소유자가 일반적으로 원천 시스템의 고유한 원천 코드에 대해 정의해야 한다. 하지만 이 두 가지 값 (1 & 2)은 데이터에 있는 유일한 값이 아니기 때문에 우리는 잘린 목록을 확인해야 한다. 이 값은 (“Min cell count” 정의에 따라) 매우 낮은 빈도로 나타나게 되고, 종종 부정확하거나 매우 의심스러운 값으로 표현된다. ETL 수행을 계획할 때 우리는 높은 빈도의 성별 개념으로써 1과 2만 다루는 것이 아니라, 열에 존재하는 낮은 빈도의 값도 고려해야 한다. 예를 들어 만약 낮은 빈도의 성별이 “NULL”일 경우 ETL 진행 시 이러한 데이터에 대해 어떻게 처리할 것인지 확실히 해야 한다.
6.2.2 Rabbit-In-a-Hat
White Rabbit과 함께 우리는 원천 데이터에 대한 분명한 그림을 그릴 수 있다. 또한, 우리는 CDM에 대한 전체 명세서를 알고 있다. 이제 우리는 하나에서 다른 하나로 넘어갈 로직을 정의해야 한다. 이 설계 활동은 원천 데이터와 CDM 모두에 대한 온전한 지식을 요구한다. White Rabbit 소프트웨어와 함께 사용되는 Rabbit-in-a-Hat 도구는 명확하게 이 분야의 전문가를 위해 개발되었다. 일반적으로 ETL 설계팀은 회의실에 같이 앉아 Rabbit-in-a-Hat을 프로젝터 화면으로 같이 보면서 작업을 한다. 첫 번째로 테이블 간의 매핑은 협력적으로 결정될 수 있으며, 그 후에는 필드 간의 매핑이 설계되는 동시에 어떠한 값을 변환시킬지 로직을 정의할 수 있다.
범위와 목표
Rabbit-In-a-Hat은 White Rabbit의 탐색 문서를 읽고 시각화하기 위해 설계되었다. White Rabbit은 원천 데이터에 대한 정보를 생성하는 반면, Rabbit-In-a-Hat은 그 정보를 사용하고 그래픽 사용자 인터페이스를 통하여 사용자가 원천 데이터의 테이블과 열을 CDM으로 연결될 수 있게 해준다. Rabbit-In-a-Hat은 ETL 절차에 대한 문서를 생성해주지만 ETL을 위한 코드는 생성하지 않는다.
절차 개요
소프트웨어를 이용한 ETL 문서 생성을 위한 일반적인 순서:
- White Rabbit이 완료한 탐색 결과.
- 탐색 결과 열기. 인터페이스가 원천 테이블과 CDM 테이블을 보여줌.
- 원천 테이블의 정보와 상응하는 CDM 테이블을 연결.
- CDM 테이블에 상응하는 각 원천 테이블에 대해서 세부적인 원천 열과 CDM 열의 연결을 정의.
- Rabbit-In-a-Hat 작업을 저장하고 MS 워드 문서로 내보내기.
ETL 로직 작성
일단 Rabbit-In-a-Hat 내의 White Rabbit 탐색 보고서를 확인한다면, 원천 데이터를 OMOP CDM으로 변환하는 설계와 로직 작성을 시작할 준비가 되었다. 하나의 예시로써 하단의 장에서 Synthea29 데이터베이스의 일부 테이블의 변환을 보여줄 것이다.
ETL의 일반적인 흐름
CDM이 사람 중심의 모형이기 때문에 제일 먼저 PERSON 테이블 매핑으로 시작하는 것이 좋다. 모든 임상 사건과 관련 있는 테이블 (CONDITION_OCCURRENCE, DRUG_EXPOSURE, PROCEDURE_OCCURRENCE 기타 등)은 PERSON 테이블의 person_id를 참조하기에 PERSON 테이블에 대한 로직을 먼저 작성하는 것이 나중을 위해 좋다. PERSON 테이블을 변환한 다음에는 OBSERVATION_PERIOD를 변환하는 것이 좋은 선택이다. CDM 데이터베이스의 개인은 최소 하나 이상의 OBSERVATION_PERIOD를 가져야 하고, 일반적으로 한 사람에 대한 모든 사건은 이 관찰 기간 내에 들어온다. PERSON과 OBSERVATION_PERIOD 테이블이 완료되면 보통 PROVIDER, CARE_SITE, 그리고 LOCATION과 같은 테이블이 다음 대상이 된다. 임상 테이블 이전에 마지막으로 로직을 작성해야 하는 테이블은 VISIT_OCCURRENCE이다. 한 사람이 환자로서의 여정에서 대부분의 사건이 방문할 때 발생하기 때문에 종종 모든 ETL 과정에서 가장 복잡하고 중요한 부분이기도 하다. 일단, 이 테이블이 완료되면 어떤 CDM 테이블을 어떤 순서대로 매핑할지는 선택하기 나름이다.
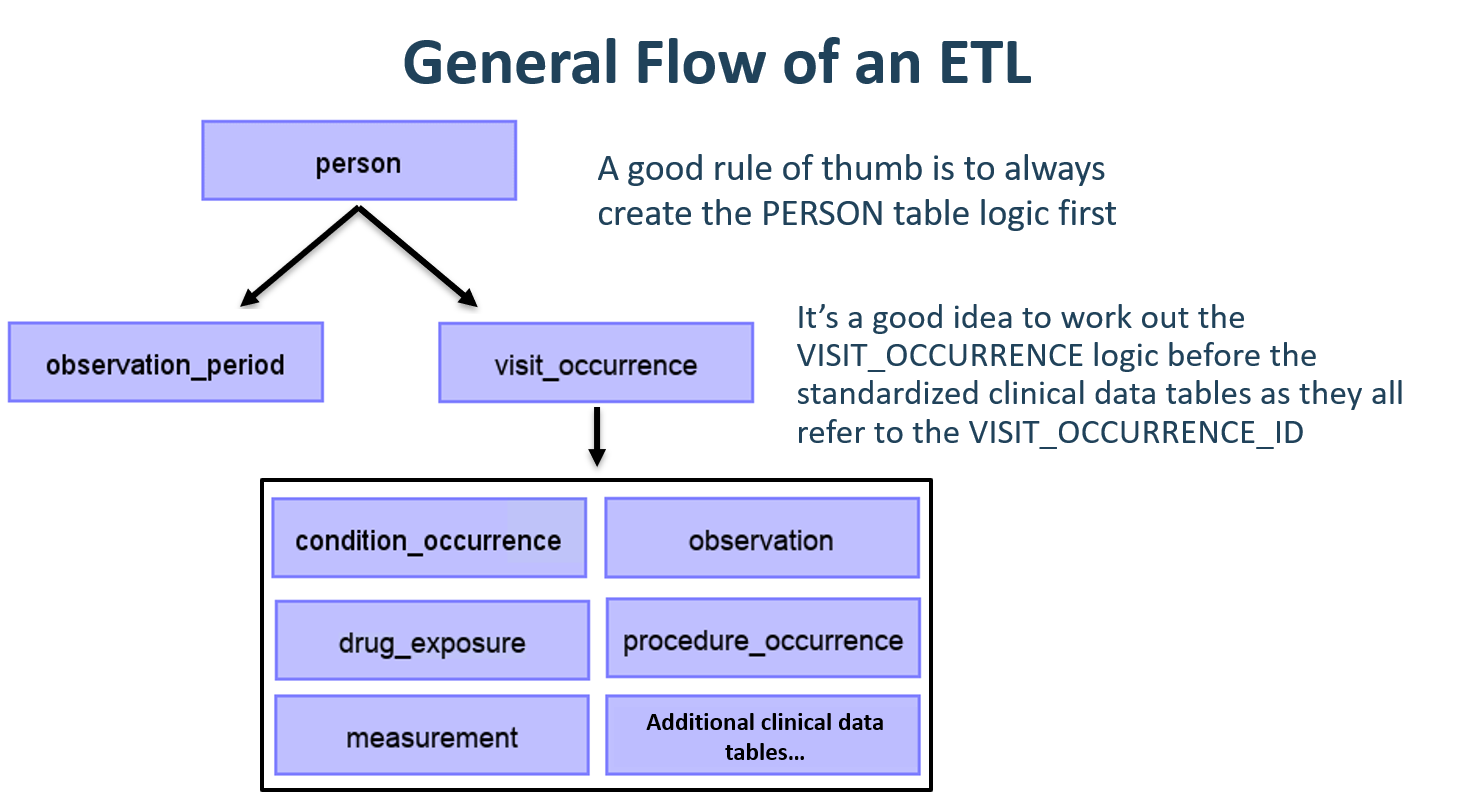
Figure 6.5: ETL의 일반적인 흐름과 먼저 매핑할 테이블.
CDM 변환 과정에서 종종 중간 테이블을 만들 필요가 있을 수 있다. 올바른 VISIT_OCCURRENCE_ID를 해당 사건에 부여하거나 아니면 원천 코드를 표준 코드로 매핑하는 경우일 수도 있다 (이 단계는 종종 매우 느리게 진행된다). 중간 테이블은 100% 허용되고 장려된다. 하지만 이러한 중간 테이블이 변환이 완료된 이후에도 남아있거나 사용하는 것은 추천하지 않는다.
매핑 예시: PERSON 테이블
Synthea 데이터 구조에서 환자 테이블은 20개의 열을 갖고 있지만 그림 6.6에서 보이는 것처럼 모든 열이 PERSON 테이블에 필요한 것은 아니다. 이런 일은 매우 흔한 일이고 문제가 되지 않는다. 이 예시에서는 환자 이름, 운전면허번호, 여권 번호 등 Synthea의 환자 테이블의 많은 데이터 포인트가 CDM PERSON 테이블에 사용되지 않는 것을 알 수 있다.
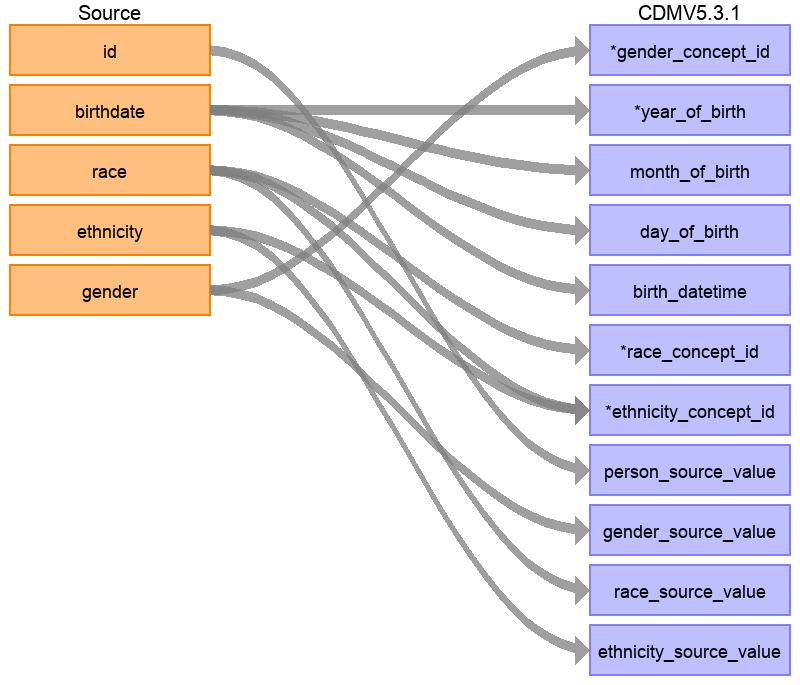
Figure 6.6: CDM PERSON 테이블에 Synta Patients 테이블 매핑.
하단의 표 6.1은 Synthea의 환자 테이블이 CDM PERSON 테이블로 변환되는 로직을 보여준다. ‘Destination Field’는 CDM 데이터의 어디에 매핑되는지를 나타낸다. ‘Source field’는 원천 테이블 (예시에서는 환자 테이블)의 어느 열에서 CDM의 열로 변하는지 나타낸다. 마지막으로, ‘Logic & comments’는 로직에 대한 설명을 의미한다.
| Destination Field | Source field | Logic & comments |
|---|---|---|
| PERSON_ID | 자동으로 생성된다. PERSON_ID는 실행과 동시에 생성될 것이다. 왜냐하면 PERSON_ID가 정수일 때 원천에서의 ID 값은 varchar이기 때문이다. 원천에서의 ID 필드는 PERSON_SOURCE_VALUE로 설정하는데 이는 그 값을 보존하고 필요 시 오류 검수를 해야 하기 위함이다. | |
| GENDER_CONCEPT_ID | gender | 성별이 ‘M’일 때, GENDER_CONCEPT_ID 를 8507로 설정하고, 성별이 ‘F’일 때, 8532로 설정한다. 성별이 확인되지 않거나 없는 경우 그 행을 삭제한다. 이 두 concept은 성별 도메인에서 오직 두 개의 표준 concept만 있는 것처럼 선택된다. 비록 분석에서 성별이 없는 사람을 제외하는 것처럼 그들을 제거하는 것을 권장할지라도, 성별이 확인되지 않는 환자를 삭제하는 기준은 기관별로 다를 수 있다. |
| YEAR_OF_BIRTH | birthdate | 생일에서 년도를 추출한다 |
| MONTH_OF_BIRTH | birthdate | 생일에서 달을 추출한다 |
| DAY_OF_BIRTH | birthdate | 생일에서 날짜를 추출한다 |
| BIRTH_DATETIME | birthdate | 자정 00:00:00을 포함한다. 여기, 원천은 생시time of birth를 제공하지 않기 때문에, 모두 자정으로 선택된다. |
| RACE_CONCEPT_ID | race | 인종이 ’WHITE’일 때 8527로 설정하고, ’BLACK’이면 8516로 설정하고, ’ASIAN’이면 8515로 설정하고, 나머지는 0으로 설정한다. 이 concept이 선택되는데 왜냐하면 원천 안의 인종 카테고리에 가장 부합하는 인종 도메인에 속하는 표준 concept이기 때문이다. |
| ETHNICITY_ CONCEPT_ID | race ethnicity | 인종이 ‘HISPANIC’일 때, 혹은 민족이 ‘CENTRAL_AMERICAN’, ‘DOMINICAN’, ‘MEXICAN’, ‘PUERTO_RICAN’, ‘SOUTH_AMERICAN’에 속하면 38003563로 설정하고, 그렇지 않으면 0으로 설정한다. 어떻게 다수의 원천 열이 하나의 CDM 열에 기여할 수 있는지를 보여주는 좋은 예시이다. CDM 안에서 민족이 Hispanic이거나 not Hispanic으로 나타나진다. 그래서 원천 열 인종과 원천 열 민족 둘 다 이 값으로 결정할 것이다. |
| LOCATION_ID | ||
| PROVIDER_ID | ||
| CARE_SITE_ID | ||
| PERSON_SOURCE_ VALUE | id | |
| GENDER_SOURCE_ VALUE | gender | |
| GENDER_SOURCE_ CONCEPT_ID | ||
| RACE_SOURCE_ VALUE | race | |
| RACE_SOURCE_ CONCEPT_ID | ||
| ETHNICITY_ SOURCE_VALUE | ethnicity | 이 경우에는 ETHNICITY_SOURCE_VALUE 가 ETHNICITY_CONCEPT_ID보다 더 거칠 것이다. |
| ETHNICITY_ SOURCE_CONCEPT_ID |
Synthea 데이터의 CDM으로의 변환에 대한 더 자세한 설명은 전체 명세서를 참고하면 된다.30
6.3 2단계: 용어 매핑 생성
점점 더 많은 원천 코드가 OMOP 용어에 추가되고 있다. 이것은 CDM으로 변환된 데이터의 용어 체계가 이미 CDM에 포함되거나 매핑되었을 수도 있다는 것을 의미한다. OMOP 용어의 VOCABULARY 테이블을 통해 어떤 용어가 포함되었는지 확인할 수 있다. 비표준인 원천 용어 (예를 들어 KCD-7 codes)에서 표준용어 (예를 들어 SNOMED codes)로의 매핑을 확인하려면 CONCEPT_RELATIONSHIP 테이블 내의 relationship_id = “Maps to” 인 값을 찾으면 확인할 수 있다. 예를 들면 KCD-7 코드 ‘I21’ (“Acute Myocardial Infarction”)의 표준용어 ID를 확인하기 위해 다음과 같은 SQL을 사용할 수 있다:
SELECT concept_id_2 standard_concept_id
FROM concept_relationship
INNER JOIN concept source_concept
ON concept_id = concept_id_1
WHERE concept_code = 'I21'
AND vocabulary_id = 'KCD7'
AND relationship_id = 'Maps to';| STANDARD_CONCEPT_ID |
|---|
| 312327 |
하지만 가끔은 원천 데이터가 OMOP 용어집에 없는 용어 시스템을 사용할 수도 있다. 이러한 경우에는 원천 용어 시스템을 표준 개념으로 변환하는 매핑을 정의하여야 한다. 하지만 원천 용어 시스템에 많은 수의 용어가 있으면 용어 매핑이 어려울 수도 있다. 이를 쉽게 진행하기 위한 몇 가지 참고사항이 있다.
- 가장 높은 빈도의 코드에 집중. 절대 쓰이지 않는 용어나 거의 안 쓰이는 용어는 실제 연구에서도 쓰이지 않기 때문에 큰 노력을 들여서 매핑을 진행할 필요가 없다.
- 가능하면 기존의 정보를 활용. 예를 들어 많은 국가 약물 코딩 시스템은 이미 ATC로 매핑되어있다. 비록 ATC가 많은 목적에 대해 세부적으로 부합하지는 않지만, ATC와 RxNorm의 관계를 통해 어떤 RxNorm 코드가 사용되는지 추측할 수는 있다.
- Usagi를 사용한다.
6.3.1 Usagi
Usagi는 용어 매핑 절차를 도와주는 도구이다. Usagi는 코드 설명의 단어 유사도에 기반하여 매핑을 추천할 수 있다. 만약 원천 코드가 외국어로만 확인 가능하다면, Google Translate31를 통해 종종 해당 용어의 훌륭한 영어 번역을 확인할 수 있다. Usagi의 자동 추천이 정확하지 않을 경우 사용자가 직접 적절한 목표 개념을 찾을 수 있다. 최종적으로 사용자는 어떤 매핑이 ETL에 사용될 수 있는지 지정할 수 있다. Usagi는 GitHub32을 통해 사용할 수 있다.
범위와 목표
매핑이 필요한 원천 용어를 Usagi로 불러올 수 있다 (만약 원천 용어 시스템이 영어가 아닐 경우, 추가 번역이 필요하다). 단어 유사도 접근법은 원천 용어와 OMOP 표준 용어 개념 concept을 연결하기 위해 필요하다. 하지만 이러한 용어 매핑은 수동적으로 검토해야 하고, Usagi는 이를 수행하기 위한 인터페이스를 제공한다. Usagi는 용어에 표준 개념만을 제안한다.
절차 개요
소프트웨어를 사용하기 위한 일반적인 순서:
- 원천 시스템 (“원천 용어”)로부터 OMOP 표준 개념 standard concept으로의 매핑을 진행하고 싶은 용어를 업로드.
- Usagi 단어 유사도 접근법을 이용하여 OMOP concept으로의 매핑을 진행.
- Usagi 인터페이스를 활용하여 제안된 매핑을 확인하고 필요할 경우 개선. 용어 시스템과 의학 지식이 있는 사람이 리뷰를 진행하는 것이 바람직함.
- 매핑 결과를 용어의 SOURCE_TO_CONCEPT_MAP으로 내보냄.
6.3.1.1 Usagi로 원천 코드 가져오기
원천 시스템에서 CSV나 엑셀(.xlsx) 파일로 원천 용어를 내보낸다. 이때 파일은 원천 용어 코드와 영어로 된 설명열이 있어야 하고, 추가적인 정보 역시 더할 수 있다 (예를 들어 약물 용량, 번역되었을 경우 원래 언어로의 코드 설명). 게다가 원천 용어에 대한 정보뿐만 아니라, 빈도 역시 어떤 용어를 먼저 매핑해야 할지 정하는 데 도움이 되기 때문에 포함하는 것이 좋다 (예를 들어 1,000개의 원천 용어 중 100개만 실제 시스템에 정말로 사용되는 경우). 만약 원천 용어 설명을 영어로 번역해야 할 경우, Google Translate가 도움이 될 수 있다.
참고: 원천 용어는 도메인 (다시 말하면 약물 drug, 시술 procedure, 상태 condition, 관찰 observations) 별로 분류되어야 하며, 하나의 파일로 묶여서는 안 된다.
파일로부터 원천 코드를 Usagi로 올린다 -> 코드 메뉴를 가져온다. 여기서 “Import codes …”는 그림 6.7과 같이 보일 것이다. 이 그림에서 원천 코드 용어는 네덜란드어이고, 영어로 번역되어있다. Usagi는 표준용어로의 매핑을 위해 영어 번역을 이용할 것이다.
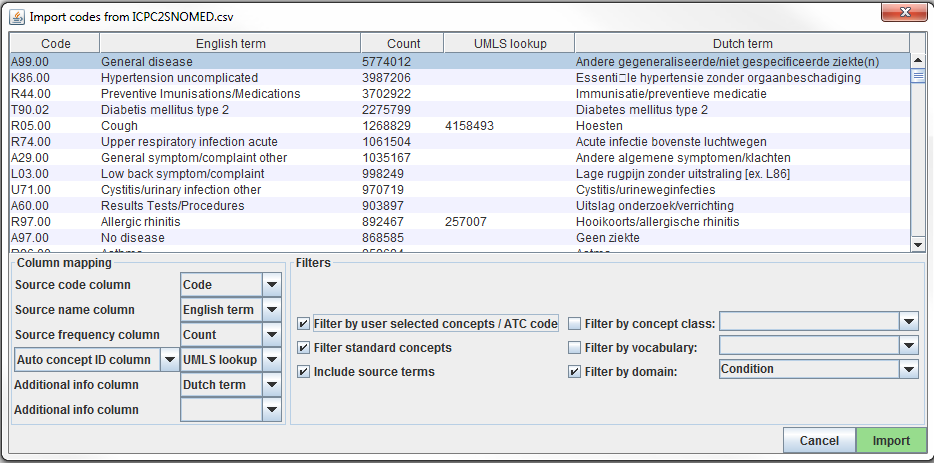
Figure 6.7: Usagi 원천 용어 코드 입력화면.
“Column mapping” 부분 (왼쪽 아래)은 Usagi가 불러온 테이블을 어떻게 사용할 것인지 정하는 단계이다. 마우스를 끌어다 놓으면, 각 열을 정의하는 팝업창이 나타날 것이다. Usagi 자체가 원천 용어를 용어 개념 Vocabulary concept 코드에 연결하는 정보로써 “Additional info” 열을 사용하지 않을 것이다. 하지만 이 추가적인 정보는 개인이 원천 코드 매핑을 검토하는 데 도움을 줄 수 있기에 포함되어야 한다.
마지막으로 “Filters” 부분 (아래 오른쪽)에서 Usagi로 매핑할 때의 몇 가지 제한을 설정할 수 있다. 예를 들어 그림 6.7에서 사용자는 Condition 도메인에만 원천 용어를 매핑하고 있다. 기본적으로 Usagi는 standard concept에만 매핑을 진행하지만, 만약 “Filter standard concepts” 옵션을 설정하지 않을 경우, Usagi는 분류 개념 classification concept 또한 검토할 것이다. 마우스를 다른 필터에 올려놓으면 해당 필터에 대한 추가적인 정보가 나타날 것이다.
한 가지 특별한 필터는 “Filter by automatically selected concepts / ATC code”이다. 만약 검색에 추가 조건을 걸어야 한다면, 자동 concept ID로 표시되는 열 (세미콜론으로 구분)에 CONCEPT_ID 목록이나 ATC 코드를 제공하면 된다. 예를 들어 약물의 경우 이미 각 약에 ATC 코드가 이미 할당되어 있을 수 있다. 비록 ATC 코드가 하나의 RxNorm 약물 코드로 인지되지 않더라도, 용어의 ATC 코드 한정으로 검색을 제한하는데 도와줄 수 있다. ATC 코드를 사용하려면 다음 절차를 따르면 된다.
- 열 매핑 부분에서, “Auto concept ID column”을 “ATC column”으로 바꾼다.
- 열 매핑 부분에서, ATC 코드가 포함된 열을 “ATC column”으로 선택한다.
- “Filter by user selected concepts / ATC code” 필터를 누른다.
또한, ATC 코드 이외의 다른 것으로도 조건을 설정할 수 있다. 위의 그림 예시에서 보이듯이 우리는 UMLS의 부분 매핑을 이용하여 Usagi의 검색을 설정하였다. 이런 경우에는 “Auto concept ID column”을 사용하여야 한다.
일단 모든 설정을 마치고 나면, “Import” 버튼을 눌러서 파일을 불러와야 한다. 파일 불러오기를 할 때 단어 유사도 알고리즘을 이용하여 원천 용어를 매핑하기 때문에 대략 몇 분 정도 소요될 수 있다.
원천 용어의 OMOP Concept으로의 매핑 검토
일단 원천 코드의 파일을 불러오면, 매핑 절차가 시작된다. 그림 6.8에서 Usagi 화면이 3가지 주요 기능으로 구분된 것을 확인할 수 있다: 개요 테이블, 선택된 매핑 테이블, 검색 기능. 이때, 오른쪽 마우스 클릭을 하여 어떤 테이블에 대해서도 열을 선택하여 숨겨서 간단히 볼 수 있다.
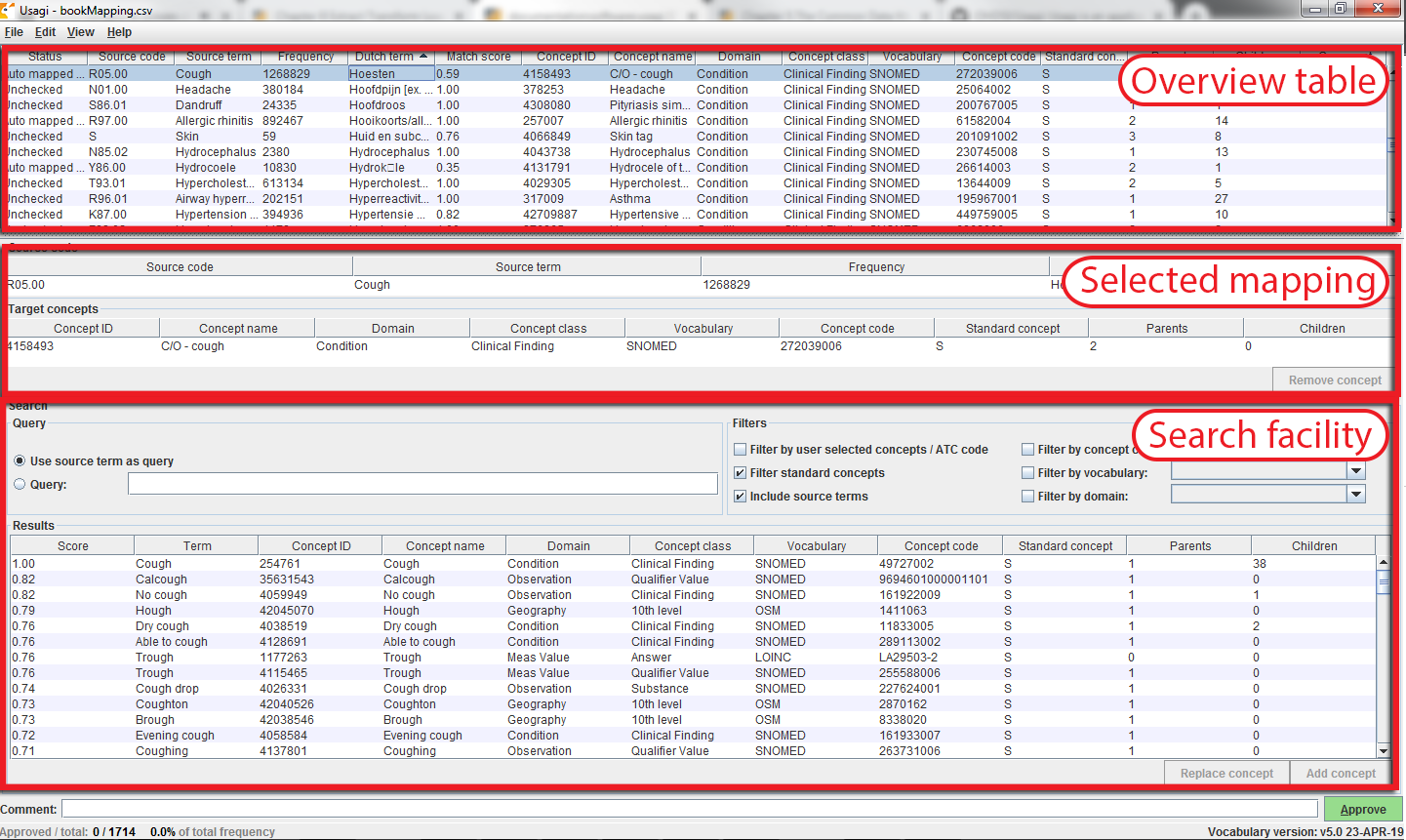
Figure 6.8: Usagi 원천 코드 입력화면.
제안된 매핑의 승인
“Overview Table”은 현재의 원천 용어의 매핑을 보여준다. 원천 용어를 불러온 직후, 검색 설정과 단어 유사도를 기반으로 자동으로 생성되어 제안된 매핑을 포함하고 있다. 그림 6.8에서 나타나듯이, 사용자가 검색 옵션을 Condition으로 설정했기에 네덜란드어 Condition 용어 코드의 영어 이름은 Condition 도메인의 표준용어로 매핑되는 것을 볼 수 있다. Usagi는 원천 코드 기술서의 concept 이름과 동의어를 비교함으로써 최적의 매칭을 수행한다. 사용자가 “Include source terms”를 선택하였기 때문에 Usagi는 용어의 특정 용어 코드로 매핑되는 모든 원천 용어 코드의 이름과 동의어까지 검토하게 된다. 만약 Usagi가 매핑을 진행할 수 없으면, CONCEPT_ID = 0으로 매핑될 것이다.
용어 시스템에 익숙한 사람이 원천 용어를 표준 용어로 매핑하는 것을 도와주는 것이 권장된다. 각 개인은 “Overview Table” 탭에서 각 코드에 대하여 Usagi가 권장하는 매핑을 받아들이거나 아니면 새로운 매핑을 선택하는 작업을 하게 된다. 예를 들어 그림 6.8에서 우리는 네덜란드어 “Hoesten”가 영어 “Cough”로 번역되는 것을 볼 수 있다. Usagi는 “Cough”를 사용하고 OMOP concept “4158493-C/O - cough”로 매핑을 한다. 이때의 매핑에 대하여 매칭 점수는 0.58 (매칭 점수는 일반적으로 0에서 1의 값을 가지며, 1이 더 신뢰할만한 매칭임) 이였고, 이는 Usagi가 이 네덜란드어 코드를 SNOMED로 매핑한 결과에 대한 확신을 가지기 어렵다는 것을 의미한다. 이 예시에서는 해당 매핑 결과에 동의하였고, 화면의 하단 우측의 “Approve” 버튼을 클릭함으로써 승인하였다.
새로운 매핑의 탐색
Usagi가 제시하는 매핑에 대하여 사용자가 새로운 매핑을 찾거나 아니면 매핑되는 concept가 없도록 (CONCEPT_ID = 0) 하는 경우도 있을 것이다. 그림 6.8의 예시를 통해 네덜란드어 “Hoesten”가 영어 “Cough”로 번역되는 것을 확인할 수 있다. Usagi의 제안은 UMLS에서 파생된 매핑으로 제한되기에, 그 결과가 적합하지 않을 수도 있다. 검색 기능을 통해서 실제 용어 자체 혹은 검색 상자 쿼리를 이용해서 다른 개념을 찾을 수 있다.
Usagi 매뉴얼 검색 상자를 이용할 때, Usagi는 구조화된 검색 쿼리를 지원하지 않고 fuzzy search를 한다는 것을 유념해야 한다. 그리고 현재까지는 AND나 OR과 같은 부울Boolean 연산자를 이용한 검색을 지원하지 않고 있다.
“Cough”에 대해서 더 나은 매핑을 찾는다고 가정해보자. 검색 기능의 오른편 쿼리 부분에 용어 검색을 할 때 결과를 정리해주는 기능을 제공하는 필터 부분이 있다. 이러면 우리는 표준 용어만을 찾아야 하며, 표준 용어에 매핑되는 코드의 이름과 동의어를 기반으로 검색할 수 있다.
이러한 검색 기준을 적용한다면 “254761-Cough”와 같은 용어 코드를 찾을 수 있으며, 이는 네덜란드어의 용어 코드 매핑에 적합한 용어일 수 있다. 이를 적용하기 위해 “Selected Source Code” 업데이트의 “Replace concept” 버튼을 누르고, “Approve” 버튼을 누르면 된다. 또한 “Add concept” 버튼이 있는데, 이는 하나의 원천 용어 코드에 대한 다수의 OMOP standard concept 매핑을 할 수 있게 해준다 (예를 들어, 일부 원천 코드는 표준 용어와는 달리 다양한 질병을 함께 포함하고 있을 수 있다).
개념 정보
적절한 개념 concept을 찾아 매핑하려 할 때, concept의 “social life”를 고려하는 것은 중요하다. concept의 의미는 계층 구조에서의 위치에 따라 부분적으로 의존적일 수 있으며, 종종 계층적 지위와 거의 혹은 전혀 상관없고 대상 concept로도 적절하지 않은 “orphan concepts”도 있다. Usagi는 각 개념에 대해 얼마나 많은 부모, 자식 개념이 있는지 알려주기도 하고, ALT + C를 누르거나 위쪽 메뉴바의 view -> Concept를 누르면 더 자세한 정보를 볼 수 있게 해준다.
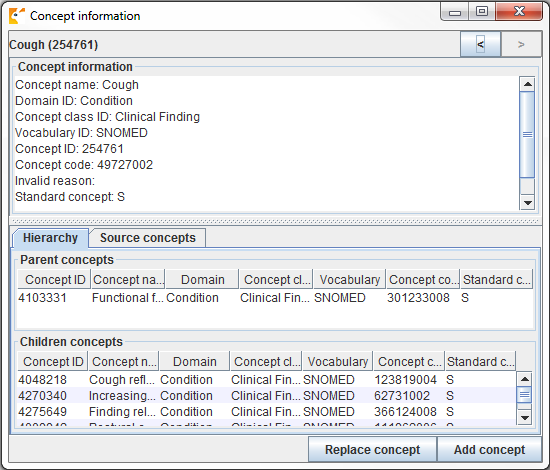
Figure 6.9: Usagi 개념 정보 패널.
그림 6.9는 concept 정보 패널을 보여준다. concept의 일반적인 정보부터, 부모, 자식, 그리고 다른 원천 용어 코드와의 정보도 보여준다. 사용자는 이 패널을 이용해서 계층 구조를 탐색할 수 있고, 다른 목표 개념을 정할 수도 있다.
모든 용어 코드 검토가 끝날 때까지 용어 코드를 따라 이 절차를 진행하면 된다. 화면의 맨 위의 원천 용어 코드 목록에서, 열 머리글별로 용어 코드를 정렬할 수 있다. 때로 최고빈도부터 최저빈도의 용어 코드까지 살펴보는 것을 권장한다. 화면의 하단 왼쪽에는 매핑을 허용한 용어 코드의 개수, 그리고 그에 따라 얼마나 많은 용어 코드가 발생했는지를 확인할 수 있다.
또한 매핑 결정에 대한 설명을 추가하여 문서화 시에 사용할 수도 있다.
모범 사례
- 코딩 스키마에 경험이 있는 사람이 해야 한다.
- “Overview Table”의 열을 열 이름을 눌러서 정렬할 수 있다. “Match Score”를 눌러서 정렬해보는 것도 좋다. Usagi가 가장 확실하게 제안하는 매핑 코드를 검토하면 많은 매핑 작업을 빠르게 끝날 수도 있다. 그리고 빈도가 높은 단어와 낮은 단어에 쓰이는 노력이 각각 다르므로 “Frequency”로 정렬해서 작업하는 것도 중요하다.
- 일부 코드를 CONCEPT_ID=0 (매핑 안 됨)으로 매핑하는 것도 허용되며, 어떤 코드는 좋은 매핑을 찾을 가치가 없어서 일 수도 있고 또는 적절한 매핑이 없어서 일 수도 있다.
- 특히 부모 계층과 자녀 계층에 대해서는 개념의 내용을 고려하는 것이 중요하다.
생성된 Usagi Map 내보내기
일단 Usagi를 통해 매핑을 생성하였으면, 이를 사용하기 가장 좋은 방법은 매핑을 내보낸 다음 용어의 SOURCE_TO_CONCEPT_MAP 테이블에 추가하는 것이다.
매핑 결과를 내보내기 위해서는, File -> Export source_to_concept_map으로 가면 된다. 이때 어느 SOURCE_VOCABULARY_ID를 이용할 것인지 묻는 팝업창이 나타나는데 짧은 식별자를 입력하면 된다. Usagi는 입력된 이 식별자를 SOURCE_TO_CONCEPT_MAP 테이블에서 특정 매핑을 식별할 수 있게 해주는 SOURCE_VOCABULARY_ID로 이용할 것이다.
SOURCE_VOCABULARY_ID를 선택한 후에는, 내보낼 CSV 파일의 이름과 파일 경로를 입력하게 된다. 내보내는 CSV 파일의 구조는 SOURCE_TO_CONCEPT_MAP 테이블과 동일하다. 이 매핑은 용어의 SOURCE_TO_CONCEPT 테이블로 추가될 수 있다. 그리고 앞선 단계에서 정의한 SOURCE_VOCABULARY_ID를 정의하는 VOCABULARY 테이블에 단일 행으로 추가하는 것 역시 가능하다. 마지막으로, “Approved” 상태인 매핑만을 CSV 파일로 내보내는 것이 중요하다; 매핑을 내보내기 위해서는 Usagi에서 매핑을 완료해야만 한다.
Usagi Map 업데이트
매핑은 종종 한 번에 끝나지 않는다. 원천 코드가 추가되는 식으로 데이터가 업데이트되거나 용어가 정기적으로 업데이트되면 매핑 또한 업데이트되어야 할 것이다.
원천 코드가 업데이트될 때는 다음과 같은 단계를 따르는 것이 좋다:
- 새로운 원천 용어 코드 파일을 불러온다.
- 파일을 고른다 -> 이전의 매핑을 적용하고, 예전의 Usagi 매핑 파일을 선택한다.
- 이전의 매핑 파일에서 매핑되지 않았던 용어 코드를 식별하고, 새롭게 매핑한다.
용어가 업데이트되면 아래의 단계를 따른다:
- Athena에서 새로운 용어 파일을 다운받는다.
- Usagi 인덱스를 다시 생성한다 (Help -> Rebuild index).
- 매핑 파일을 연다.
- 새로운 용어 버전에 따라 표준 용어가 아닌 용어 코드를 식별하여 적절한 목표 개념을 찾는다.
6.4 3단계: ETL 수행
일단 ETL 설계와 코드 매핑이 완료되면, ETL 절차는 소프트웨어를 통해 수행할 수 있다. ETL이 설계될 때, CDM과 원천 데이터 둘 다에 대해 잘 아는 사람이 참여하기를 권장한 바 있다. 마찬가지로 ETL이 수행될 때도, 데이터 (특히 빅데이터)와 ETL 수행 경험이 있는 사람이 참여하는 것이 바람직하다. 즉, 기관 외부의 기술 전문가를 고용하거나 초청하여 ETL 수행을 시키는 것이 나을 수도 있다. 또한 이 작업은 한 번에 끝나는 작업이 아니라는 점을 참고하기 바란다. 그렇기에 앞으로는 ETL 수행 및 유지에 일정 시간 이상을 할애할 수 있는 사람이나 팀이 있는 것이 좋을 것이다 (6.7절에서 더 명확히 설명할 것이다).
수행은 각 기관에 따라 다양한 양상을 보이며 특히 정보 인프라, 데이터베이스의 크기, ETL의 복잡성, 기술 전문가의 능력 등의 요소에 따라 많이 달라진다. 많은 요소에 따라 달라지기 때문에 OHDSI는 ETL을 수행하기 위한 최선의 방법에 대한 공식적인 권고를 하고 있지 않다. 그동안 많은 그룹이 SQL builders, SAS, C#, Java, Kettle을 사용해왔다. 각각 장점과 단점이 있었고, 그 어느 것도 이러한 기술에 익숙한 사람이 없으면 수행이 불가능했다.
각각 다른 ETL의 예시 (복잡성에 따라 정렬된다):
- ETL-Synthea - SQL을 이용한 Synthea 데이터베이스 변환
- https://github.com/OHDSI/etl-synthea
- ETL-CDMBuilder - 다수의 데이터베이스를 변환하기 위해 고안된 .NET application
- https://github.com/OHDSI/etl-cdmbuilder
- ETL-LambdaBuilder - AWS lamda 기능을 이용한 빌더
- https://github.com/OHDSI/etl-lambdabuilder
- ETL-Korean-National Sample Cohort - R과 SQL을 이용한 데이터베이스 변환
- https://github.com/OHDSI/ETL—Korean-NSC
그동안 많은 시도가 있었지만, ‘최종적’인 사용자 친화적 ETL 도구를 개발하지는 못했다. 항상 이러한 도구는 ETL 작업의 80%까지는 잘 수행하지만, 남은 20%에 있어서는 원천 데이터베이스에 따라 인프라 단에서의 코드 작성이 필요하다.
일단 기술 전문가가 수행할 준비가 된다면, ETL 설계 문서를 공유해야만 한다.문서에는 수행을 시작할만한 충분한 정보가 있어야 하지만, 개발자가 개발 과정 중에 ETL 설계자에게 언제나 질문할 수 있는 환경 역시 마련되어 있어야 한다. ETL 설계자에게는 로직이 명확해 보일지라도 CDM이나 데이터에 친숙하지 않은 수행자에게는 명확하지 않아 보일 수도 있다. 그렇기에 실행 단계는 팀 단위로 수행되어야 한다. 설계자와 수행자 모두 로직이 올바르게 작동한다고 동의할 때까지, 모두 CDM 생성과 검증을 같이 수행하는 것이 바람직하다.
6.5 4단계: 질 관리
ETL 절차 수행을 위해서 질 관리는 반복적으로 수행된다. 질 관리의 전형적인 패턴은 로직 작성 -> 로직 수행 -> 로직 검증 -> 로직 수정 및 작성이다. CDM을 검증하기 위한 많은 방법이 있지만, 아래의 단계는 몇 년간의 ETL 수행을 통해 OHDSI 내부에서 권고하는 단계이다.
- ETL 설계 문서, 컴퓨터 코드, 용어 매핑을 검토하라. 누구라도 실수를 할 수 있기 때문에, 항상 한 명 이상이 다른 사람이 어떤 작업을 수행하고 있는지 검토해야 한다.
- ETL 상의 가장 큰 문제점은 원천 데이터의 원천 용어 코드가 표준 용어에 어떻게 매핑되었는지와 관련된다. 특히 NDC처럼 날짜에 따라 유효 코드가 바뀌는 코드가 원천 용어 코드라면 이는 더욱 어려울 수 있다. 원천 용어가 항상 적절한 개념으로 변환되도록 매핑이 수행되는 부분을 두 번씩 봐야 한다.
- 원천 데이터와 목표 데이터의 표본으로써 특정한 한 사람의 모든 정보를 수작업으로 비교하라.
- 여러 개의 기록을 가진 한 사람의 데이터를 살펴보는 것이 큰 도움이 될 수 있다. 한 사람의 기록을 추적함으로써 CDM 데이터가 로직에 따라 기대했던 결과와 다른 경우를 발견해낼 수도 있다.
- 원천 데이터와 목표 데이터의 전체 수를 비교하라.
- 특정 문제를 어떻게 해결하는지 설명하기에 따라 몇 가지 차이점이 있을 수 있다. 예를 들면, 연구자에 따라 성별이 NULL로 기록된 사람을 어차피 연구에 포함되지 않기 때문에 삭제하기로 할 수도 있다. 그리고 CDM에서의 방문이나 원천 데이터에서의 방문이 다르게 구성될 수도 있다. 따라서 CDM과 원천 데이터의 총합을 비교할 때는 이러한 차이점이 발생할 수 있다는 것을 예상하고 설명할 수 있어야 한다.
- 해당 CDM 버전에서 원천 데이터에 대해 이미 수행된 기존의 연구를 재현해 보라.
- 비록 시간이 많이 들겠지만, 원천 데이터와 CDM 버전에 따른 차이점을 확인하기에 좋은 방법이다.
- ETL에서 다뤄야 하는 원천 데이터의 패턴을 따라 하기 위한 단위 검정 unit test을 작성하라. 예를 들어 만약 ETL 명세에서 성별 정보가 없는 환자를 없애야 한다고 명시한다면, 성별이 없는 환자에 대한 단위 검정을 작성하고 수행자가 처리하는 방안을 평가하라.
- 단위 검정은 ETL 변환의 정확도와 질을 평가하기 위한 편리한 방법이다. 보통은 변환하고자 하는 원천 데이터의 작은 표본을 사용한다. 데이터 세트의 각 사람이나 기록은 ETL 문서에 기록된 대로 로직의 특정 부분으로 검정해야 한다. 이 방법을 쓴다면 문제를 파악하거나 로직 실패를 확인하기에 좋다. 작은 사이즈의 데이터로 테스트하는 것은 컴퓨터 코드 구동도 훨씬 빠르고 여러 번 시행하기에도 좋고 에러를 빨리 확인하는데에도 좋다.
ETL의 관점에서 고차원의 질 관리 접근법도 있다. 데이터 질 관리에 대한 더 구체적인 노력은 OHDSI에서 진행되고 있으며, 15장을 확인해주기 바란다.
6.6 ETL 협약 convention과 테미스 THEMIS
많은 그룹이 데이터를 CDM으로 변환함에 따라 구체적인 협약 convention의 필요성이 명확해졌다. 예를 들어 만약 한 사람의 기록에서 출생연도가 없으면 ETL은 어떻게 할 것인가? CDM의 목적은 보건의료 데이터의 표준화이지만 만약 모든 그룹이 데이터의 특정 시나리오를 각각 다르게 다룬다면 네트워크를 통해 체계적으로 데이터를 다루는 것이 더욱 어려워질 것이다.
OHDSI 공동체는 CDM의 일관성을 증진하기 위해 협약 문서 작성을 시작하였다. OHDSI가 동의하는 이러한 협약의 정의에 대해서는 CDM wiki를 통해 확인할 수 있다.33 각 CDM 테이블은 ETL 설계 시 참고할 수 있는 고유의 협약을 맺고 있다. ETL을 설계할 때 이 협약을 참고한다면 어떤 설계에 대한 결정 시에 커뮤니티와 동일한 일관성을 유지할 수 있도록 도와줄 것이다.
발생 가능한 모든 데이터 시나리오에 대해서 어떻게 다뤄야 할지에 대한 문서를 작성하는 것은 불가능하지만, OHDSI 워크 그룹을 통해 공통적인 시나리오를 문서화하는 것은 가능하다. THEMIS34는 협약을 모으고, 명시하고, 공동체에 조언을 나눈 다음, 마지막으로 CDM wiki에 완성된 문서를 공개하는 일을 하는 각 개인으로 구성되어 있다. Themis는 고대 그리스의 질서, 공정함, 법, 자연법, 관습을 관장하는 티타니스로 이 그룹의 이름으로 정했다. ETL을 수행할 때, 만약 특정 시나리오에 대해 어떻게 할지 모르겠다면, THEMIS 워크그룹은 OHDSI 포럼에 질문을 남기기를 권장한다.35 대부분의 경우 질문은 커뮤니티의 다른 사람 역시 고민하고 있는 문제일 가능성이 높다. THEMIS는 이런 토론과 워크그룹 미팅과 대면 토론을 통하여 어떤 협약이 문서화될 필요가 있는지 알려준다.
6.7 CDM과 ETL의 유지
ETL을 설계하고, 매핑을 만들고, ETL을 수행하고, 질 관리 검증을 만들기는 절대 쉽지 않다. 안타깝게도 그게 다가 아니다. 첫 번째 CDM이 만들어진 후 지속해서 이어지는 ETL 유지 과정이 있다. 유지를 요구하는 몇몇 공통되는 계기는 다음과 같다: 원천 데이터의 변화, ETL 상의 오류, 새로운 OMOP 용어의 출시, CDM 자체의 변화 혹은 업데이트 등이 있다. 만약 이 중 하나라도 발생한다면, 다음 사항에 대한 업데이트가 필요하다 : ETL 문서, ETL을 수행한 소프트웨어 프로그래밍, 그리고 예시 검정과 질 관리
보건의료 데이터는 보통 계속 바뀐다. 새로운 데이터의 출시 (예를 들어 데이터에 새로운 열의 추가), 기존에 존재하지 않았던 새로운 환자 시나리오의 발생 (예를 들어 출생 전에 사망이 기록되어있는 새로운 환자), 데이터에 대한 이해도의 상승 (예를 들어 입원 아동 환자의 출생 기록이 청구 과정으로 인해 외래에서 발견). 원천 데이터의 모든 변경 사항에 대해서는 아니지만, 최소한 ETL 절차를 망가뜨리는 변경 사항은 해결해야만 할 것이다.
만약 오류가 발견된다면 역시 해결해야 할 것이다. 하지만 모든 오류가 중요하지는 않다. 예를 들어 COST 테이블에서 비용이 한 자릿수에서 반올림되었다고 가정해보자 (원천 데이터에서 $3.82가 CDM에서는 $4.00이 됨). 만약 이 데이터를 사용하는 주요 연구자가 환자 약물 노출과 진단에 대한 특성을 주로 연구한다면, 이는 별로 중요하지 않으며 향후 해결하면 된다. 만약 이 데이터를 사용하는 주요 연구자 중 보건경제학자가 있다면 이는 즉시 해결해야 하는 주요 문제가 될 것이다.
OMOP 용어집 역시 원천 데이터처럼 지속해서 변화한다. 사실 용어집은 용어가 계속 업데이트됨에 따라 한 달 안에도 여러 개의 버전을 가질 수 있다. 각 CDM은 특정 용어집 개별 버전 기반으로 운영되며, 용어집 새 버전에서 작동할 때 원천 용어 코드가 표준 용어로의 매핑 정도에 따라 다른 결과를 만들 수도 있다. 용어집 간의 차이는 미미할 수도 있지만, 용어집이 개정될 때마다 CDM을 새로 만드는 것은 불필요하다. 하지만, 일 년에 한두 번 정도 새로 출시된 용어집은 기반으로 CDM을 재가공하는 것은 유익할 수 있다. ETL 코드 자체를 새로 업데이트해야 할 정도로 새로운 버전의 용어집이 나오는 일은 매우 드물다.
CDM 또는 ETL 업데이트를 하게끔 하는 마지막 계기는 공통 데이터 모델 자체의 업데이트이다. 공동체가 커짐에 따라 새로운 데이터의 필요성이 커지고, 이는 CDM에 새로운 데이터를 추가할 수 있는 방향으로 가게 된다. 이는 이전의 CDM에 없었던 데이터가 새로운 버전의 CDM에 들어갈 수 있는 것을 의미한다. CDM 구조의 변화는 잘 생기지 않지만, 충분히 가능한 일이다. 예를 들어 CDM은 DATE 필드 대신 DATETIME 필드를 필수 컬럼으로 정의하였고, 이는 ETL 절차에서 에러를 발생시킬 수 있는 일이다. 하지만, CDM 버전은 자주 출시되지 않으며, 각 기관은 데이터를 언제 업데이트할 지 결정할 수 있다.
6.8 ETL에 대한 마지막 생각
ETL 절차는 여러 가지 이유로 완전히 통달하기 어려운 절차이다. 각자가 서로 다른 고유한 원천 데이터를 다루기 때문에 “만능열쇠”를 만드는 것은 어렵다. 하지만, 수년간 시도에서 배운 몇 가지 교훈이 있다.
- 80/20 규칙. 피할 수만 있다면 너무 많은 시간을 원천 용어 코드를 OMOP standard concept으로 수동 매핑하는데 할애하지 말기 바란다. 전체 데이터양의 대부분을 차지하는 원천 용어코드 위주로 매핑하는 것이 이상적이다. 그것만으로도 시작하기에 충분할 것이고, 실제 사용 예시에 기반하여 나머지 남은 코드도 다룰 수 있다.
- 연구 품질에 맞지 않는 데이터를 잃어버리는 것은 괜찮다. 이런 기록은 분석을 시작하기 전에 결국은 버려지게 되고, 우리는 대신 ETL 절차에서 미리 삭제할 뿐이다.
- CDM은 지속적인 유지를 필요로 한다. 단순히 ETL을 완료했다고, 두 번 다시 손대지 않는 것을 의미하는 것이 아니다. 원천 데이터는 변할 수도 있고, 코드에 오류가 있을 수도 있고, 새로운 용어가 나오거나 CDM 버전의 업데이트가 있을 수 있다. 이러한 변화에 대비하고 ETL을 최신 상태로 유지하기 위해 자원을 할당할 필요가 있다.
- OHDSI CDM으로 시작하는 것을 돕고, 데이터베이스의 변환을 수행하거나 분석 도구를 사용하기 위해 Implementers Forum에 방문해주길 바란다.36
6.9 요약
- ETL에 접근하는 방법에 대해 일반적으로 합의된 절차가 있는데 다음과 같다.
- 데이터 전문가와 CDM 전문가가 함께 ETL을 설계한다.
- 의료 지식이 있는 사람이 용어 코드 매핑을 진행한다.
- 엔지니어가 ETL을 수행한다.
모든 사람이 질 관리에 참여한다.
이러한 단계를 돕기 위해 OHDSI 공동체에서 무료로 사용 가능한 도구를 개발하였다.
- 많은 ETL 예시가 있으며, 가이드로 삼을만한 협약이 있다.
6.10 예제
Exercise 6.1 다음 ETL 절차를 올바른 단계로 정렬하라:
- 데이터 전문가와 CDM 전문가가 함께 ETL을 설계한다.
- 기술 전문가가 ETL을 수행한다.
- 의료 지식이 있는 사람이 코드 매핑을 진행한다.
- 모든 사람이 질 관리에 참여한다.
Exercise 6.2 선택한 OHDSI 자원을 활용하여, 테이블 6.2의 PERSON 기록에서 나타나는 4가지 문제를 발견하라 (공간상 축약된 형태의 표):
| Column | Value |
|---|---|
| PERSON_ID | A123B456 |
| GENDER_CONCEPT_ID | 8532 |
| YEAR_OF_BIRTH | NULL |
| MONTH_OF_BIRTH | NULL |
| DAY_OF_BIRTH | NULL |
| RACE_CONCEPT_ID | 0 |
| ETHNICITY_CONCEPT_ID | 8527 |
| PERSON_SOURCE_VALUE | A123B456 |
| GENDER_SOURCE_VALUE | F |
| RACE_SOURCE_VALUE | WHITE |
| ETHNICITY_SOURCE_VALUE | NONE PROVIDED |
Exercise 6.3 VISIT_OCCURRENCE 기록을 만들어보자. Synthea에 대한 예시 로직이 다음과 같이 있다: PATIENT, START, END에 따라 오름차순으로 데이터를 정렬하라. 그다음 PERSON_ID 별로, 하나의 기록의 END 시간과 다음 기록의 START 시간의 차이가 1일 이하인 기록을 하나로 만들어 준다. 각 통합된 입원 환자 기록은 하나의 입원 환자 방문으로 간주하며, 다음과 같이 설정한다:
- MIN(START) as VISIT_START_DATE
- MAX(END) as VISIT_END_DATE
- “IP” as PLACE_OF_SERVICE_SOURCE_VALUE
만약 아래와 같은 그림 6.10의 방문 기록이 원천 데이터라고 가정한다면, CDM에서의 VISIT_OCCURRENCE 기록은 어떻게 보일 것인가?

Figure 6.10: 원천 데이터 예시.
제안된 답변은 부록 E.3에서 확인할 수 있다.
SyntheaTM is a patient generator that aims to model real patients. Data are created based on parameters passed to the application.The structure of the data can be found here: https://github.com/synthetichealth/synthea/wiki.↩